CES大会上,老黄称,「AI下一个前沿就是物理AI」。
为此,英伟达重磅官宣了世界基础模型开发平台——Cosmos,其模型基于在200万小时视频上完成训练。
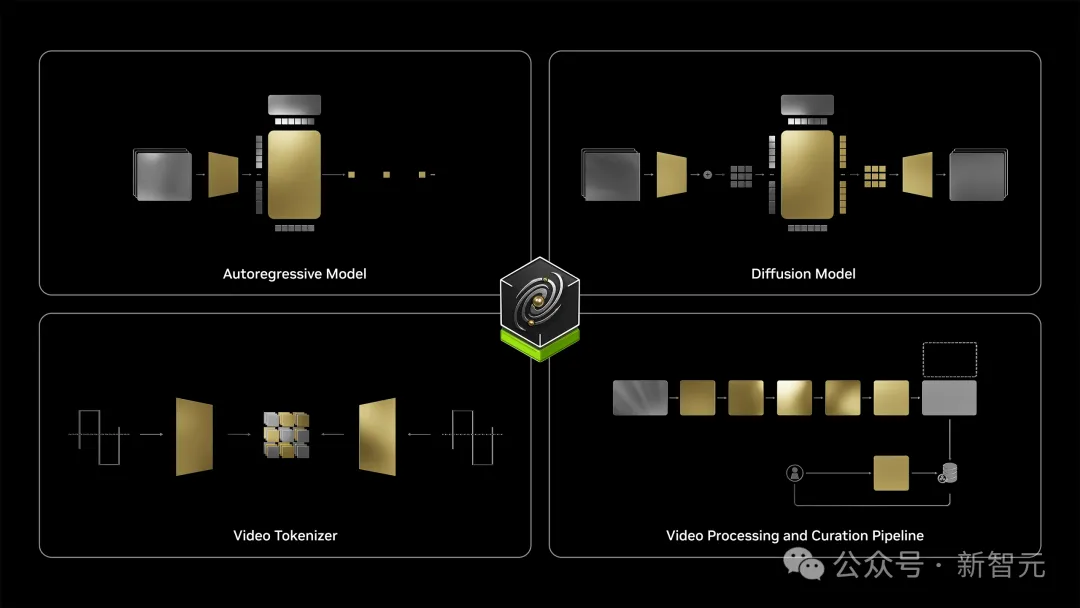
它一共包含了四大功能模块:扩散模型、自回归模型、视频分词器,以及视频处理与编辑流程。
用英伟达高级科学家Jim Fan的话来总结:

Cosmos诞生就是为了拯救物理AI数据不够的问题!现如今,开发者们可以直接生成合成数据,将其用于自动驾驶和机器人研究中。
它一共包含了三种规格的模型:Nano、Super、Ultra。
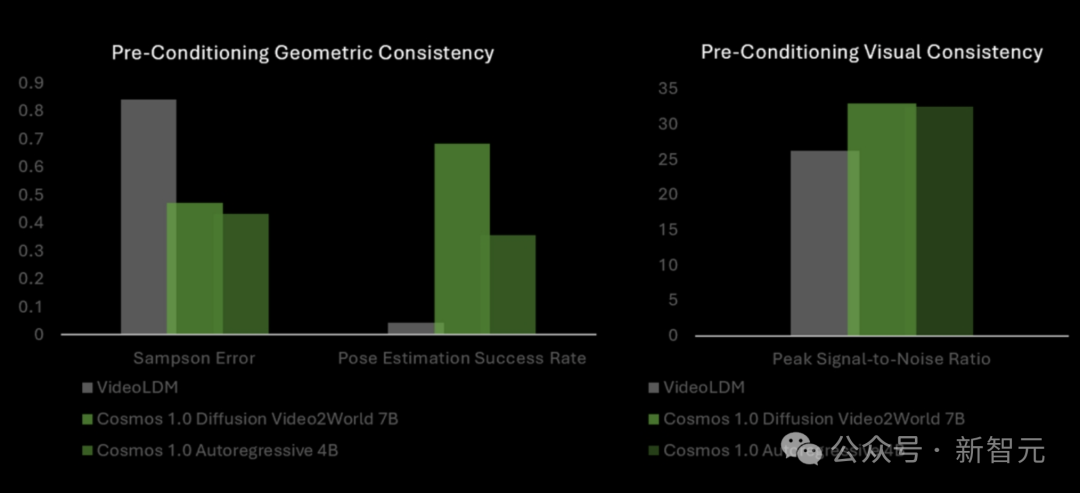
与VideoLDM基准相比,Cosmos世界模型在几何准确性方面表现更优,而且在视觉一致性方面持续超越VLDM,姿态估计成功率最高飙升14倍。

GitHub项目仅开源不到一天的时间,星标飙升至2k。
与此同时,关于Cosmos 75页最详细的技术报告也发布了。
开源项目:https://github.com/NVIDIA/Cosmos
论文地址:https://research.nvidia.com/publication/2025-01_cosmos-world-foundation-model-platform-physical-ai
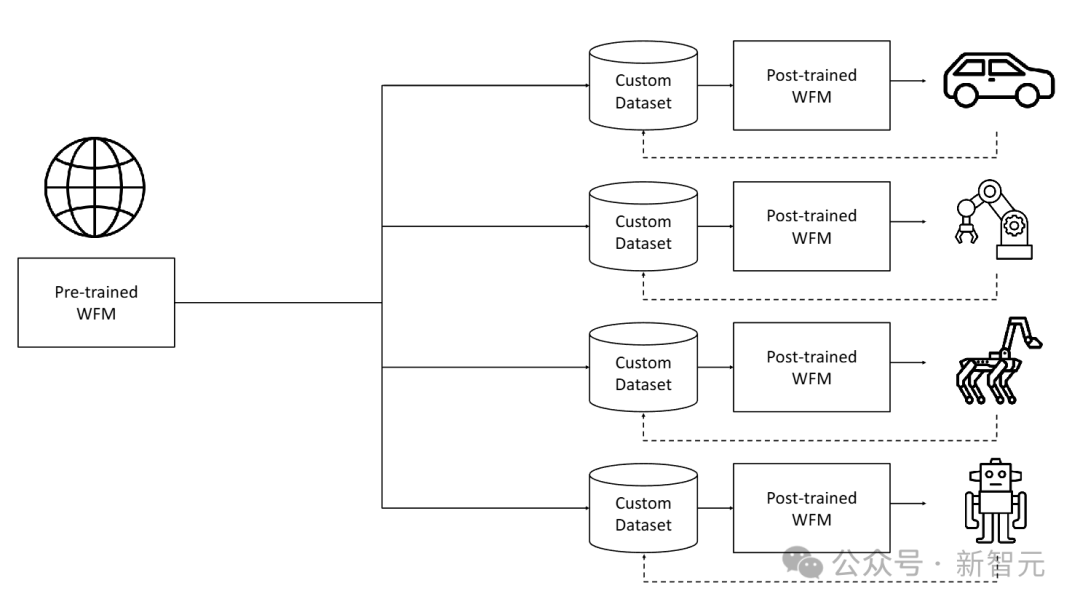
本文介绍了Cosmos世界基础模型平台,旨在帮助开发者构建定制化的世界模型。
在预训练中,研究者利用大规模的视频数据集,让模型接触到多样化的视觉数据,训练一个通用型模型。预训练的Cosmos世界基础模型(WFM)能够生成高质量、具有一致性的3D视频。

在后训练中,研究者从特定环境收集数据集,对预训练模型进行微调,从而得到适用于特定目标的专用WFM。


预训练的世界基础模型(WFM)是通用的世界模型,通过大规模、多样化的视频数据集进行训练。后训练的数据集是从目标环境中收集的提示-视频对。提示可以是动作指令、轨迹、说明等形式。
预训练和后训练相结合策略为构建物理AI系统提供了一种高效的方法。由于预训练WFM提供了良好的基础,后训练的数据集可以相对较小。
世界基础模型平台
设𝑥_0:𝑡为从时间0到𝑡的真实世界视觉观测序列。
设𝑐为对世界的扰动。如图3所示,WFM是一种模型𝒲,它根据过去的观测𝑥_0:𝑡和当前扰动𝑐𝑡,预测时间𝑡+1的未来观测值 。
。
在本案例中,𝑥_0:𝑡是一个RGB视频(即彩色图像视频),而𝑐𝑡是可以采取多种形式的扰动。例如,物理AI的动作、随机扰动或描述扰动的文本等。
世界基础模型(WFM)𝒲是一种模型,它根据过去的观测𝑥_0:𝑡和当前扰动𝑐𝑡生成世界的未来状态𝑥_𝑡+1
视频编辑
研究者开发了一条可扩展的视频数据编辑流程。
其中,每段视频被分割为无场景变化的独立镜头。通过过滤步骤定位高质量、动态且信息丰富的片段用于训练。
这些高质量镜头随后通过VLM(视觉语言模型)进行标注。接着执行语义去重,以构建一个多样但紧凑的数据集。
视频分词
研究者开发了一系列具有不同压缩比的视频分词器。这些分词器是因果性的(即当前帧的token计算不依赖未来帧)。
这种因果性设计带来了多个好处。在训练方面,它使得联合图像和视频训练成为可能,因为当输入为单张图像时,因果性视频分词器也可以作为图像分词器。
这对于视频模型利用图像数据集进行训练非常重要,因为图像数据集包含丰富的世界外观信息,且通常更加多样化。
在应用方面,因果性视频分词器更适合生活在因果世界中的物理AI系统。
WFM预训练
研究者探索了两种可扩展的预训练世界基础模型的方法——扩散模型和自回归模型。他们使用了Transformer架构,以实现可扩展性。
对于基于扩散的WFM,预训练包括两个步骤:
1. 文本到世界生成预训练(Text2World generation pre-training)
2. 视频到世界生成预训练(Video2World generation pre-training)
具体来说,他们训练了模型根据输入的文本提示词生成一个视频世界。然后对其进行微调,使其能够根据过去的视频和输入的文本提示词生成未来的视频世界,这被称为视频到世界生成任务(Video2World generation task)。
对于基于自回归的 WFM,预训练包括两个步骤:
1. 基本的下一个token生成(vanilla next token generation)
2. 文本条件的视频到世界生成(text-conditioned Video2World generation)
他们首先训练模型根据过去的视频输入生成未来的视频世界(前瞻生成)。然后对其进行微调,使其能够根据过去的视频和文本提示词生成未来的视频世界。
视频到世界生成模型是一种基于当前观测和提示词预测未来的预训练世界模型。
对于扩散模型和自回归模型的WFM,研究者构建了一系列具有不同容量的模型,并研究了其在各种下游应用中的有效性。
他们进一步微调了预训练的扩散WFM,以开发一个扩散解码器来增强自回归模型的生成结果。
为了更好地控制WFM,他们还基于LLM构建了一个提示词上采样器。
WFM后训练
团队展示了预训练WFM在多个下游物理AI应用中的应用。
他们将预训练的WFM微调为以相机姿态作为输入提示词,这让他们能够在创建的世界中自由导航。此外他们还展示了如何微调预训练的WFM,以用于人形机器人和自动驾驶任务。
安全机制
为了安全使用开发的世界基础模型,研究者开发了一个安全机制,用于阻止有害的输入和输出。
Cosmos世界基础模型平台由几个主要组件组成:视频编辑器、视频分词器、预训练的世界基础模型、世界基础模型后训练样本,以及安全机制
他们相信,WFM对物理AI构建者有多种用途,包括(但不限于):
策略评估
与其通过在真实世界中运行物理AI系统来评估训练后的策略,不如让物理AI系统的数字副本与世界基础模型交互。基于WFM的评估更加经济高效且节省时间。
通过WFM,构建者可以在未见过的环境中部署策略模型,这些环境在现实中可能无法获得。WFM帮助开发者快速排除不合格的策略,聚焦于潜力更大的策略。
策略初始化
策略模型根据当前观测和给定任务,生成物理AI系统需要执行的动作。建模世界动态模式的高质量WFM,可以作为策略模型的良好初始化。
这有助于解决物理AI中的数据稀缺问题。
策略训练
在强化学习设置中,WFM与奖励模型配对,可以作为物理世界的代理,为策略模型提供反馈。智能体通过与WFM的交互,逐步掌握解决任务的能力。
规划或模型预测控制
WFM可用于模拟物理AI系统在执行不同动作序列后,可能出现的未来状态,然后通过成本/奖励模块量化这些不同动作序列的表现。
物理AI可以根据整体模拟结果执行最佳动作序列(如在规划算法中),或以递归视界的方式执行(如在模型预测控制中)。
世界模型的准确性决定了这些决策策略的性能上限。
合成数据生成
WFM不仅可用于生成用于训练的合成数据,还可以微调为基于渲染元数据(如深度图或语义图)进行条件生成。条件 WFM可用于Sim2Rea 场景。
数据编辑
研究者提出了一种视频处理流程,用于为分词器和WFM生成高质量训练数据集。
如下图所示,流程包括5个主要步骤:1)分割,2)过滤,3)标注,4)去重,以及5)分片。
这些步骤均经过专门的优化,从而提高数据质量并满足模型训练的需求。

预训练数据集
研究者积累了大约2000万小时的原始视频,分辨率从720p到4k不等,并为预训练生成了大约10^8个视频片段,为微调生成了大约10^7个视频片段。
其中,涵盖了各种物理AI应用,并将训练视频数据集划分为以下类别:
驾驶(11%)
手部动作和物体操作(16%)
人体动作和活动(10%)
空间意识和导航(16%)
第一人称视角(8%)
自然动态(20%)
动态相机运动(8%)
合成渲染(4%)
Tokenizer(分词器)
分词器是大模型的基础构建模块,它通过学习瓶颈式的潜空间,以无监督方式将原始数据转换为更高效的表示形式。
下图以示意图形式展示了分词训练流程,其目标是训练编码器和解码器,使瓶颈式token表示能够最大程度保留输入的视觉信息。
视频分词流程:输入视频被编码为token,解码器随后从这些token中重建输入视频。分词器的训练目标是学习编码器和解码器,尽可能保留token中的视觉信息
连续分词器将视觉数据编码为连续的潜嵌入,并用于通过从连续分布中采样生成数据的模型。
离散分词器将视觉数据编码为离散的潜代码,并将其映射为量化索引。这种离散表示对于使用交叉熵损失训练的模型(如GPT)是必要的。
分词器的成功很大程度上取决于其在不损害后续视觉重建质量的情况下提供高压缩率的能力。
在此,研究者提出了一套视觉分词器——包括用于图像和视频的连续和离散分词器。它们可以提供卓越的视觉重建质量和推理效率,并支持多种压缩率,以适应不同的计算限制和应用需求。
连续和离散分词器的可视化:(左)连续潜嵌入,嵌入大小为C;(右)量化索引,每种颜色代表一个离散的潜编码
具体来说,Cosmos分词器采用轻量化且计算高效的架构,并结合时间因果机制。
通过使用因果时间卷积层和因果时间注意力层,可以保留视频帧的自然时间顺序,从而通过单一统一的网络架构实现图像和视频的无缝分词。
通过在高分辨率图像和长时视频上直接训练分词器,可以不受类别或宽高比的限制,包括1:1、3:4、4:3、9:16和16:9等。
在推理阶段,它对时间长度不敏感,能够处理超出训练时时间长度的视频分词。
不同视觉分词器及其功能的比较
评估结果表明,Cosmos分词器在性能上显著超越了现有分词器——不仅质量更高,而且运行速度最高可快12 倍。
此外,它还可以在单块NVIDIA A100 GPU(80GB显存)上一次性编码长达8秒的1080p视频和10秒的720p视频,且不会耗尽内存。
连续分词器(左)和离散分词器(右)在时空压缩率(对数刻度)与重建质量(PSNR)上的比较。每个实心点表示一种分词器配置,展示了压缩率与质量之间的权衡关系
世界基础模型预训练
研究者利用两种不同的深度学习范式——扩散模型和自回归模型——来构建两类WFM。
本文中所有WFM模型都是在一个包含10,000个NVIDIA H100 GPU的集群上训练的,训练周期为三个月。
基于扩散模型和自回归模型的世界基础模型(WFM)
自回归世界基础模型生成的视频
研究者展示了如何将Cosmos WFM进行微调,以支持多种场景,包括3D视觉导航,让不同的机器人执行任务,以及自动驾驶。
世界基础模型后训练
用于机器人的WFM后训练
世界模型具有支持机器人操作的强大潜力,这里展示了两个任务:(1)基于指令的视频预测,(2)基于动作的下一帧预测。
对于基于指令的视频预测,输入是机器人当前视频帧以及文本指令,输出是预测的视频。基于动作的下一帧预测,输入是机器人的当前视频帧以及当前帧与下一帧之间的动作向量,输出是预测的下一帧,展示机器人执行指定动作的结果。
对于基于指令的视频预测,研究者创建了一个名为Cosmos-1X的数据集。该数据集包含大约200小时的由EVE(1x.Tech公司的一款人形机器人)捕捉的第一视角视频,包括导航、折叠衣物、清洁桌面、拾取物体等。
对于基于动作的下一帧生成,团队使用了一个名为Bridge的公开数据集。Bridge数据集包括大约20,000个第三人称视角的视频,展示了机器人手臂在厨房环境中执行不同任务的过程。

用于自动驾驶的后训练
研究者展示了如何对预训练的WFM进行微调,从而创建一个适用于自动驾驶任务的多视角世界模型。
研究者策划了一个内部数据集,称为真实驾驶场景(RDS)数据集。该数据集包含大约360万个20秒的环视视频片段,这些视频是通过英伟达的内部驾驶平台录制的。
研究者使用RDS数据集对Cosmos-1.0-Diffusion-7B-Text2World进行微调,打造出一个多视角的世界模型。
Cosmos-1.0-Diffusion-7B-Text2World-Sample-MultiView-TrajectoryCond模型结果
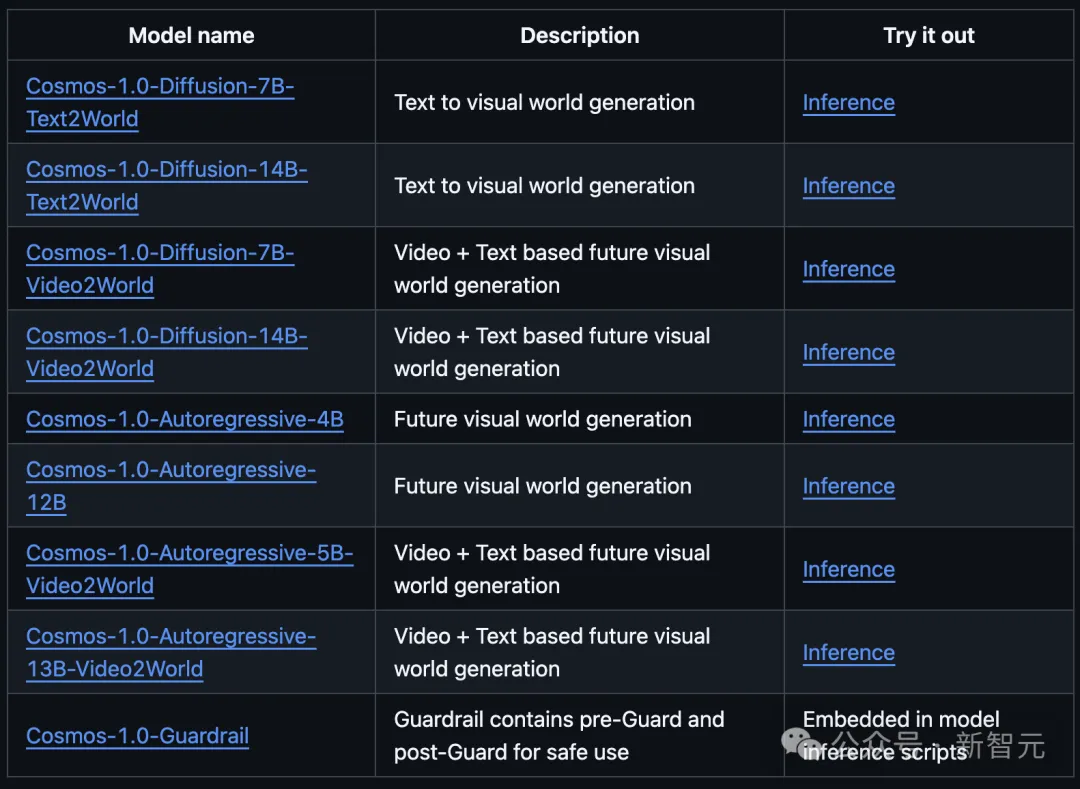
从GitHub主页中,我们能够看到Cosmos家族的所有模型系列:扩散模型和自回归模型各4个。
扩散模型7B和14B(Text2World)根据同一提示,生成效果如下:

扩散模型7B和14B(Video2World)根据同一提示,生成效果如下:

自回归模型4B和12B生成效果如下:

自回归模型5B和13B根据同一提示,生成效果如下:

此外,后训练世界基础模型还能实现「相机控制」,如下机器人在车厂的生成视频中,通过移动能够看到四周环境全貌。
提示:这段视频展示了一座先进的制造设施,其中多台机器人手臂协同工作。这些机器人配备了特殊的抓取装置,正在中央平台上处理和组装组件。环境干净且井然有序,背景中可以看到各种机械和设备。整个机器人系统高度自动化,体现了高科技的生产流程。
更惊喜的是,Cosmos还能根据提示,生成出各种机器人在不同环境中的预测场景。比如,把书放在书架上,煮咖啡、分拣物品......










