作者:赵玉开,十年以上互联网研发经验,2013年加入京东,在运营研发部任架构师,期间先后主持了物流系统自动化运维平台、青龙数据监控系统和物流开放平台的研发工作,具有丰富的物流系统业务和架构经验。在此之前在和讯网负责股票基金行情系统的研发工作,具备高并发、高可用互联网应用研发经验。
在业务开发中经常会遇到各种单号生成, 例如快递单号、服务单号、订单号等等。 这些单号生成往往是业务逻辑处理的第一步, 单号生成出问题,必然导致业务走不下去;另外有多少业务量就会至少有多少的单号生成需求。所以单号生成必须高可用,必须高性能。 另外业务不同需要的单号规则可能也不相同, 所以单号服务还必须具备足够的扩展性。
单号定义
在进入正题之前我们先给单号下个定义, 看几个常见的单号形式。
单号是一个数字和字符组成的序列, 它要满足两个条件: 一个是唯一, 保证唯一才可以作为业务标识; 另一个是符合业务需要的规则。 例如下面三个单号:
-
2017030400001 这个单号由两个部分序列号日期20170304+定长5位补0数字00001。
-
010-6541-00001 此单号分三部分, 中间用减号连接, 第一部分为区号, 第二部分为作业单位号码, 第三部分为作业单位产生作业的序号。
-
QJ000001 则是由字符QJ开头后面跟随数字序列的单号。
单号数字序列部分的生成
上述单号定义中的数字部分通常是一个自增的数字序列。 我们可以通过数据库的自增列、 数据库的列+1方式、 redis或者memcached的INCR指令来生成这种数字的序列。 这四种方式都可以生成序列, 但各自有各自的好处。
1. 数据库自增列的方式
是通过数据库的内部机制生成的, 在普通PC上每秒约可以生成4000个数字序列, 它的好处是每一个数字序列都会保留一条记录, 记录生成使用时间, 缺点是吞吐量一般, 会占用一定的数据库资源, 如下是一种推荐的表结构:
CREATE TABLE `xx_code_sequence` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`generate_time` timestamp NOT NULL
default CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULTCHARSET=utf8;
此表有两列, id列为bigint类型的自增长字段,作为数字序列的值, generate_time时间戳字段可以记录每一个单号的生成时间。生成数字序列的方式用sql说明如下:
begin trans;
insert into `xx_code_sequence`(generate_time)values(current_timestamp);
select last_insert_id();
commit;
说明:
-
表名格式xx_code_sequence,sto_code_0分为三部分sto为ownerKey, code固定不变,0表示表的序号,可以有多个下标不同表来支持更高的并发,
共有几个表需要在开始确认了,确认的依据是需要满足的并发请求。表的个数必须是2的n次方,例如1, 2, 4, 8,16;
-
`id` 即序列的部分值,是通过mysql的自增特性生成的,最终的序列值是id和表序号共同组成的,假定有4个表,序号分别为0,1,2,3;
那么序列值为 id<< 2 | table_index; 即id向左移位2位(移位几位取决于表的个数),然后和表序号求或;
-
`generate_time` 为id生成时间,无其他含义。
不同序号的表可以建在不同的数据库上,当某个序号的表不可用时要报警,并切换到其他表上生成数字序列。
2. 数据库的列+1方式
通过对数据库的某列做+1操作, 来得到唯一的数字序列, 是通过数据库的行锁来保障唯一的, 因为涉及到行锁, 所以这种方式生成序列的单行吞吐量不会太大, 适合需要生成多种(每一种放到一行)不同数字生成需求。 如下是一种推荐的表结构:
create table `xx_rowbased_sequence` (
`owner_key` varchar(32) NOT NULL,
`current_value` bigint NOT NULL,
PRIMARY KEY (`owner_key`)
);
表中的ownerKey列为单号种类标识, current_value为+1操作列。生成序列的方式用sql说明如下
begin trans;
UPDATE `xx_rowbased_sequence`SET current_value=current_value+1 WHERE owner_key=’order-no’;
SELECT current_value FROM `xx_rowbased_sequence` WHERE owner_key=’order-no’;
commit;
需要注意使用此方式生成数字序列事务隔离级别需要是RR。
3. 使用redis/memcached的INCR指令方式
redis/memcached本身可以保证生成数字的唯一性,和高性能。 单一redis服务器每秒可以生成约6w左右的数字序列。 但需要注意redis必须配置主从和存储, 以避免在极端情况下redis节点down机, 导致丢失序列或序列重复。
高可用实现
上面介绍了4种生成数字序列的方式, 但要保证高可用, 单靠一种序列生成方式还是不够的, 我们还需要一种高可用的实现。
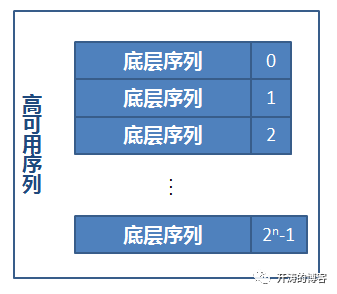
高可用数字序列生成器内部是2的n次方个底层数字序列生成器, 每个底层序列生成器对应一个下标值, 下标值的范围为[0, 2n-1]。 在生成序列时, 轮询底层生成器, 如果正常, 则将生成结果向左移n位, 并与当前底层序列生成器下标取或得到最终序列值。 如果底层序列生成器发生异常, 则将其标记为不可用, 并轮询下一个底层序列生成器, 直到成功。
高可用实现类com.jd.coo.sa.sequence.ha.BitwiseLoadBalanceSequenceGen,其内部有x个底层SequenceGen实现,此类会轮询的调用底层SequenceGen来生成序列,如果某个底层序列生成出错,会从可用列表中移除掉,被移除掉的底层SequenceGen在过xx时间(默认为5分钟)后,可以重新加入到可用列表中。如果内部序列生成单个序列时间超时,并在最近n时间内连续超时x次,会被移动到异常列表,在异常列表中时间超过xx时间后,也会被重新放入可用列表中。
如果一个底层序列被标记为不可用, 过配置时间后会将其恢复到可用列表中, 自动恢复机制可以避免底层序列生成器已恢复可用, 而程序却一直不使用此底层序列生成器的情况。
高可用实现的内部结构图, 如下图所示:
其核心方法如下所示:
public long gen(String ownerKey){
long sequence=0;
int currentPartitionIndex=-1;
SequenceGen innerGen=null;
do{
long startTime=System.currentTimeMillis();
boolean hasError=false;
try{
currentPartitionIndex=getCurrentPartitionIndex(ownerKey);
LOGGER.trace("current partition index {}",currentPartitionIndex);
innerGen=innerSequences.get(currentPartitionIndex);
if(innerGen==SkipSequence.INSTANCE){
LOGGER.warn("current partition index {} is skipped",currentPartitionIndex);
if(availablePartitionIndices.contains(currentPartitionIndex)){
LOGGER.warn("current partition index {} is skipped, remove it",currentPartitionIndex);
availablePartitionIndices.remove(Integer.valueOf(currentPartitionIndex));
}
continue;
}
HighAvailablePartitionHolder.setPartition(currentPartitionIndex);
sequence=innerGen.gen(ownerKey);
onGenNewId(ownerKey,currentPartitionIndex,sequence);
LOGGER.trace("genNewId {} with inner {}",sequence,currentPartitionIndex);
break;
}catch(SequenceOutOfRangeException ex){
LOGGER.error("gen error SequenceOutOfRangeException index {} total available {}",
currentPartitionIndex,
availablePartitionIndices.size());
hasError=true;
LOGGER.error("set {} to SKIP",currentPartitionIndex);
this.innerSequences.set(currentPartitionIndex,SkipSequence.INSTANCE);
onError(ownerKey,currentPartitionIndex,innerGen,ex);
LOGGER.error("after onError total available {}/{}",currentPartitionIndex,
availablePartitionIndices.size());
}catch(Exception ex){
LOGGER.error("gen error index {} total available {}",currentPartitionIndex,
availablePartitionIndices.size());
LOGGER.error("gen error ",ex);
hasError=true;
onError(ownerKey,currentPartitionIndex,innerGen,ex);
LOGGER.error("after onError total available {}/{}",currentPartitionIndex,
availablePartitionIndices.size());
}finally{
long usedTime=System.currentTimeMillis()-startTime;
boolean isTimeout=usedTime>timeoutThresholdInMilliseconds;
if(!hasError&&isTimeout){
onTimeout(currentPartitionIndex,innerGen,usedTime);
}
LOGGER.trace("gen usedTime {}",usedTime);
}
}while(true);
return sequence;
}
使用时配置bean使用即可, 如下spring bean xml配置:
<bean id="highAvailableSequenceGen" class="com.jd.coo.sa.sequence.ha.BitwiseLoadBalanceSequenceGen">
<constructor-arg index="0" value="2"/>
<constructor-arg index="1">
<map>
<entry key="0">
<bean class="com.jd.coo.sa.sequence.AutoIncrementTablesSequenceGen">
<property name="dataSource" ref="dataSourceA"/>
<property name="sequenceTableFormat" value="%s_code_%d"/>
bean>
entry>
<entry key="1">
<bean class="com.jd.coo.sa.sequence.AutoIncrementTablesSequenceGen">
<property name="dataSource" ref="dataSourceB"/>
<property name="sequenceTableFormat" value="%s_code_%d"/>
bean>
entry>
<entry key="2">
<bean class="com.jd.coo.sa.sequence.AutoIncrementTablesSequenceGen">
<property name="dataSource" ref="dataSourceA"/>
<property name="sequenceTableFormat" value="%s_code_%d"/>
bean>
entry>
<entry key="3">
<bean class="com.jd.coo.sa.sequence.AutoIncrementTablesSequenceGen">
<property name="dataSource" ref="dataSourceB"/>
<property name="sequenceTableFormat" value="%s_code_%d"/>
bean>
entry>
map>
constructor-arg>
<property name="timeoutThresholdInMilliseconds" value="200"/>
<property name="timeoutEventCountThreshold" value="3"/>
<property name="timeoutTimeThresholdInSeconds" value="60" />
<property name="onErrorRescueThresholdInSeconds" value="2000"/>
bean>
高性能实现
单号生成只是业务操作的第一个步骤, 业务操作往往是复杂耗时的, 我们必须保证单号生成的性能, 使其几乎不会影响业务时间。
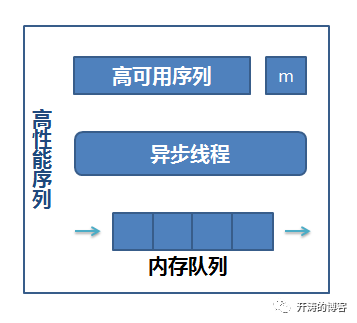
上述介绍的四种序列生成方式都是跨网络通过中间件获得的序列号,要进一步优化其性能,我们需要将序列放在离CPU更近的地方――内存中。我们使用如下两种方式将数字序列放到CPU更近的地方:
-
将内部序列值向左移位n位, 然后序列的最右n位在内存生成,一次生成2的n次方个数字序列, 然后放在内存队列中;
-
异步提前生成:实时计算序列号方法被调用的速度, 然后在异步线程(池)中生成最近x ms需要的序列,放入内存队列中备用
这两种方式并不一定都需要, 置放入内存队列中的数字序列越多,重启时丢失的也会越多。
其内部结构图示如下:
高性能序列使用的bean配置如下:
<bean class="com.jd.coo.sa.sequence.QueuedSequenceGen" id="queuedSequenceGen" init-method="start" destroy-method="stop">
<constructor-arg index="0" ref="haSequenceGen" />
<property name="memoryBitLength" value="3"/>
<property name="enableAsync" value="true"/>
<property name="asyncTask">
<bean class="com.jd.coo.sa.sequence.QueuedSequenceGen$AsyncTask">
<constructor-arg index="0" ref="queuedSequenceGen"/>
<property name="loopSleepInterval" value="20"/>
<property name="reserveTimeInMilliseconds" value="10"/>
bean>
property>
bean>
通过设定memoryBitLength,指定序列的最右的memoryBitLength位在内存中生成以提高生成的效率。 需要注意memoryBitLength值越大则在内存中的序列条数越多, 性能越高, 如果发生重启时丢失的序列也会越多, 要根据情况来设置。 支持异步生成序列值, 异步生成的速度会根据序列值消费速度自适应。
关于可扩展性
单号规则多种多样, 不能每增加一种规则就增加一个需求, 我们需要相对灵活的扩展性。 上述介绍了多种单号数字序列的生成方式, 和数字序列生成的高可用和高性能实现, 他们都实现了同一个接口:
/**
* 根据序列业务类型生成新序列的接口
*
* 生成序列是大致递增的
*
* Created by zhaoyukai on 2016/8/8.
*/
public interface SequenceGen {
/**
* 生成序列
* @param ownerKey 序列业务key
* @return 新序列值
*/
long gen(String ownerKey);
}
有了这个统一的数字序列生成接口, 我们可以扩展多种不同的数字序列生成方式。 或者实现不同的高可用、高性能机制。
另外在本文的开头我们介绍了多种不同的单号生成规则, 要灵活满足这些不同的规则, 我们使用表达式来表达单号的组合规则, 通过将表达式解析成不同的Expression来实现不同单号部分的生成。 下面我们看一个单号表达式的示例, 如下是一个spring bean配置:









