大家期待已久的
DevFest 2018 现场实录
终于出炉了!

11 月 25 日,1125 位开发者之约,你在吗?
什么?你错过了 DevFest 2018 ?
不要担心,我们将会在接下来的几期为大家推送本次大会的嘉宾演讲实录,不在现场也能干货满满!
本期我们带来谷歌资深工程师顾仁民为大家分享的《TensorFlow Extended》,帮助你了解如何快速落地项目。

关于演讲者

演讲实录

谷歌资深开发工程师 顾仁民
各位好,很高兴大家周末能过来。TensorFlow 是什么、能做什么大家并不陌生,李锐博士也讲了很多(小编:我们马上会放出李锐博士的演讲实录哦,请保持关注)。
 几个例子,看我们身边的 TensorFlow
几个例子,看我们身边的 TensorFlow
我想先给大家简单介绍一个例子,可能这个例子之前大家没怎么说过。
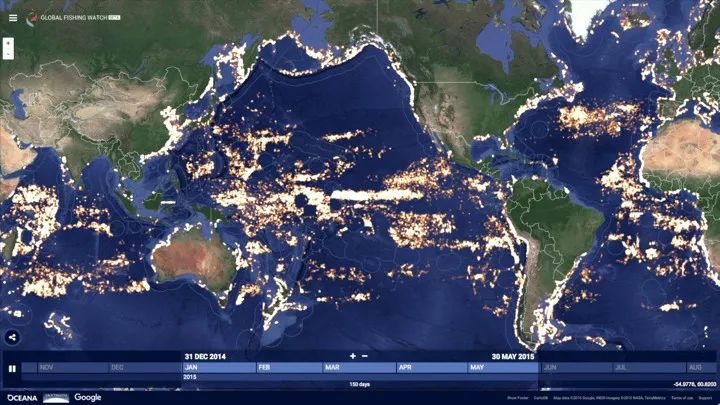
可以从上图看到,这里有很多亮的地方,我们可以猜一下这是什么?这里其实是海洋的区域,有很多船,每个船的活动点都是一个一个亮点,可以看到人类在海洋区域的活动是非常频繁的。
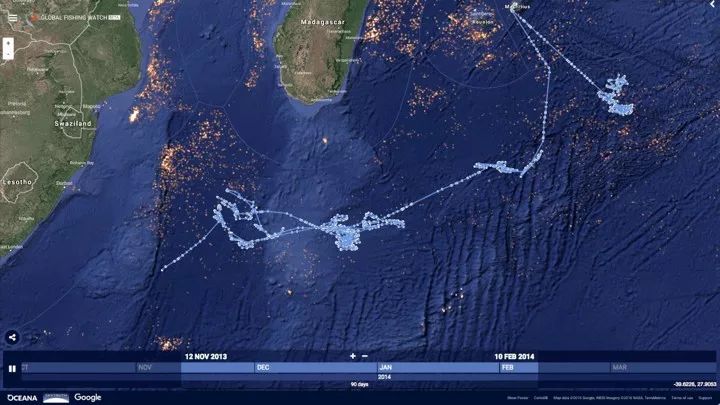
其实我们可以通过船运行的轨迹了解到深处的奥秘。假如有一艘船运行的轨迹是转来转去的,而不是直接从 A 点开到 B 点,是不是很奇怪?但其实它是在捕鱼,我们根据这个轨迹可以判断出来这个船是货船还是某一种特别的渔船,并用机器学习的方式来对这个轨迹进行分类。

知道这个结论之后可以干什么呢?可以进行一些环境保护的操作,保证鱼不会被过度捕捞。
通过类似这个例子的分析,还有几个形象的例子,如果在座的有保险行业的话这是很好的一个参考:
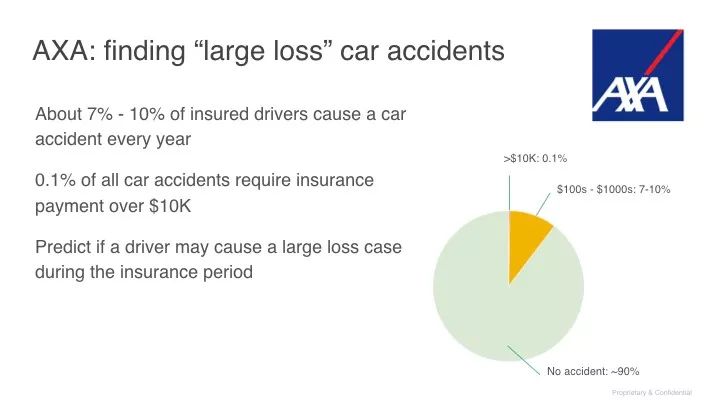


这是谷歌的用例,比如翻译、语音生成、医疗,还有节能等,他们有各自的意义,比如根据用户实际情况,节能用在数据中心最大可以节约 40%。
一起进入 TensorFlow Extended 阶段
刚才讲了很多例子,我们怎么做呢?我们先想想机器学习的代码层面是什么样子。
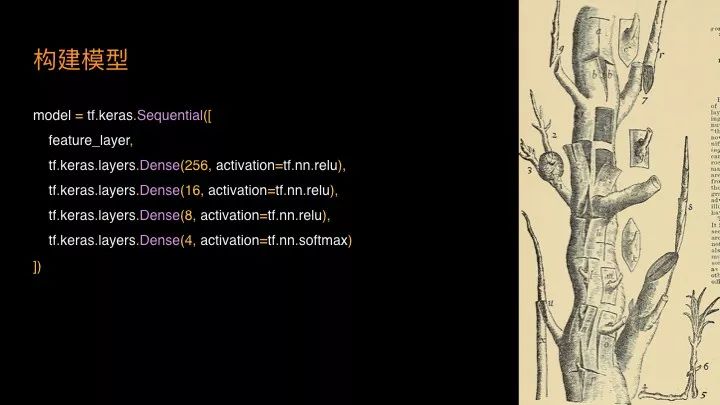
你可能用过 Keras ,从代码上看是比较简单的。
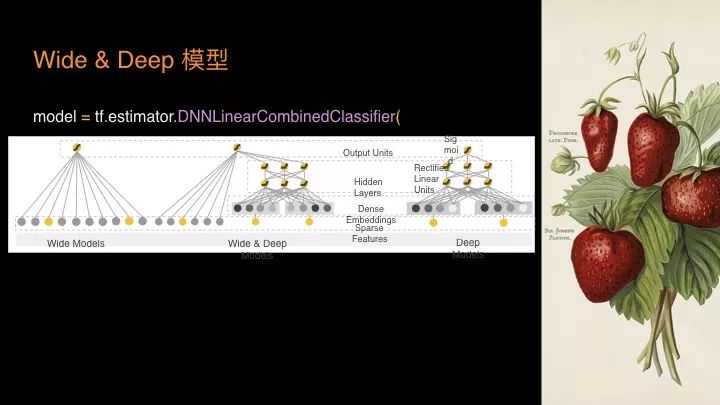
再复杂一点的,Wide & Deep,可能大家很多时候做一个机器系统去做推荐工作,这个稍微有点复杂,我们要实现这样一个模型要多少代码呢?

只有这么点,你直接很快就可以上手了!我们可以认为在机器学习核心部分的模型代码,实际上最终的量都比较小。

什么是 TensorFlow Extended ?
我们进入到机器学习,TensorFlow Extended 这个环节。
TensorFlow Extended 解决了什么问题呢?我们刚才说机器学习的代码很简单,的确是很简单,但是大家日常花很多人力在什么地方呢?

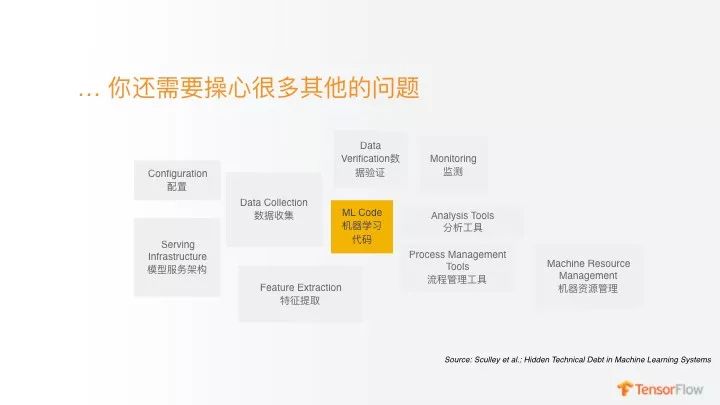
我们有数据收集、配置、机器管理等等各种各样的事情,这种事情花费很多人力,反而我们曾经认为最难的部分是最简单的,机器学习的模型代码部分反而是比较轻松的,那些外围的力量我们是铺人力去做还是怎么弄?
谷歌想帮助大家快速实施落地一些项目,所以我们就提出了 TensorFlow Extended 这样一个项目。

TensorFlow Extended 大概是解决上图的一部分问题,还有很多模块我们还没有开源出来,但是会陆陆续续开源出来,在这个图最底层有储存层、还有管理层,还有数据验证等等工作。
如何准备 Tensorflow Extended 的数据?
TensorFlow Extended 可以分为四个部分。
第一部分,我们先讲一下机器学习的本质。
我们有人工智能、机器学习、深度学习多个概念,机器学习可以认为是数据驱动的智能,所以数据是非常重要的,它本质上是数据进去,然后模型出来,中间有些算法。
但如果你的数据是垃圾数据的话,出来的模型肯定也是有问题的。如果你再加上一个迭代,会用模型再去改进它获取新的数据,那相当于错上加错,所以你进入到一个恶性循环,你的效果会越来越差。
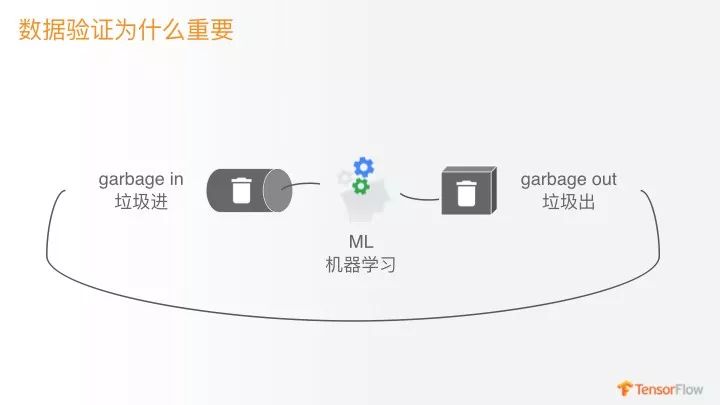
怎么样防止这个问题?就要在第一步数据问题上做保证,这就是它的作用。举个例子:首先是给了你一天的数据,你这一天的数据大概是什么样的状况得有个数,第一批数据我们假设第一天数据,这个数据可能有错的,也可能是正确的,所以要人工检查一下。确保没有错,那就说明这是一个好的数据集,我们以后可以参考这个好的数据集。
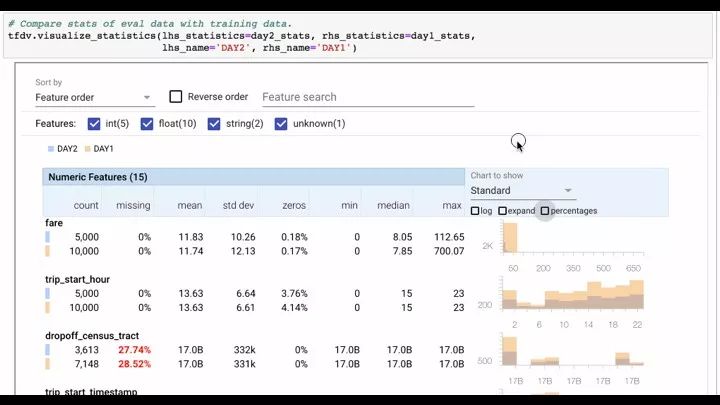
怎么样检查它是好还是不好?一个是你一条一条去看,还有一个是你去看统计信息,你要检查的话可视化检查相对来讲比较方便,所以下面你可以看它的最大值、最小值、均值、方差等等统计相关的信息。
人工检查这个信息之后,你还可以检查得更复杂一点,其中红色的部分能告诉你哪些数据有可能有问题,不一定真的有问题,但是它从统计的角度觉得那些数据可能属于离群数据,是比较特别的数据,它提示你人工进行更详细的检查。

等到你把这些检查的工作都做完之后,基本上可以认为第一天的数据是比较干净、比较正确的了。然后你可以根据这个数据生成一个 schema,这个 schema 相对来讲是更固定一点,有了这个我们刻划了第一天的数据。当然你还可以进一步细调这个 schema。这个 schema 信息还可以用在别的地方,比如说 TensorFlow 这个场景上。
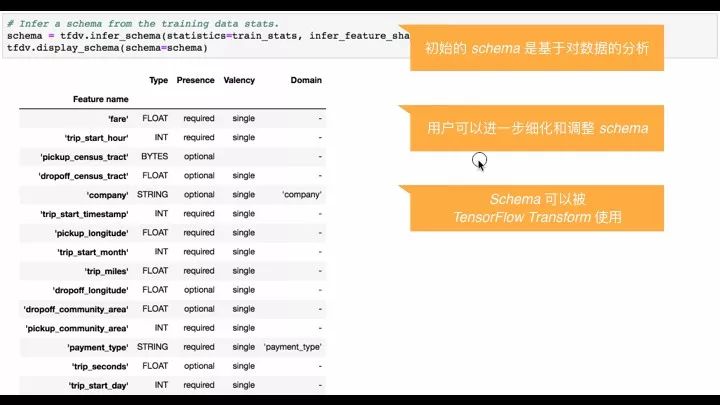
第一天已经解决好了,我们觉得第一天都很好,现在进入第二天。第二天的数据一种假设,我们假设第二天肯定是对的,但是有可能第二天的数据是特别的,有两种情况:
第二天跟第一天不一样,你模型得变。
第二天的数据是脏的。
我们怎么样发现这个问题?第二天的数据也可以生成 stats 数据,我们可以把两天的数据合在一起,比如说第一天的和第二天的一起展现出来,可以看它的均值、方差等等各种指标是不是匹配,如果不匹配,说明第一天和第二天的数据在统计上的分布情况差异比较大,说明你第一天训练的模型不太能够用在第二天,这是这部分的工作。你也可以更详细的去看很多可视化的这些解释。

你看完了之后,就要再进一步的看一下,第一天和第二天是不是还是有比较大的差异性。因为刚才是可视化来看的,如果你想自动化这个过程怎么办,如果你想让人不要老是去看图表怎么办,就要用 stats 去检查差异性。比如说你把第一天的 stats 和第二天的 stats 进行比较,如果第一天统计出来的值,它的值域是 0-100,第二天来了120,说明最大化发生了变化,有可能发生了不太正常的事情。
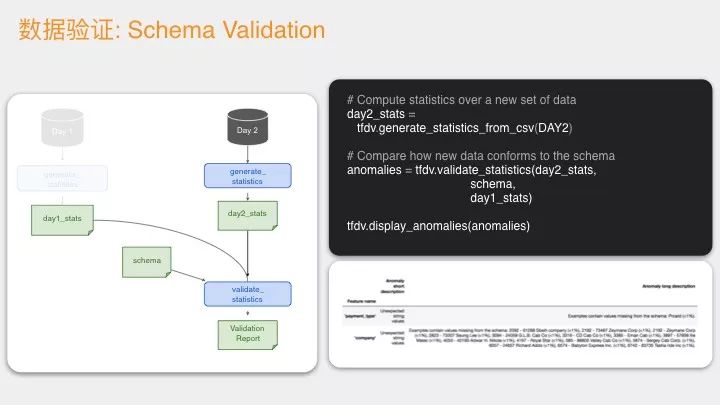
接下来就是 Data validation,你有可能做一些模型转换的数据,就是数据转换的数据也可以同样的做这个工作,包括线上设定的数据也可以做这个工作,多种处理方式都可以去做这个验证。
TensorFlow Extended 模型错了怎么办?
数据做完之后就是 TensorFlow,跟机器学习相关,比如说你做分统,或者一些NLP上面做特征交叉的工作。
下面是很有用的一点,可能你的单一模型不能解决所有的问题,你可能要用多个机器学习模型拼接起来才能解决一个大的问题。比如说你做一个图象识别类、文本识别类的工作,第一步要做一个检测模型,第二步做行空模型,然后对行里做序列的检测。
接下来进入到机器学习核心代码部分去做训练。
你可能会进入一个问题,就是这个模型有可能是错的,或者说数据有可能还是错的,或者说这个模型定义是有问题的,没有表达出这个数据的一些特别的特征出来。
这时候我们要去做一些分析,我们要适合用来分析的版本,然后进入这个模块。
我们以一个典型的例子为例,刻划你的工作是否准确有几个指标,但是这几个指标是针对所有测试集数据的宏观指标,它只能告诉你总体是一个怎么样的情况,就像你考试老师给你打了总的分数,但是你不知道你选择题还是填空题做的好,如果你知道哪一部分做的好、哪一部分做的不好,你可以针对做的不好的部分进行深挖,下次可以做的更好一点,这是它最大的功能,它可以告诉你更细致的信息。
下面有几个例子:
1. 打车的场景,它可以告诉你上午比较好还是下午比较好,在高峰时间数据比较多,低谷时间数据比较小,你可以用这样一个工具很快的去分析出来到底哪些不对。
2. 假设你是做电商的,你在大城市表现很好,但是在中小型城市表现不好,是不是中小型城市数据不够均匀,参数刻划的不够好等等问题,可以帮助你从数据切片的角度来分析到底哪些出了问题。
你的模型不可能一直不变,还是要进行迭代更新的,迭代的时候比如说你上个月的版本和这个月的版本,两个模型是有差异的,原因可能是数据产生了变化,还有算法产生了变化,还有一些别的特殊的业务规则的变化等等各种各样的原因。
这个时候如果你能跟踪出来随着时间的变化这个机器学习小组的产出,它的模型希望效果是越来越好了,还是越来越不好了,还是一直处于比较稳定的状态,那就是比较好的情况了。
我们可以从时间轴上跟踪多个版本来进行自动的回测,到底这个组的产出是不是一直变得更好,如果变得更好,你可以看到哪个时间点开始变得更好了,你可以总结看看那段时间做了什么样的工作使得模型变得好了,这样的话写个报告给老板,这个工作做的意义;还有一个是昨天跑的很好,今天反而不好了,可以反思一下这段时间系统上线了什么东西,我们可以适当的调整模型或者修改特定的BUG,帮助你第一时间找到模型哪里变得不好了。
上线部署需要考虑的问题
你的模型从时间、数据切片等等角度都效果比较好,说明这个工作已经做的比较好了,那就要考虑上线的问题。
上线我们存另一个版本,现在要上线的版本可以更精简更小一点,这个时候我们再用 TensorFlow 这样一个你就可以直接部署使用了,当然部署的时候可以结合里面的一些工具直接上去进行部署等等,这些资源管理类的开源框架去帮你做这些事情。
部署现在我们提供两种,一种叫 GRPC,另一种是 RESTful。可能有人会觉得 GRPC性能不好,如果有的话你们可以跟我们交流,我们 TensorFlow 内部 GRPC 会是主流,但是你们前端开发人员比较多,习惯于用 RESTful,可以用 RESTful。
所有东西做完之后要做一个回馈,日志是这个公司非常宝贵的资源,如果你信息可以回馈到一开始最上面或者更上游一层,会有助于你更良性的循环。
当然这里开源可能还不够多,我们可以结合自己公司已有的处理机制去做这些事情,再进入下一个迭代循环的话,可以帮助你第一时间去发现你的业务系统是不是发生了一些状况。
基本上走完整个流程后,你可以结合人工和自动的方式来确保你的机器学习整个处于一个良性的循环当中。这就是 TensorFlow Extended 所体现出来的价值。

我们现在有上图所示这四块开源的东西,都已经开放了。
还有一些更多的东西会陆陆续续地放出来,当然还会结合 TensorFlow 资源调度类的框架做一些更深度的整合。
总体而言,大家平常比较力度大的、比较消耗人力的这些模块都尽可能的把它开放出来,供大家使用,谢谢大家,希望可以持续关注我们。

GDG , 即 Google Developer Groups 谷歌开发者社区,是谷歌开发者部门发起的全球项目。 GDG 是面向对 Google 和开源技术感兴趣的人群而存在的公益性开发者社区,内容涵盖 Web/Chrome、Android 和其它 Google API 等。全世界各大城市都成立了自己的 GDG 社区,GDG Shanghai (上海谷歌开发者社区)也是其中之一。作为全球GDG 社区中最活跃的技术社区,GDG Shanghai 自创立之初就一直专注 Google 技术和开源技术为主的交流, 基本每周都有 Meetup,我们服务 IT 男,更服务 IT 女!










