随着Sora、diffusion、GPT等模型的大火,深度生成模型又成为了大家的焦点。
深度生成模型是一类强大的机器学习工具,它可以从输入数据学习其潜在的分布,进而生成与训练数据相似的新的样本数据,它在计算机视觉、密度估计、自然语言和语音识别等领域得到成功应用, 并给无监督学习提供了良好的范式。
本文汇总了常用的深度学习模型,
深入介绍
其原理及应用:
VAE(变分自编码器)、GAN(生成对抗网络)、AR(自回归模型 如transformer)、Flow(流模型)和Diffusion(扩散模型)
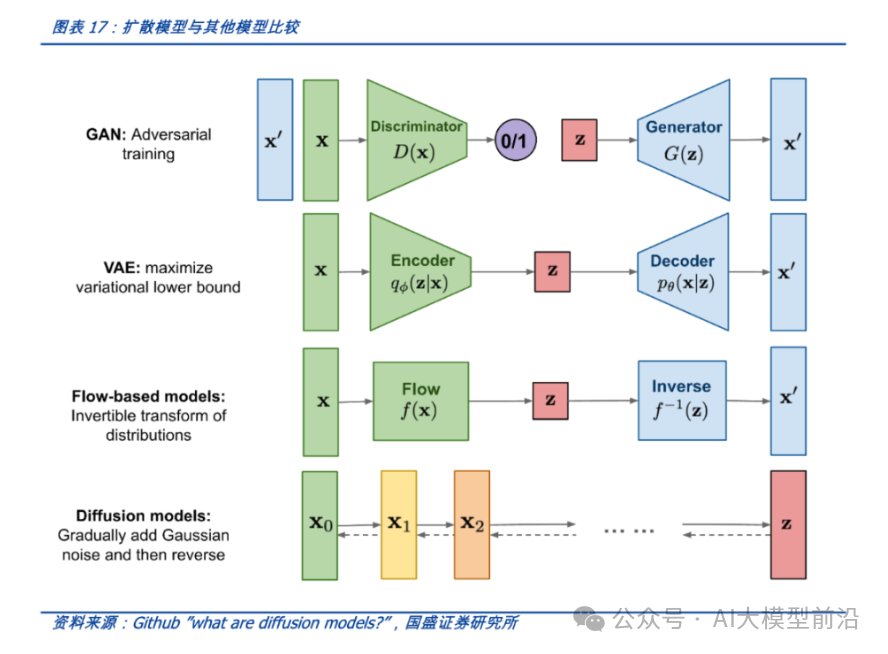
VAE(变分自编码器)
算法原理
:
VAE是在自编码器(Autoencoder)的基础上,结合变分推断(Variational Inference)和贝叶斯理论提出的一种深度生成模型。VAE的目标是学习一个能够生成与训练数据相似样本的模型。它假设隐变量服从某种先验分布(如标准正态分布),并通过编码器将输入数据映射到隐变量的后验分布,再通过解码器将隐变量还原成生成样本。VAE的训练涉及到重构误差和KL散度两个部分的优化。
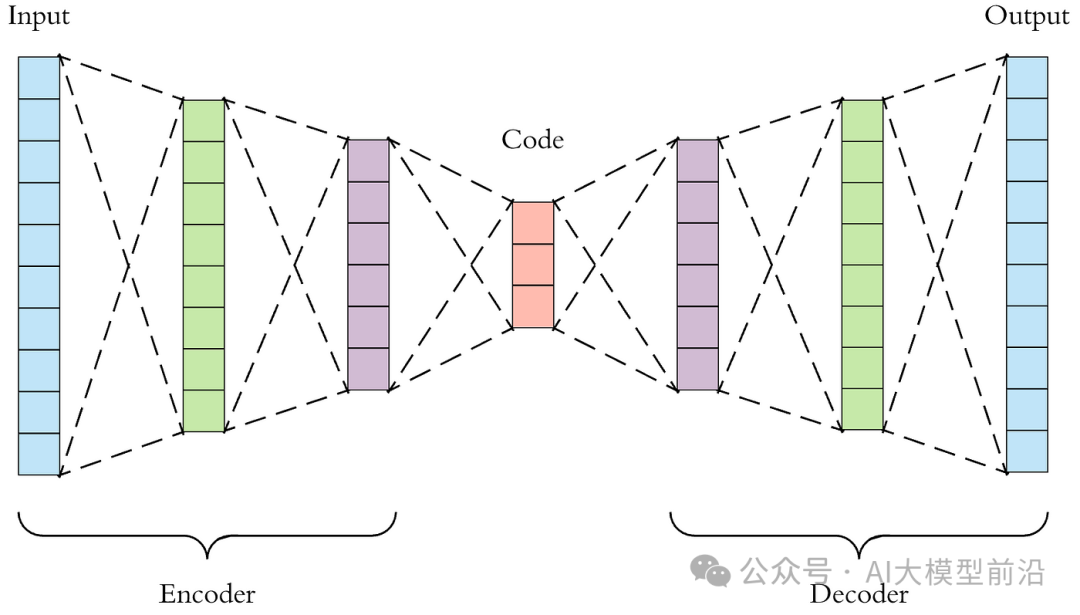
训练过程
:
-
编码器:将输入数据x编码为隐变量z的均值μ和标准差σ。
-
采样:从标准正态分布中采样一个ε,通过μ和σ计算z = μ + ε * σ。
-
解码器:将z解码为生成样本x'。
-
计算重构误差(如MSE)和KL散度,并优化模型参数以最小化两者的和。
优点
:
-
能够生成多样化的样本。
-
隐变量具有明确的概率解释。
缺点
:
-
训练过程可能不稳定。
-
生成样本的质量可能不如其他模型。
适用场景
:
Python示例代码
(使用PyTorch实现):
Python
import torchimport torch.nn as nnimport torch.optim as optim
class VAE(nn.Module): def __init__(self, input_dim, hidden_dim): super(VAE, self).__init__() self.encoder = nn.Sequential( nn.Linear(input_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 2 * hidden_dim) ) self.decoder = nn.Sequential( nn.Linear(hidden_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, input_dim), nn.Sigmoid() )
def reparameterize(self, mu, logvar): std = torch.exp(0.5 * logvar) eps = torch.randn_like(std) return mu + eps * std
def forward(self, x): h = self.encoder(x) mu, logvar = h.chunk(2, dim=-1) z = self.reparameterize(mu, logvar) x_recon = self.decoder(z) return x_recon, mu, logvar
model = VAE(input_dim=784, hidden_dim=400)optimizer = optim.Adam(model.parameters(), lr=1e-3)
x = torch.randn(batch_size, 784)recon_x, mu, logvar = model(x)loss = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum') \ + 0.5 * torch.sum(torch.exp(logvar) + mu.pow(2) - 1 - logvar)
optimizer.zero_grad()loss.backward()optimizer.step()
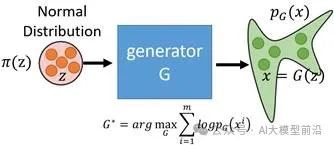
GAN(生成对抗网络)
算法原理
:
GAN由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器的任务是生成尽可能接近真实数据的假数据,而判别器的任务是区分输入数据是真实数据还是生成器生成的假数据。二者通过相互竞争与对抗,共同进化,最终生成器能够生成非常接近真实数据的样本。
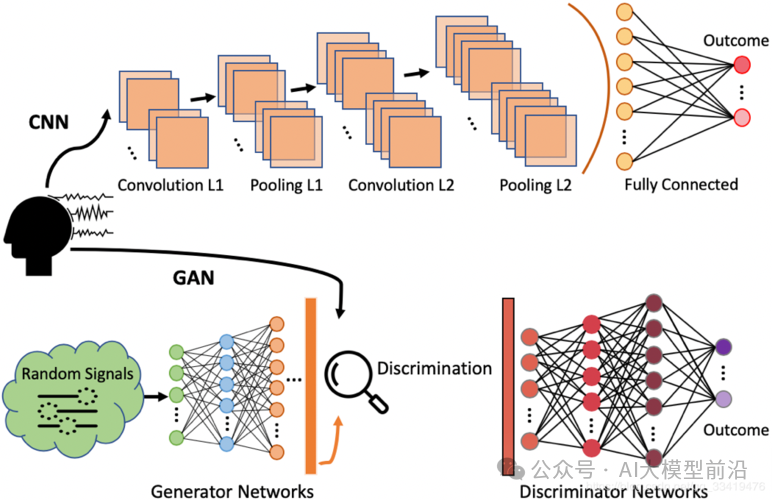
训练过程
:
-
判别器接受真实数据和生成器生成的假数据,进行二分类训练,优化其判断真实或生成数据的能力。
-
生成器根据判别器的反馈,尝试生成更加真实的假数据以欺骗判别器。
-
交替训练判别器和生成器,直到判别器无法区分真实和生成数据,或达到预设的训练轮数。
优点
:
-
能够生成高质量的样本。
-
训练过程相对自由,不受数据分布限制。
缺点
:
-
训练不稳定,容易陷入局部最优。
-
需要大量的计算资源。
适用场景
:
Python示例代码
(使用PyTorch实现):
Python
import torchimport torch.nn as nnimport torch.optim as optim
class Discriminator(nn.Module): def __init__(self, input_dim): super(Discriminator, self).__init__() self.fc = nn.Sequential( nn.Linear(input_dim, 128), nn.LeakyReLU(0.2), nn.Linear(128, 1), nn.Sigmoid() )
def forward(self, x): return self.fc(x)
class Generator(nn.Module): def __init__(self, input_dim, output_dim): super(Generator, self).__init__() self.fc = nn.Sequential( nn.Linear(input_dim, 128), nn.ReLU(), nn.Linear(128, output_dim), nn.Tanh() )
def forward(self, x): return self.fc(x)
discriminator = Discriminator(input_dim=784)generator = Generator(input_dim=100, output_dim=784)optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002)optimizer_G = optim.Adam(generator.parameters(), lr=0.0002)criterion = nn.BCEWithLogitsLoss()
real_data = torch.randn(batch_size, 784)
for p in discriminator.parameters(): p.requires_grad = Truefor p in generator.parameters(): p.requires_grad = False
noise = torch.randn(batch_size, 100)fake_data = generator(noise)real_loss = criterion(discriminator(real_data), torch.ones_like(real_data))fake_loss = criterion(discriminator(fake_data.detach()), torch.zeros_like(real_data))discriminator_loss = real_loss + fake_lossoptimizer_D.zero_grad()discriminator_loss.backward()optimizer_D.step()
for p in discriminator.parameters(): p.requires_grad = Falsefor p in generator.parameters(): p.requires_grad = True
noise = torch.randn(batch_size, 100)fake_data = generator(noise)gen_loss = criterion(discriminator(fake_data), torch.ones_like(real_data))optimizer_G.zero_grad()gen_loss.backward()optimizer_G.step()
AR(自回归模型)
算法原理
:自回归模型是一种基于序列数据的生成模型,它通过预测序列中下一个元素的值来生成数据。给定一个序列(x_1, x_2, ..., x_n),自回归模型试图学习条件概率分布(P(x_t | x_{t-1}, ..., x_1)),其中(t)表示序列的当前位置。AR模型可以通过循环神经网络(RNN)或Transformer等结构实现。如下以Transformer为例解析。
在深度学习的早期阶段,卷积神经网络(CNN)在图像识别和自然语言处理领域取得了显著的成功。然而,随着任务复杂度的增加,序列到序列(Seq2Seq)模型和循环神经网络(RNN)成为处理序列数据的常用方法。尽管RNN及其变体在某些任务上表现良好,但它们在处理长序列时容易遇到梯度消失和模型退化问题。为了解决这些问题,Transformer模型被提出。
而后的GPT、Bert等大模型都是基于Transformer实现了卓越的性能!
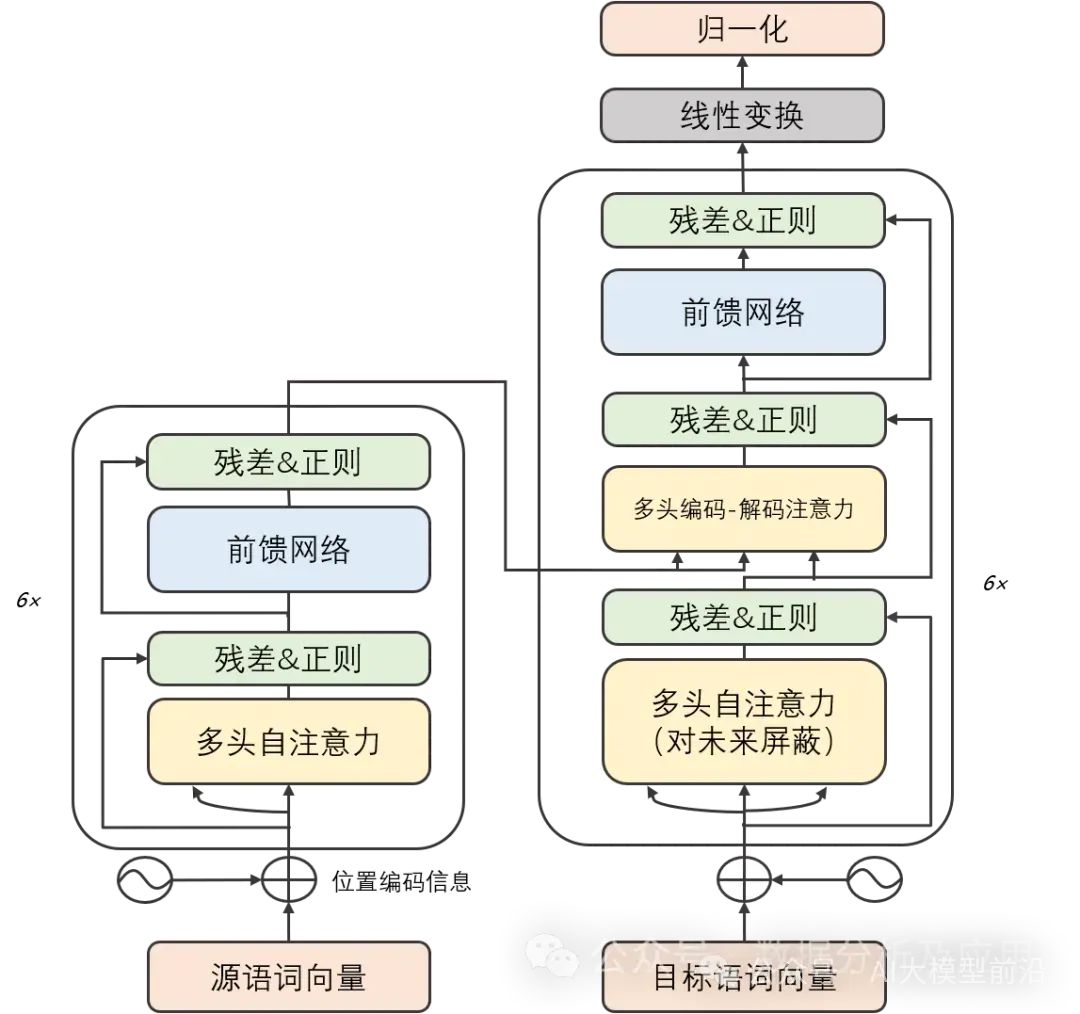
模型原理:
Transformer模型精巧地结合了编码器和解码器两大部分,每一部分均由若干相同构造的“层”堆叠而成。这些层巧妙地将自注意力子层与线性前馈神经网络子层结合在一起。自注意力子层巧妙地运用点积注意力机制,为每个位置的输入序列编织独特的表示,而线性前馈神经网络子层则汲取自注意力层的智慧,产出富含信息的输出表示。值得一提的是,编码器和解码器各自装备了一个位置编码层,专门捕捉输入序列中的位置脉络。
模型训练:
Transformer模型的修炼之道依赖于反向传播算法和优化算法,如随机梯度下降。在修炼过程中,它细致地计算损失函数对权重的梯度,并运用优化算法微调这些权重,以追求损失函数的最小化。为了加速修炼进度和提高模型的通用能力,修炼者们还常常采纳正则化技术、集成学习等策略。
优点:
-
梯度消失与模型退化之困得以解决:Transformer模型凭借其独特的自注意力机制,能够游刃有余地捕捉序列中的长期依赖关系,从而摆脱了梯度消失和模型退化的桎梏。
-
并行计算能力卓越:Transformer模型的计算架构具备天然的并行性,使得在GPU上能够风驰电掣地进行训练和推断。
-
多任务表现出色:凭借强大的特征学习和表示能力,Transformer模型在机器翻译、文本分类、语音识别等多项任务中展现了卓越的性能。
缺点:
-
计算资源需求庞大:由于Transformer模型的计算可并行性,训练和推断过程需要庞大的计算资源支持。
-
对初始化权重敏感:Transformer模型对初始化权重的选择极为挑剔,不当的初始化可能导致训练过程不稳定或出现过拟合问题。
-
长期依赖关系处理受限:尽管Transformer模型已有效解决梯度消失和模型退化问题,但在处理超长序列时仍面临挑战。
应用场景:
Transformer模型在自然语言处理领域的应用可谓广泛,涵盖机器翻译、文本分类、文本生成等诸多方面。此外,Transformer模型还在图像识别、语音识别等领域大放异彩。
Python示例代码
:
import torchimport torch.nn as nnimport torch.optim as optimclass Transformer(nn.Module): def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward=2048): super(Transformer, self).__init__() self.model_type = 'Transformer'
self.src_mask = None self.pos_encoder = PositionalEncoding(d_model, max_len=5000) encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward) self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_encoder_layers)
decoder_layers = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward) self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers)
self.decoder = nn.Linear(d_model, d_model)
self.init_weights()
def init_weights(self): initrange = 0.1 self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, tgt, teacher_forcing_ratio=0.5): batch_size = tgt.size(0) tgt_len = tgt.size(1) tgt_vocab_size = self.decoder.out_features
src = self.pos_encoder(src) output = self.transformer_encoder(src)
target_input = tgt[:, :-1].contiguous() target_input = target_input.view(batch_size * tgt_len, -1) target_input = torch.autograd.Variable(target_input)
output2 = self.transformer_decoder(target_input, output) output2 = output2.view(batch_size, tgt_len, -1)
prediction = self.decoder(output2) prediction = prediction.view(batch_size * tgt_len, tgt_vocab_size)
return prediction[:, -1], prediction
class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=5000): super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1).float() div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(torch.log(torch.tensor(10000.0)) / d_model)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) self.register_buffer('pe', pe)
def forward(self, x): x = x + self.pe[:, :x.size(1)] return x
d_model = 512nhead = 8num_encoder_layers = 6num_decoder_layers = 6dim_feedforward = 2048
model = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)
src = torch.randn(10, 32, 512)tgt = torch.randn(10, 32, 512)
prediction, predictions = model(src, tgt)
print(prediction)
Flow(流模型)
算法原理
:流模型是一种基于可逆变换的深度生成模型。它通过一系列可逆的变换,将简单分布(如均匀分布或正态分布)转换为复杂的数据分布。
训练过程
:在训练阶段,流模型通过最小化潜在空间中的样本与真实数据之间的损失函数来学习可逆变换的参数。
优点
:
-
可以高效地进行样本生成和密度估计。
-
具有可逆性,便于反向传播和优化。
缺点
:
适用场景
:流模型适用于图像生成、音频生成和密度估计等任务。
Python示例代码
:
Pythonimport torchimport torch.nn as nn
class FlowModel(nn.Module): def










