
来源 | 腾讯知乎专栏
作者 | AIoys(腾讯员工,后台工程师)
项目文档和代码在此:github项目地址:
https://github.com/zsysuper/AI_Notes
▌
一、前言
阅读本文的基础:
我会认为你对BP神经网络有充分的了解,熟读过我上一篇文章,本文会大量引用上一篇文章的知识以及代码。
上一篇笔记的传送门:《
AI从入门到放弃:BP神经网络算法推导及代码实现笔记
》
(编辑注:为方便大家阅读,此处添加的是人工智能头条此前发布的文章链接)
▌
二、用MLP做图像分类识别?
在没有CNN以及更先进的神经网络的时代,朴素的想法是用多层感知机(MLP)做图片分类的识别,没毛病。
作为上篇笔记学习的延续,以及下一篇CNN的药引,使用MLP来做图片分类识别,实在是个不错的过度例子。通过这个例子,从思路上引出一系列的问题,我不卖关子,自问自答吧,即:
-
MLP能做图片分类识别吗?--> 答案是是可以的,上一篇我们是拟合非线性分类函数,这里是拟合图像特征,数学本质没区别。
-
MLP做这个事情效果如何?--> 个人认知内,只能说一般一般。
-
MLP在这一领域效果一般,是有什么缺陷吗? --> 缺陷是有的,下文会详细说。
-
有更好的解决方案吗? --> 那也是必须有的,地球人火星人喵星人都知道有CNN等等更先进的东东;但是在没有这些东西存在的时代,你发明出来了,那才真是666。
▌
三、先上车
1. 数据源
-
数据源当然是图片,但是是经过数据化处理的图片,使用的是h5文件。h5文件简单说就是把数据按索引固化起来,挺简单的不多说,度度一下:
h5py入门讲解:
https://blog.csdn.net/csdn15698845876/article/details/73278120
-
我们有3个h5文件,存着不重复的图片数据,分别是:
-
train_catvnoncat.h5 (用来训练模型用的,一共有209张,其中有猫也有不是猫的图片,尺寸64*64像素)
-
test_catvnoncat.h5 (用来测试模型准确度的,一共有50张图片,,其中有猫也有不是猫的图片,尺寸64*64像素)
-
my_cat_misu.h5 (用来玩的,我家猫主子的1张照骗,尺寸64*64像素)
2. 数据结构
拿train_catvnoncat.h5举例,这个文件有2个索引:
同理,test_catvnoncat.h5 中有 test_set_x 和 test_set_y;my_cat_misu.h5 中有 mycat_set_x 和 mycat_set_y
3. 告诉你怎么制作图片的h5文件,以后做cnn等模型训练时,非常有用
以我主子为例子:
原图:

自己处理成64*64的图片,当然你也可以写代码做图片处理,我懒,交给你实现了:

python代码,用到h5py库:
def save_imgs_to_h5file(h5_fname, x_label, y_label, img_paths_list, img_label_list):
data_imgs = np.random.rand(len(img_paths_list), 64, 64, 3).astype('int')
label_imgs = np.random.rand(len(img_paths_list), 1).astype('int')
for i in range(len(img_paths_list)):
data_imgs[i] = np.array(plt.imread(img_paths_list[i]))
label_imgs[i] = np.array(img_label_list[i])
f = h5py.File(h5_fname, 'w')
f.create_dataset(x_label, data=data_imgs)
f.create_dataset(y_label, data=label_imgs)
f.close()
return
data_imgs, label_imgs
save_imgs_to_h5file('datasets/my_cat_misu.h5', 'mycat_set_x', 'mycat_set_y', ['misu.jpg'],[1])
4. 看看我的数据源的样子
用来训练的图片集合,209张:
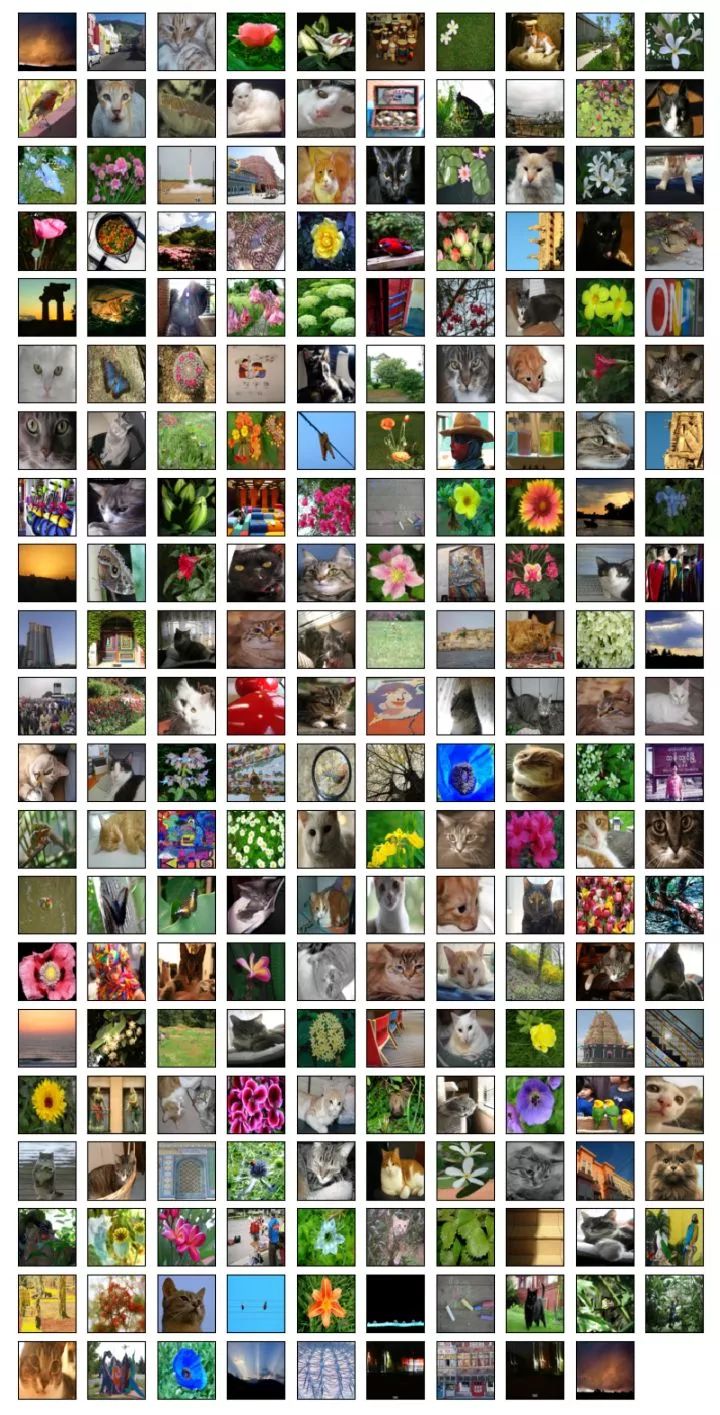
用来校验模型准确度的图片集合, 50张

用来玩的,主子照骗,1张:

▌
四. 开车了
1. 如何设计模型:
【插播】:有人会想,第一层隐藏层的神经元和输入层数量一致是不是会好点?理论上是会好点,但是这涉及到MLP的一个缺陷,因为全连接情况下,这样做,第一层的权重w参数就有1228的平方个,约为1.5个亿。如果图片更大呢?参数会成指数级膨胀,后果尽情想象。
2. 如何训练模型
还用说,把209张图片的数据扔到神经网络,完成一次迭代,然后训练1万次,可自行尝试迭不同代次数观察效果。
3. 如何衡量模型的准确度
大神吴恩达(Andrew Ng)提到的方法之一,就是划分不同集合,一部分用来训练,一部分用来验证模型效果,这样可以达到衡量你所训练的模型的效果如何。所以我们训练使用209张图片,最终使用50张测试模型效果。
为了好玩,可以自己用不同图片通过模型去做分类识别。
▌
五. 老规矩,甩代码
还是说明一下代码流程吧:
代码使用到的 NeuralNetwork 是我上一篇笔记的代码,实现了BP神经网络,import进来直接用即可。
代码做的事情就是:
-
从h5文件加载图片数据
-
把原始图片显示出来,同时也保存成图片文件
-
训练神经网络模型
-
验证模型准确度
-
把识别结果标注到原始图片上,同时也保存成图片文件
import h5py
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
import numpy as np
from NeuralNetwork import *
font = fm.FontProperties(fname='/System/Library/Fonts/STHeiti Light.ttc')
def load_Cat_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:])
train_set_y_orig = np.array(train_dataset["train_set_y"][:])
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:])
test_set_y_orig = np.array(test_dataset["test_set_y"][:])
mycat_dataset = h5py.File('datasets/my_cat_misu.h5', "r")
mycat_set_x_orig = np.array(mycat_dataset["mycat_set_x"][:])
mycat_set_y_orig = np.array(mycat_dataset["mycat_set_y"][:])
classes = np.array(test_dataset["list_classes"][:])
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
mycat_set_y_orig = mycat_set_y_orig.reshape((1, mycat_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, mycat_set_x_orig, mycat_set_y_orig,classes
def predict_by_modle(x, y, nn):
m = x.shape[1]
p = np.zeros((1,m))
output, caches = nn.forward_propagation(x)
for i in range(0, output.shape[1]):
if output[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
print(u"识别率: " + str(np.sum((p == y)/float(m))))
return np.array(p[0], dtype=np.int), (p==y)[0], np.sum((p == y)/float(m))*100
def save_imgs_to_h5file(h5_fname, x_label, y_label, img_paths_list, img_label_list):
data_imgs = np.random.rand(len(img_paths_list), 64, 64, 3).astype('int')
label_imgs = np.random.rand(len(img_paths_list), 1).astype('int')
for i in range(len(img_paths_list)):
data_imgs[i] = np.array(plt.imread(img_paths_list[i]))
label_imgs[i] = np.array(img_label_list[i])
f = h5py.File(h5_fname, 'w')
f.create_dataset(x_label, data=data_imgs)
f.create_dataset(y_label, data=label_imgs)
f.close()
return data_imgs, label_imgs
if __name__ == "__main__":
train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, mycat_set_x_orig, mycat_set_y_orig, classes = load_Cat_dataset()
train_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
test_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
mycat_x_flatten = mycat_set_x_orig.reshape(mycat_set_x_orig.shape[0], -1).T
train_set_x = train_x_flatten / 255.
test_set_x = test_x_flatten / 255.
mycat_set_x = mycat_x_flatten / 255.
print(u"训练图片数量: %d" % len(train_set_x_orig))
print(u"测试图片数量: %d" % len(test_set_x_orig))
plt.figure(figsize=(10, 20))
plt.subplots_adjust(wspace=0










