
这个文档和附带的脚本详细介绍了如何构建针对各种系统和网络拓扑的高性能可拓展模型。这个技术在本文档中用了一些低级的 Tensorflow Python 基元。在未来,这些技术将被并入高级 API。
输入管道
性能指南阐述了如何诊断输入管道可能存在的问题及其最佳解决方法。在使用大量输入和每秒更高的采样处理中我们发现 tf.FIFOQueue 和 tf.train.queue_runner 无法使用当前多个 GPU 生成饱和,例如在使用 AlexNet 训练 ImageNet 时。这是因为使用了 Python 线程作为底层实现,而 Python 线程的开销太大了。
我们在脚本中采用的另一种方法是通过 Tensorflow 中的本机并行构建输入管道。我们的方法主要由如下 3 个阶段组成:
通过利用 data_flow_ops.StagingArea,每个阶段的主要部分与其他阶段并行执行。StagingArea 是一个像队列(queue)一样且类似于 tf.FIFOQueue 的运算符。不同之处在于 StagingArea 提供了更简单的功能且可在 CPU 和 GPU 中与其他阶段并行执行。将输入管道拆分为 3 个独立并行操作的阶段,并且这是可扩展的,充分利用大型的多核环境。本节的余下部分将详细介绍每个阶段以及 data_flow_ops.StagingArea 的使用细节。
并行 I/O 读取
data_flow_ops.RecordInput 用于磁盘的并行读取。给定一个代表 TFRecords 的输入文件列表,RecordInput 可使用后台线程连续读取记录。这些记录被放置在大型的内部池中,当这个池加载量达到其容量的一半时,会有相应的张量输出。这个操作有其内部线程,线程由占用最少的 CPU 资源的 I/O 时间主导,这就允许它可与模型的其余部分并行运行。
并行图像处理
从 RecordInput 读取图像后,它们作为张量被传递至图像处理管道。为了更方便解释图像处理管道,假设输入管道的目标是 8 个批量大小为 256(每个 GPU 32 个)GPU。256 个图像记录的读取和处理是独立并行的。从图中 256 个 RecordInput 读操作开始,每个读取操作后都有一个与之相匹配的图像预处理操作,这些操作是彼此独立和并行执行的。这些图像预处理操作包括诸如图像解码、失真和调整大小。
当图像通过预处理器后,它们被联接成 8 个大小为 32 的张量。为了达到这一目的,使用了 tf.parallel_stack,而不是 tf.concat ,目的作为单一操作被实现,且在将它们联结在一起之前需要所有输入准备就绪。tf.parallel_stack 将未初始化的张量作为输出,并且在有张量输入时,每个输入的张量被写入输出张量的指定部分。
当所有的张量完成输入时,输出张量在图中传递。这有效隐藏了由于产生所有输入张量的长尾(long tail)而导致的内存延迟。
并行从 CPU 到 GPU 的数据传输
继续假设目标是批量大小为 256(每个 GPU 32 个)8 个 GPU,一旦输入图像被处理完并被 CPU 联接后,我们将得到 8 个批量大小为 32 的张量。Tensorflow 可以使一个设备的张量直接用在任何其他设备上。为使张量在任何设备中可用,Tensorflow 插入了隐式副本。在张量被实际使用之前,会在设备之间调度副本运行。一旦副本无法按时完成运行,需要这些张量的计算将会停止并且导致性能下降。
在此实现中,data_flow_ops.StagingArea 用于明确排定并行副本。最终的结果是当 GPU 上的计算开始时,所有张量已可用。
软件管道
由于所有的阶段都可以在不同的处理器下运行,在它们之间使用 data_flow_ops.StagingArea 可使其并行运行。StagingArea 是一个与 tf.FIFOQueue 相似且像队列(queue)一样的运算符,tf.FIFOQueue 提供更简单的功能可在 CPU 和 GPU 中被执行。
在模型开始运行所有的阶段之前,输入管道阶段将被预热,以将其间的分段缓存区置于一组数据之间。在每个运行阶段中,开始时从分段缓冲区中读取一组数据,并在最后将该组数据推送。
例如有 A、B、C 三个阶段,这之间就有两个分段区域 S1 和 S2。在预热时,我们运行:
Warm up:
Step 1: A0
Step 2: A1 B0
Actual execution:
Step 3: A2 B1 C0
Step 4: A3 B2 C1
Step 5: A4 B3 C2
预热结束之后,S1 和 S2 各有一组数据。对于实际执行的每个步骤,会计算一组来自分段区域的数据,同时分段区域会添加一组新数据。
此方案的好处是:
-
所有的阶段都是非阻塞的,因为预热后分段区域总会有一组数据存在。
-
每个阶段都可以并行处理,因为它们可以立即启动。
-
分段缓存区具有固定的内存开销,并至多有一组额外的数据。
-
运行一个步骤的所有阶段只需要调用 singlesession.run(),这使得分析和调试更加容易。
构建高性能模型的最佳实践
以下收集的是一些额外的最佳实践,可以改善模型性能,增加模型灵活性。
使用 NHWC 和 NCHW 建模
CNN 使用的绝大多数 Tensorflow 操作都支持 NHWC 和 NCHW 数据格式。在 GPU 中,NCHW 更快;但是在 CPU 中,NHWC 只是偶尔更快。
构建一个支持日期格式的模型可增加其灵活性,能够在任何平台上良好运行。基准脚本是为了支持 NCHW 和 NHWC 而编写的。使用 GPU 训练模型时会经常用到 NCHW。NHWC 在 CPU 中有时速度更快。在 GPU 中可以使用 NCHW 对一个灵活的模型进行训练,在 CPU 中使用 NHWC 进行推理,并从训练中获得合适的权重参数。
使用融合的批处理归一化
Tensorflow 中默认的批处理归一化被实现为复合操作,这是很通用的做法,但是其性能不好。融合的批处理归一化是一种替代选择,其在 GPU 中能取得更好的性能。如下是用 tf.contrib.layers.batch_norm 实现融合批处理归一化的一个实例:
bn = tf.contrib.layers.batch_norm(
input_layer, fused=True, data_format='NCHW'
scope=scope)
变量分布和梯度聚合
训练期间,训练的变量值通过聚合的梯度和增量进行更新。在基准脚本中,展示了通过使用灵活和通用的 Tensorflow 原语,我们可以构建各种各样的高性能分布和聚合方案。
在基准脚本中包括 3 个变量分布和聚合的例子:
-
参数服务器,训练模型的每个副本都从参数服务器中读取变量并独立更新变量。当每个模型需要变量时,它们将被复制到由 Tensorflow 运行时添加的标准隐式副本中。示例脚本介绍了使用此方法如何进行本地训练、分布式同步训练和分布式异步训练。
-
拷贝,在每个 GPU 上放置每个训练变量相同的副本,在变量数据立即可用时,正向计算和反向计算立即开始。所有 GPU 中的梯度都会被累加,累加的总和应用于每个 GPU 变量副本,以使其保持同步。
-
分布式复制,将每个 GPU 中的训练参数副本与参数服务器上的主副本放置在一起,在变量数据可用时,正向计算和反向计算立即开始。一台服务器上每个 GPU 的梯度会被累加,然后每个服务器中聚合的梯度会被应用到主副本中。当所有的模块都执行此操作后,每个模块都将从主副本中更新变量副本。
以下是有关每种方法的其他细节。
参数服务器变量
在 Tensorflow 模型中管理变量的最常见方式是参数服务器模式。
在分布式系统中,每个工作器(worker)进程运行相同的模型,参数服务器处理其自有的变量主副本。当一个工作器需要一个来自参数服务器的变量时,它可从其中直接引用。Tensorflow 在运行时会将隐式副本添加到图形中,这使得在需要它的计算设备上变量值可用。当在工作器上计算梯度时,这个梯度会被传输到拥有特定变量的参数服务器中,而相应的优化器被用于更新变量。
以下是一些提高吞吐量的技术:
为了协调工作器,常常采用异步更新模式,其中每个工作器更新变量的主副本,而不与其他工作器同步。在我们的模型中,我们展示了在工作器中引入同步机制是非常容易的,所以在下一步开始之前所有的工作器必须完成更新。
这个参数服务器方法同样可以应用在本地训练中,在这种情况下,它们不是在参数服务器之间传播变量的主副本,而是在 CPU 上或分布在可用的 GPU 上。
由于该设置的简单性,这种架构在社区中获得广泛的推广。
通过传递参数 variable_update=parameter_server,也可以在脚本中使用此模式。
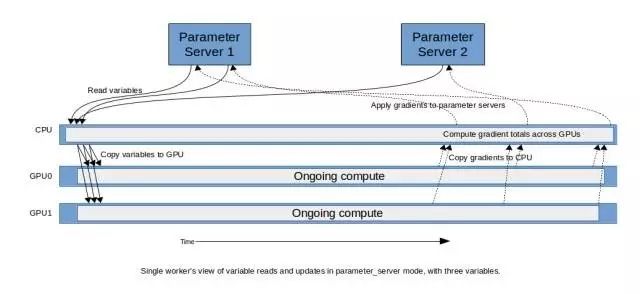
变量复制
在这种设计中,服务器中的每个 GPU 都有自己的变量副本。通过将完全聚合的梯度应用于变量的每个 GPU 副本,使得这些值在 GPU 之间保持同步。
因为变量和数据在训练的初始阶段就准备好了,所以训练的前向计算可以立即开始。聚合各个设备的梯度以得到一个完全聚合的梯度,并将该梯度应用到每个本地副本中。
服务器间的梯度聚合可通过不同的方法实现:
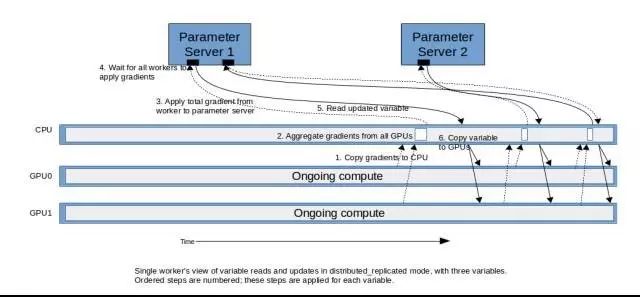
分布式训练中的变量复制
上述变量复制的方法可扩展到分布式训练中。一种类似的方法是:完全地聚合集群中的梯度,并将它们应用于每个本地副本。这种方法在未来版本的脚本中可能会出现,但是当前的脚本采用不同的方法。描述如下。
在这一模式中,除了变量的每一个 GPU 副本之外,主副本被存储在参数服务器之中。借助这一复制模式,可使用变量的本地副本立刻开始训练。
随着权重的梯度可用,它们会被送回至参数服务器,并所有的本地副本都会被更新:
-
同一个工作器中把 GPU 所有的梯度聚合在一起。
-
将来自各个工作器的聚合梯度发送至自带变量的参数服务器中,其中使用特殊的优化器来更新变量的主副本。
-
每个工作器从主副本中更新变量的本地副本。在示例模型中,这是在一个拥有交叉副本的负载中在等待所有的模块完成变量更新后进行的,并且只有在负载被所有副本释放以后才能获取新的变量。一旦所有的变量完成复制,这就标志着一个训练步骤的完成,和下一个训练步骤的开始。
尽管这些听起来与参数服务器的标准用法很相似,但是其性能在很多案例中表现更佳。这很大程度因为计算没有任何延迟,早期梯度的大部分复制延迟可被稍后的计算层隐藏。
通过传递参数 variable_update=distributed_replicated 可以在脚本中使用该模式。
NCCL
为了在同一台主机的不同 GPU 上传播变量和聚合梯度,我们可以使用 Tensorflow 默认的隐式复制机制。
然而,我们也可以选择 NCCL(tf.contrib.nccl)。NCCL 是英伟达的一个库,可以跨不同的 GPU 实现数据的高效传输和聚合。它在每个 GPU 上分配一个协作内核,这个内核知道如何最好地利用底层硬件拓扑结构,并使用单个 SM 的 GPU。
通过实验证明,尽管 NCCL 通常会加速数据的聚合,但并不一定会加速训练。我们的假设是:隐式副本基本是不耗时的,因为它们本在 GPU 上复制引擎,只要它的延迟可以被主计算本身隐藏起来,那么。虽然 NCCL 可以更快地传输数据,但是它需要一个 SM,并且给底层的 L2 缓存增加了更多的压力。我们的研究结果表明,在 8 个 GPU 的条件下,NCCL 表现出了更优异的性能;但是如果 GPU 更少的情况下,隐式副本通常会有更好的表现。
分段变量
我们进一步介绍一种分段变量模式,我们使用分段区域来进行变量读取和更新。与输入管道中的软件流水线类似,这可以隐藏数据拷贝的延迟。如果计算所花的时间比复制和聚合的时间更长,那么可以认为复制本身是不耗时的。
这种方法的缺点是所有的权重都来自之前的训练步骤,所以这是一个不同于 SGD 的算法,但是通过调整学习率和其他超参数,还是有可能提高收敛性。
脚本的执行
这一节将列出执行主脚本的核心命令行参数和一些基本示例(tf_cnn_benchmarks.py)
注意:tf_cnn_benchmarks.py 使用的配置文件 force_gpu_compatible 是在 Tensorflow 1.1 版本之后引入的,直到 1.2 版本发布才建议从源头建立。
主要的命令行参数
-
model:使用的模型有 resnet50、inception3、vgg16 和 alexnet。
-
num_gpus:这里指所用 GPU 的数量。
-
data_dir:数据处理的路径,如果没有被设置,那么将会使用合成数据。为了使用 Imagenet 数据,可把这些指示 (https://github.com/tensorflow/tensorflow/blob/master/tensorflow_models/inception#getting-started) 作为起点。
-
batch_size:每个 GPU 的批量大小。
-
variable_update:管理变量的方法:parameter_server 、replicated、distributed_replicated、independent。
-
local_parameter_device:作为参数服务器使用的设备:CPU 或者 GPU。
单个实例
# VGG16 training ImageNet with 8 GPUs using arguments that optimize for
# Google Compute Engine.
python tf_cnn_benchmarks.py --local_parameter_device=cpu --num_gpus=8 \
--batch_size=32 --model=vgg16 --data_dir=/home/ubuntu/imagenet/train \
--variable_update=parameter_server --nodistortions
# VGG16 training synthetic ImageNet data with 8 GPUs using arguments that
# optimize for the NVIDIA DGX-1.
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=vgg16 --variable_update=replicated --use_nccl=True
# VGG16 training ImageNet data with 8 GPUs using arguments that optimize for
# Amazon EC2.
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=vgg16 --variable_update=parameter_server
# ResNet-50 training ImageNet data with 8 GPUs using arguments that optimize for
# Amazon EC2.
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=replicated --use_nccl=False
分布式命令行参数
1)ps_hosts:在
:port 的格式中(比如 10.0.0.2:50000),逗号分隔的主机列表用做参数服务器。
2)worker_hosts:(比如 10.0.0.2:50001),逗号分隔的主机列表用作工作器,在
:port 的格式中。
3)task_index:正在启动的 ps_host 或 worker_hosts 列表中的主机索引。
4)job_name:工作的类别,例如 ps 或者 worker。
分布式实例
如下是在两个主机(host_0 (10.0.0.1) 和 host_1 (10.0.0.2))上训练 ResNet-50 的实例,这个例子使用的是合成数据,如果要使用真实数据请传递 data_dir 参数。
# Run the following commands on host_0 (10.0.0.1):
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=worker --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=0
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=ps --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=0
# Run the following commands on host_1 (10.0.0.2):
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=worker --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=1
python tf_cnn_benchmarks.py --local_parameter_device=gpu --num_gpus=8 \
--batch_size=64 --model=resnet50 --variable_update=distributed_replicated \
--job_name=ps --ps_hosts=10.0.0.1:50000,10.0.0.2:50000 \
--worker_hosts=10.0.0.1:50001,10.0.0.2:50001 --task_index=1
via:机器之心
End
为了让大家能有更多的好文章可以阅读,36大数据联合华章图书共同推出「祈文奖励计划」,该计划将奖励每个月对大数据行业贡献(翻译or投稿)最多的用户中选出最前面的10名小伙伴,统一送出华章图书邮递最新计算机图书一本。投稿邮箱:[email protected]
点击查看:你投稿,我送书,「祈文奖励计划」活动详情>>>
如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?
排名前50的开源Web爬虫用于数据挖掘
33款可用来抓数据的开源爬虫软件工具
在中国我们如何收集数据?全球数据收集大教程
PPT:数据可视化,到底该用什么软件来展示数据?
干货|电信运营商数据价值跨行业运营的现状与思考
大数据分析的集中化之路 建设银行大数据应用实践PPT
【实战PPT】看工商银行如何利用大数据洞察客户心声?
六步,让你用Excel做出强大漂亮的数据地图
数据商业的崛起 解密中国大数据第一股——国双
双11剁手幕后的阿里“黑科技” OceanBase/金融云架构/ODPS/dataV
金融行业大数据用户画像实践
“
讲述大数据在金融、电信、工业、商业、电子商务、网络游戏、移动互联网等多个领域的应用,以中立、客观、专业、可信赖的态度,多层次、多维度地影响着最广泛的大数据人群
搜索「36大数据」或输入36dsj.com查看更多内容。
投稿/商务/合作:[email protected]





