激动人心的时刻终于到来!
使用
Wordcloud
库将其生成漂亮的词云图。
同样,使用命令安装:
pip install wordcloud
这里是wordcloud的主页:
https://github.com/amueller/word_cloud
可以在这里对wordcloud有个大致了解。
注意:安装期间可能会出现错误:需要VC ++ 库等,此时不要着急。这里给出解决方案:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
打开上面的网址,会跳转到如下界面:根据你的版本进行下载。
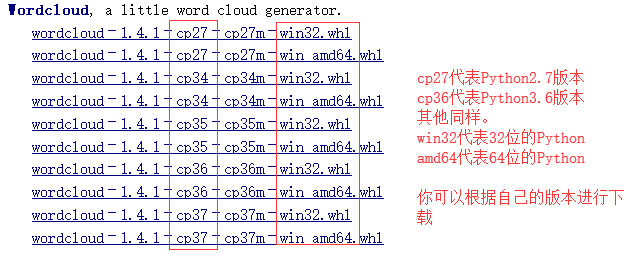
下载下来后,打开命令行(
cmd
),转到文件所在路径,使用命令进行安装:
pip install wordcloud-1.4.1-cp36-cp36m-win32.whl
install 后面的文件名根据你的下载版本替换(tab键自动补全)
安装完就可以正常使用啦。
导入Wordcloud库,使用wordcloud的WordCloud方法,注意
首字母大写
,进行初始化设置:
其中,
width
是图片宽度,
height
是图片高度,
background_color
是背景颜色,
font_path
是字体文件路径(例子中的文件是微软雅黑字体,如果不加字体可能会出现无法显示中文的情况)。然后通过generate方法生成词云图。参数就是上面的words。
import wordcloud
wc=wordcloud.WordCloud(width=1500,height=1500,background_color="white",font_path="./msyh.ttc")
wc.generate(words)
还剩最后一步:
保存文件:通过
to_file()
方法将文件存储到本地。参数就是文件名。
wc.to_file(
"image.jpg"
)
如何找到字体文件:
C:\Windows\Fonts
路径下存储的是字体文件。找到
将其复制出来,放到你所编辑的py文件的相同目录。同样,保存的图片也是这个路径。
至此,这个生成词云图的小程序就结束啦!可能写的比较啰嗦,不是非常详细,不过只要你跟着做一遍,肯定会有很多收获。多做两次,你也会做词云图。
本程序所在环境:
Python3.6
库:
requests/ BeautifulSoup / wordcloud / jieba/ time
以下是完整代码:
import requests
from bs4 import BeautifulSoup
import wordcloud
import jieba
import time
movie_id =24773958
def onepage(url):
r = requests.get(url)
r.encoding = "utf-8"
html = r.text
soup = BeautifulSoup(html,"html.parser")
comments_sec = soup.find("div","mod-bd")
comments_list =comments_sec.find_all("p", "")
lst = []
for i in range(len(comments_list)):
lst.append(comments_list[i].text.strip())
return lst
def parsepage(movie_id, page_num):
data = []
for i in range(page_num):
url ="https://movie.douban.com/subject/" + str(movie_id) +"/comments?start=" + str(20 * i) + "&limit=20"
data += onepage(url)
print("parsing page %d" %(i+1))
time.sleep(6)
return "".join(data)
def main():
data = parsepage(movie_id, 10)
all_comments = jieba.lcut(data)
words = " ".join(all_comments)
print("正在生成词云图……")
wc=wordcloud.WordCloud(width=1500,height=1500,background_color="white",font_path="./msyh.ttc")
wc.generate(words)
wc.to_file("image.jpg")
print("ok")
main()
效果图(实际效果可能和下图不同,颜色是每次随机改变的):

一起来试试吧~~
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~

往期推文推荐:
1.爬虫俱乐部新版块--和我们一起学习Python
2.hello,MySQL--Stata连接MySQL数据库
3.hello,MySQL--odbcload读取MySQL数据
4.再爬俱乐部网站,推文目录大放送!
5.用Stata生成二维码—我的心思你来扫
6.
Mata中的数据导出至Excel










