“如果没有 AI 就写不出好代码,那你可能压根就没资格搞开发。”
一些人认为生成式 AI 的第一个杀手级应用场景已经出现了,那就是 AI 编程工具。无论是 Curosr 还是 GitHub Copilot,都在商业化上取得了成功。有机构估计,到 2024 年 11 月,Cursor 的年经常性收入(ARR)已经达到 6500 万美元。而 GitHub Copilot 的数据更漂亮,根据今年 7 月份从微软财报电话会议来看,GitHub Copilot ARR 已经超过 3 亿美元,占 GitHub 今年整体增长的 40%。
微软一直在不遗余力地推广 GitHub Copilot。GitHub 称人工智能从根本上改变了软件开发,Copilot 已经帮助开发人员将编码速度提高了 55%。其首席执行官 Thomas Dohmke 还曾放话说“不久后 80% 的代码将由 Copilot 编写。”
但问题仍然存在:使用 GitHub Copilot 编写的代码质量客观上是更好还是更差?
今年初,GitClear 收集并分析了 2020 年 1 月至 2023 年 12 月期间编写的 1.53 亿行更改的代码,经分析后发表报告称,GitHub Copilot 的参与反而降低了代码质量。这份报告流传甚广,争议也不小,其结论肯定不是他们愿意看到的。
GitHub 显然希望支持“GitHub Copilot 能提高代码质量”的观点。今年 11 月,GitHub 自己进行了一项研究,称其具有“科学意义”。在这项研究中,他们声称,使用 Copilot AI 模型编写的代码在功能性、可读性、可靠性、可维护性和简洁性等方面“显著提升”。
不幸的是,这一研究过程和结果遭到软件开发人员的强烈质疑。博主 ThePrimeTime 直呼 “Github 谎报了 Copilot 的统计数据”,而另一位来自罗马尼亚的 Dan Cîmpianu 则专门为此发表博文,抨击 GitHub Copilot 关于代码质量言论中的统计数据不够严谨。
GitHub 拒绝对此事以及业界的批评意见发表置评。
1
“我们震惊于微软对自家工具效果的研究居然如此轻率”
GitHub 这份研究表明,使用 Copilot 后开发人员:
-
在顺利通过研究中所有十项单元测试的几率提升了 56%(p=0.04);
-
使用 GitHub Copilot 时,每发生一个错误所间隔的代码行数平均增长 13.6%(p=0.002);
-
所编写代码的可读性、可靠性、可维护性和简洁性提高了 1% 到 3%(分别为 p=0.003、p=0.01、p=0.041 和 p=0.002);
-
代码获得审核通过的几率提高了 5%(p=0.014)。
研究的第一阶段面向 243 名至少拥有五年 Python 编程经验的开发人员,他们被随机分配使用 GitHub Copilot(104 人)或不使用 GitHub Copilot(98 人)——最终只有 202 位开发人员提交了有效调查结果。
两组均尝试创建一个 Web 服务器来处理某虚构餐厅的评论功能,且须接受十项单元测试的检验。之后,每份提交内容都由至少十位参与者审查——但整个调查过程的实际审查次数只有 1293 次,而非 202 份结果的十倍 2020 次。
这个样本大小也是绝了,GitHub 自诩为“10 亿开发者的家”,但在研究其大力宣传的产品之一时,却仅仅选择了 243 名开发者进行研究。
这些开发者分为两组,一半使用 Copilot,另一半作为对照组。实际上参与者共有 243 人,其中 121 人(是“一半加一人”?)使用了 Copilot,另外 121 人没有使用。在这两组中,分别只有 104 人和 98 人提交了有效的结果。较真一点的话,104 比 98 仅多出 6%,这
算是显著差异
吗?
那么他们到底测试了什么呢?
简而言之就是:
所有参与者都被要求完成一项编码任务,为 Web 服务器编写 API 端点。
Cîmpianu 认为从任务的选择来看,这是一个有偏见的实验,因为编写基本的增删改查(CRUD)应用程序正是网络上绝大多数教程的主要内容,是开发中最无聊、最重复、最没有灵感、认知上最不受挑战的方面之一,因此肯定会在相关代码被包含在模型使用的训练数据当中。
在他看来,最好选择其他更为复杂的选题,比如涉及大型 SQL 查询、正则表达式、Shell 脚本部署的多样化任务,而不仅仅是定义一些 REST 接口和 Python 中的类型提示。
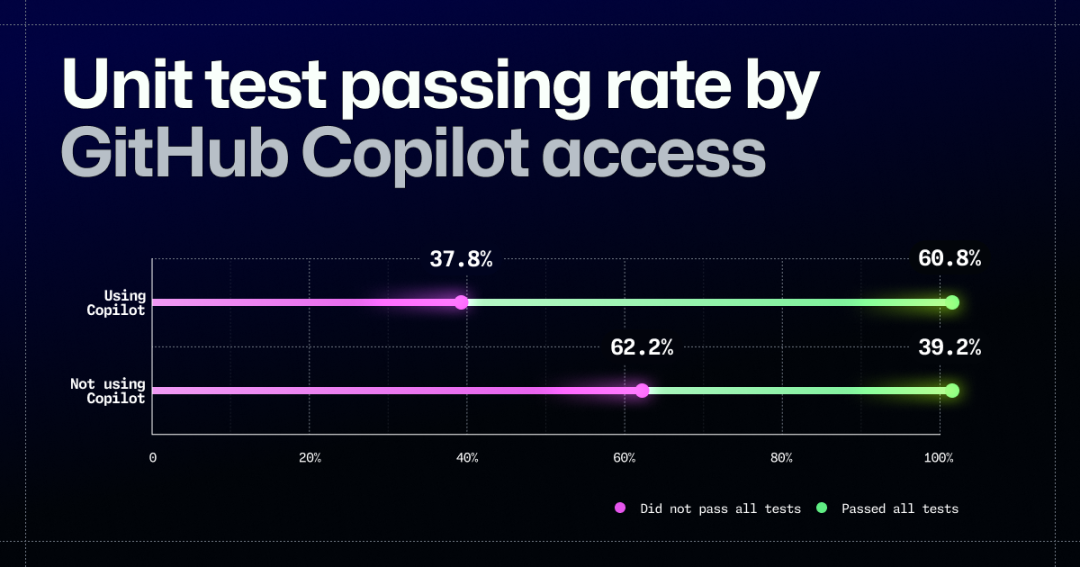
请注意,这些图表中的百分比加起来不等于 100%,因为计算是由大模型完成的。
而且 GitHub 没有充分解释图表内容,图表显示在使用 Copilot 的开发人员中,有 60.8% 通过了全部十项单元测试;而不使用 Copilot 的开发者中,只有 39.2% 通过了所有测试。
根据该公司提供的开发者总数,意味着全部使用 Copilot 的 104 名开发人员中有 63 人通过,不使用 Copilot 的 98 名开发者中有约 38 名通过。但 GitHub 随后发帖指出,“在研究的第一阶段,我们通过十项单元测试对
25 名随机分配开发者
编写的匿名提交代码进行盲审,其中同时包含在使用及未使用 GitHub Copilot 条件下编写的代码。”
Cîmpianu 发现这里明显存在矛盾。一种可能的解释是 GitHub 在表达上不够严谨,实际是从成功通过所有测试的 101 名开发者中,随机挑选出 25 名进行代码审查。
更重要的是,Cîmpianu 对另一项结论同样表达了异议,即使用 Copilot 的开发者产生的代码错误明显更少。GitHub 方面提到,“使用 GitHub Copilot 每写 18.2 行代码会出现一次代码错误,而不使用的测试组每写 16.0 行代码就会出现一次错误。这意味着使用 GitHub Copilot 的开发者在每次出错所间隔的代码量增长了 13.6%(p=0.002)。”
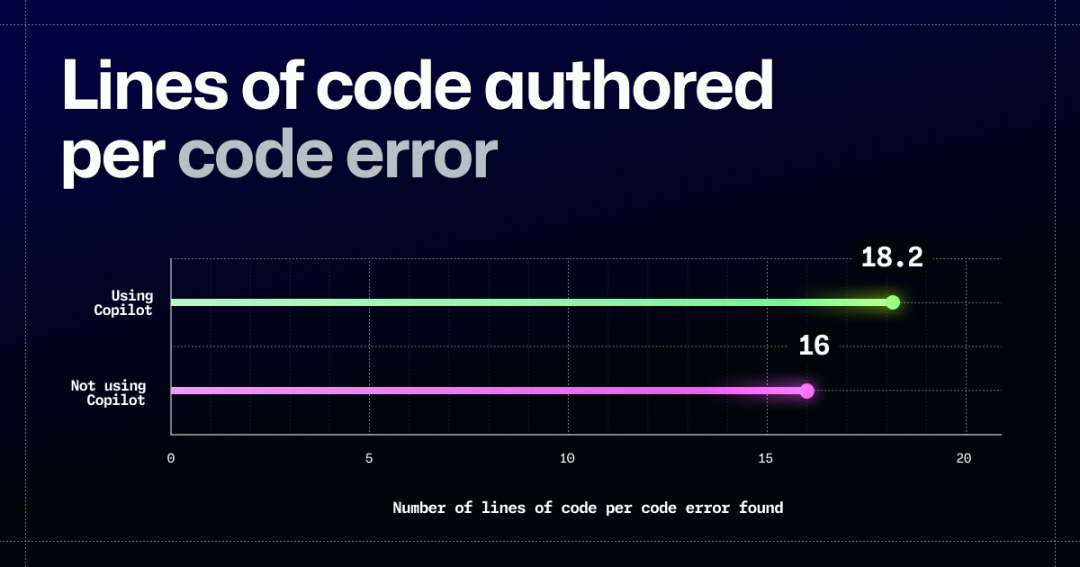
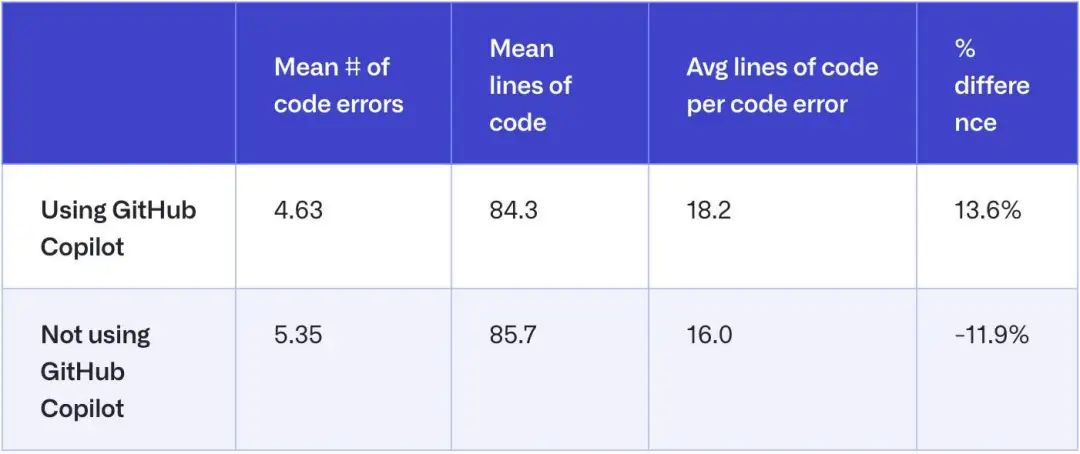
Cîmpianu 认为这里的 13.6% 是一种误导性的统计数据,因为其对应的其实只有两行代码。虽然有人认为随着时间推移,这个数字还会逐渐增加,但他指出这里所谓的错误减少并不是真正提高代码质量,更多只是编程风格问题或者 linter 警告。
GitHub 自己也在代码错误的定义部分承认,“其中不包括会阻止代码按预期运行的功能性错误,而仅代表不良编程实践方面的错误。”
也就是说 GitHub 所指的错误不包括实际的错误或实际的语法错误,它们包括:
命名不一致、标识符不明确、行过长、空格过多、缺少文档、代码重复、分支或循环深度过多、功能分离不足以及复杂性可变。
Cîmpianu 指出,实际上,“
这
不是错误,而是 linter 警告
”。
接下来,GitHub 展示了 Copilot 在平均水平上生成的代码质量提升了约 3%(别忘了,他们强调这是“具有统计学意义”的结果),具体如下图所示:
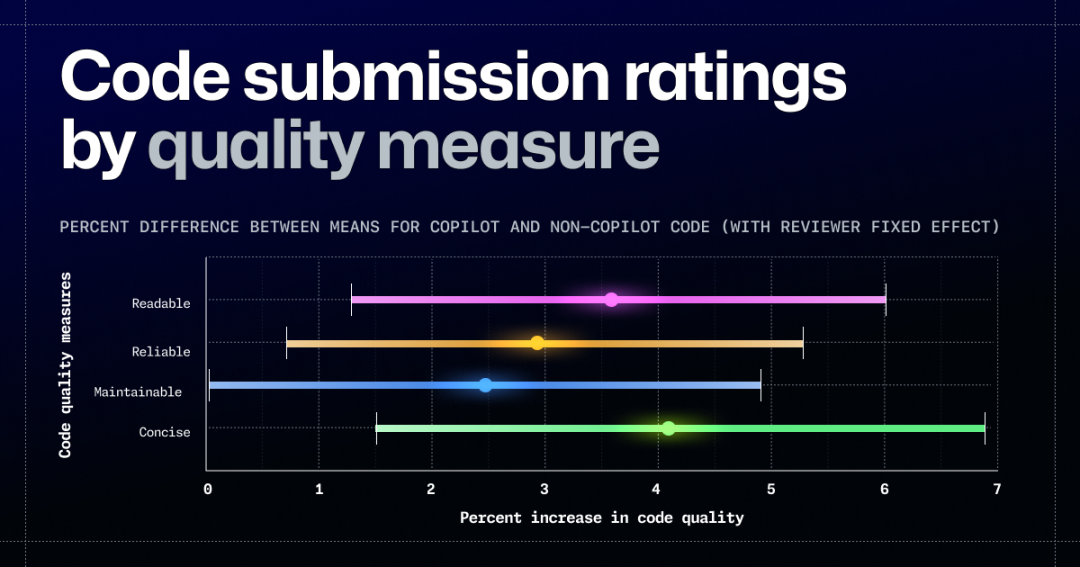
Cîmpianu 对于 GitHub 宣称的,Coiplot 辅助编写的代码在可读性、可靠性、可维护性及简洁性方面提高 1% 到 3% 的说法同样感到不满。
代码风格和代码审查的指标往往非常主观,人们曾因 eslint 规则、缩进风格、大括号位置以及其他“细枝末节”而展开过激烈争论。我们必须承认,人类的直觉是评估这些测试类别的唯一指标。但调查报告也没有提供关于代码评估方式的具体解释。
Cîmpianu 进一步抨击 GitHub 选取参与代码测试的同一批开发人员进行代码评估,认为应当选择公正的第三方评审员。
“好在他们至少还选择了通过所有单元测试的开发人员来审查代码。但请注意,各位朋友,千万别被随机挑选 25 位开发者、3% 的改进指标蒙蔽了双眼。这帮所谓开发者唯一的资历(至少在研究中提到的资历)就只是工作过五年并且通过了十项单元测试。”
Cîmpianu 对此表达了不满。“我对 GitHub 为提升 Copilot 的营销可信度所做的这极少的努力感到非常失望,更让人不解的是,他们竟然认为通过一个人为设计的实验,在几乎完全主观的指标上最多提升 5% 就值得夸耀。即便我勉强承认生产力整体提升了 5%,这看起来也完全不是为了开发者,而更像是一种迎合拥有预算决策权的高管们的
营销策略
。”
Cîmpianu 指出,GitClear 于 2023 年底发表的一份报告曾提到,GitHub Copilot 的参与反而降低了代码质量。
这份报告指出,使用 AI 助手进行编程未必有助于提高产品代码质量,像 GitHub Copilot 这样的 AI 工具实际上只会给出添加代码的建议,却无法提供更新或者删除代码的建议。这会引发严重的代码冗余问题。此外,他们还注意到“流失代码”急剧增加,也就是需要进行频繁修改的代码,这往往代表代码质量堪忧。
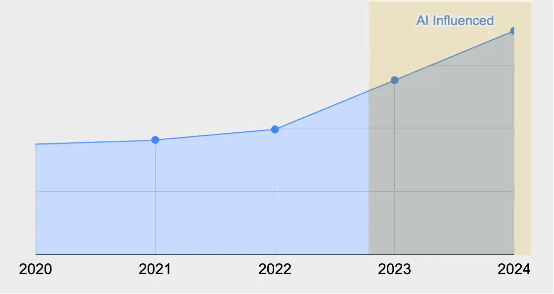
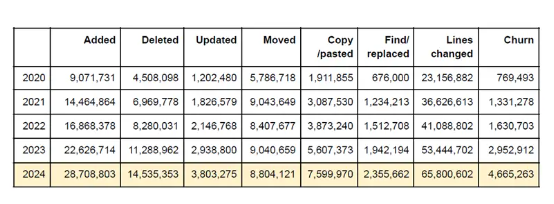
根据 GitClear 的一项最新研究,代码质量有下降趋势,且存在代码更新(即添加代码后不久即被删除)等问题,重复代码的比例也更高。此项研究重点关注对于代码的添加、删除、更新以及复制 / 粘贴或移动,并排除了 GItClear 定义的“噪音”内容——即在多个分支中重新提交的相同代码、空白行及其他不重要的行。以下是 GitClear 分析师们得出的结论:
GitHub Copilot 的发布成为标志性事件。在不到两年时间里,这款基于 AI 的编程助手已经从“原型”成长为开发工作的“基石”,在数十万家企业中得到几百万开发人员的使用。这种前所未有的增长,意味着代码编写的全新时代就此拉开帷幕。
GitHub 发表了大量关于 AI 对软件开发的助益及影响的深入研究。他们提出的一项重要结论是,开发人员使用 Copilot 时的代码编写“速度提高了 55%”。但大语言模型生成的代码也引发了以下问题:
代码的质量与可维护性,与纯人类编写的代码相比有何变化?AI 生成的代码更接近资深开发人员简洁精致的贡献,还是更接近临时外包商的杂乱产出?










