按上方蓝字关注
“硅星人”,带你看不一样的硅谷!

或许我们应该更冷静地看待和解读 DeepMind 的这篇新论文
相信你可能在一些前沿技术媒体上看到,那个训练出人工智能,击败了数十位世界最强围棋棋手的 DeepMind,今天又搞大新闻了。
12 月 5 日,该公司发表了一篇新的论文
,描述了他们训练出的一个新的人工智能
AlphaZero
:
它只用
短短一两天的训练时间
,就击败了世界顶级的日本将棋程序、国际象棋程序等等。
在论文中,该公司宣称 AlphaZero 只用 24 小时训练时间就达到了「超人级」水平
(achieved within 24 hours a superhuman level of play in the games of chess and shogi as well as Go)。
更重要的是,AlphaZero 并非专门型的将棋和国际象棋人工智能,而是一个更具有普遍性的人工智能。同一个程序未经调整,就可以同时应付将棋、国际象棋等不同的棋类游戏。
从各媒体的报道来看,AlphaZero 似乎成为了人类,在实现通用人工智能上的又一个里程碑式进步。
比如机器之心指出
,
DeepMind「希望可以打造出一种通用人工智能,解决更多的人类问题。虽然距离这一圣杯还很遥远,但是这周展示的最新研究成果显示,他们正走在正确的道路上。」
DeepTech深科技则认为
,「在不到 24 小时,同一个电脑程式就可以教会自己玩三种复杂的棋盘游戏,而且是超越人类的水平,这无疑是 AI 世界的新创举。」
可 AlphaZero 究竟厉害在哪儿?为什么如此厉害?
硅星人(微信公众号:guixingren123)研究发现,原来 DeepMind 又做了一个条件极严苛,具有极高独特性和不可复制性的实验。
基本上是利用跟 Google 的关系任性借来一!大!堆!TPU 跑了个分,结果跑出了一个并没有特别厉害的结果。
不信?跟我们一起来看:
1:AlphaZero 是什么?
根据论文,DeepMind 采用的是强化学习技术 (reinforcement learning)。这是一种俗称为“左右互搏”的深度学习技术,简单来说就是软件不停地自己跟自己对弈,在训练中融会贯通。
DeepMind 为人所熟知的 AlphaGo 和 AlphaGo Zero,不但轻松拿下了世界上几乎全部的围棋程序,还击败了世界顶级职业围棋棋手
李世乭和柯洁——这两个人工智能,同样采用了强化学习技术。
而 AlphaZero 的吸睛之处在于其训练时间和前辈相去甚短,对弈的次数也极大减少。
AlphaZero
只需要 20 到 30 万手即可达到
AlphaGo、AlphaGo Zero 多达成百上千万手才能实现的棋技水平。
强化学习本身不是一种新的技术,AlphaZero 和前辈比较起来,在技术架构上也并没有根本性的变化。在训练时,没有像前辈一样手动设置太过于具体的优化参数,而是只输入了基本的游戏规则。
或许我们不应该对 AlphaZero 的自我学习能力太过高估。将这个新的人工智能理解和描述为获得了自我学习能力是不准确的,因为现实的情况并非像人们想象的那样,开发了一个程序,丢给它一个棋盘,24 小时后它的棋艺就超过全人类了。事实上,人类仍需要输入游戏规则。
AlphaZero 实现「24 小时内超越人类并击败主流棋软」这个结果,一个很重要的原因在于 DeepMind 本身在神经网络参数的调校上积累了大量的数据和经验,以至于可以调校更少的、不那么具体的参数,就可以超越 state of the art(目前最优秀)的人工智能。
2:任性的跑分
DeepMind 实现这个令人惊讶的结果,另一个关键的原因在于该公司可以利用最先进的大规模神经网络计算能力。
TPU
(张量计算单元)
是 DeepMind 母公司 Google专为复杂神经网络训练和大规模分布式深度学习应用推出的「处理器」。
DeepMind 论文指出,AlphaZero 本次研究启动了多达 5000 台一代 Google TPU用于创建「左右互搏」的棋局,训练神经网络又利用了 64 台二代 TPU。
无疑,DeepMind 这篇论文的亮点在于「一天」的极短训练时间。
而该公司能够在 AlphaZero 上取得如此优秀的结果,
掌握了 Google 的大杀器才是最关键的,甚至是决定性的
原因所在。

TPU
也正因此,这也是一个实现条件极为严苛,具有明显独特性和不可复制性的研究成果。学术界和行业里几乎没有第二家单位具备复制研究过程和成果的能力。当然,也不能因此说它的前沿性和优秀成果因此被抵消了,只是说它没有这些前沿科技媒体解读的那么“厉害”。
如果一个富二代继承了首富爸爸的万贯家产,宣布自己成为了新首富,似乎也没什么可大书特书的。
(另外,DeepMind 也在论文的注释中澄清,AlphaGo Zero 在最初进行训练时使用的是 GPU。这样,AlphaZero 和前辈相比在性能和实现结果上的巨大领先,也就更容易理解了。)
3 AlphaZero 并没比前代强多少
尽管有以上两点,还是要说,AlphaZero 的确很厉害。
在围棋项目上,AlphaZero 只用了 8 个小时的训练,经过了 16.5 万步就击败了 AlphaGo Lee。注意,这里的 AlphaGo Lee 是去年年初击败
李世乭的 AlphaGo 版本,是这个DeepMind 棋类人工智能家族的初代产品。
它并非是人类最强的围棋程序,因为后来又有了 AlphaGo Zero。AlphaGo Zero 在论文公布当时轰动世界,它尽在数天的时间里就超过了 AlphaGo Lee、后来击败柯洁的 AlphaGo Master。它的成绩如下:
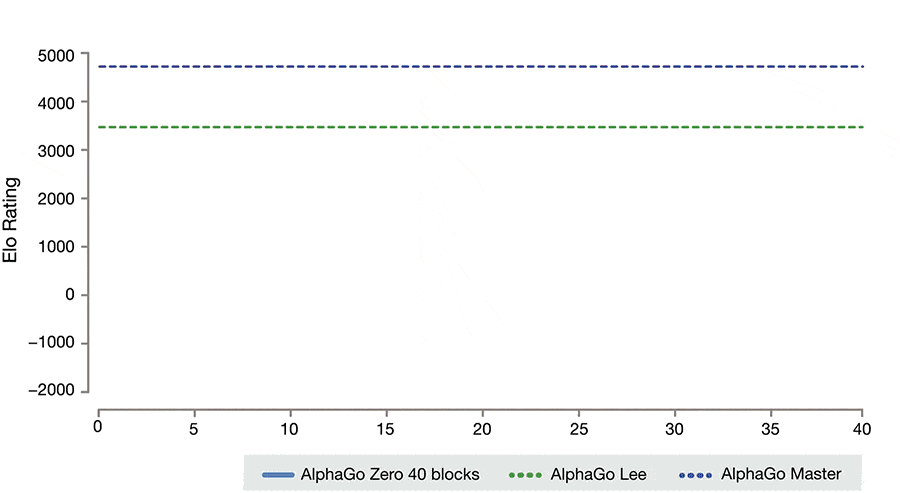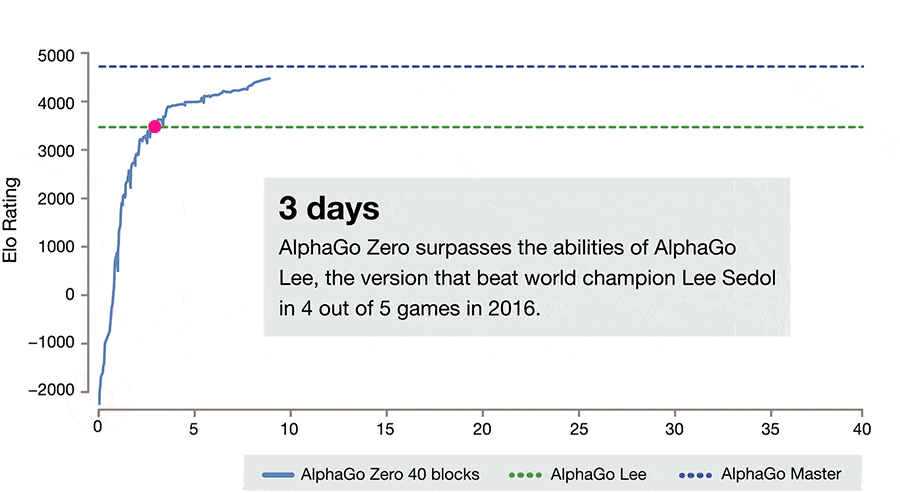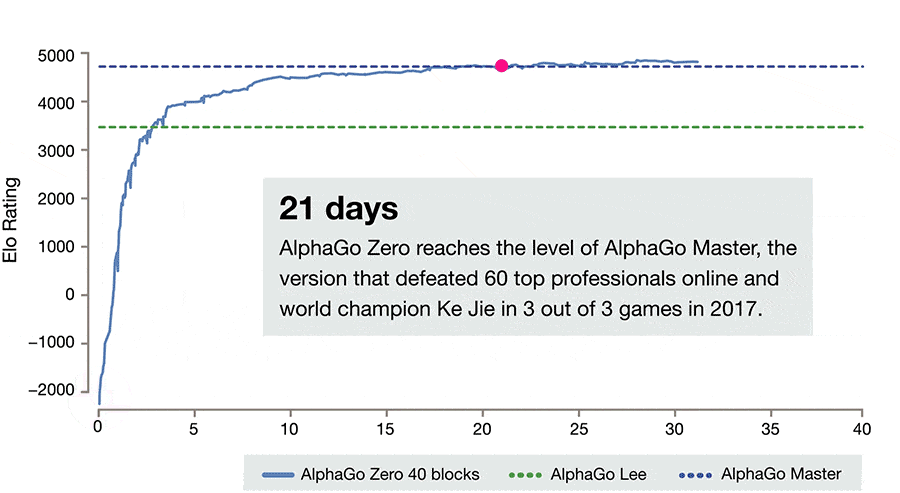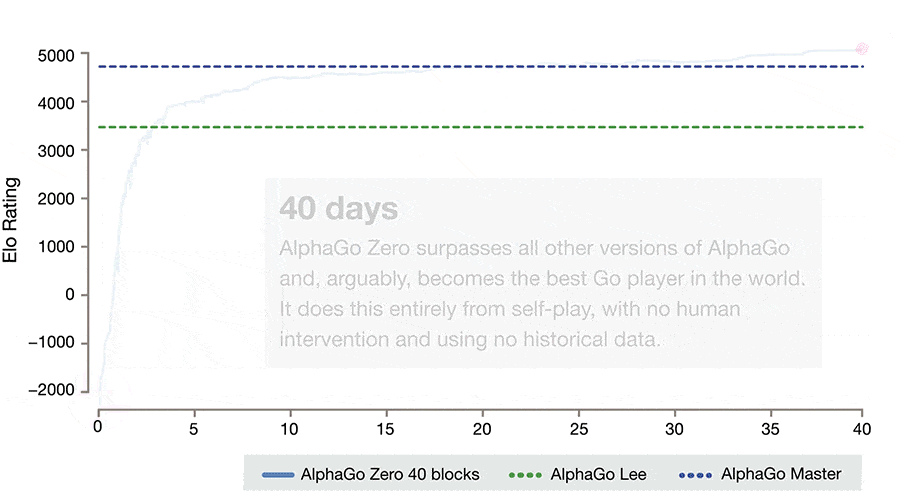
而这个 AlphaGo Zero 实现这个「数天超越前辈」的训练,只用了 4 台 TPU(下图最右)
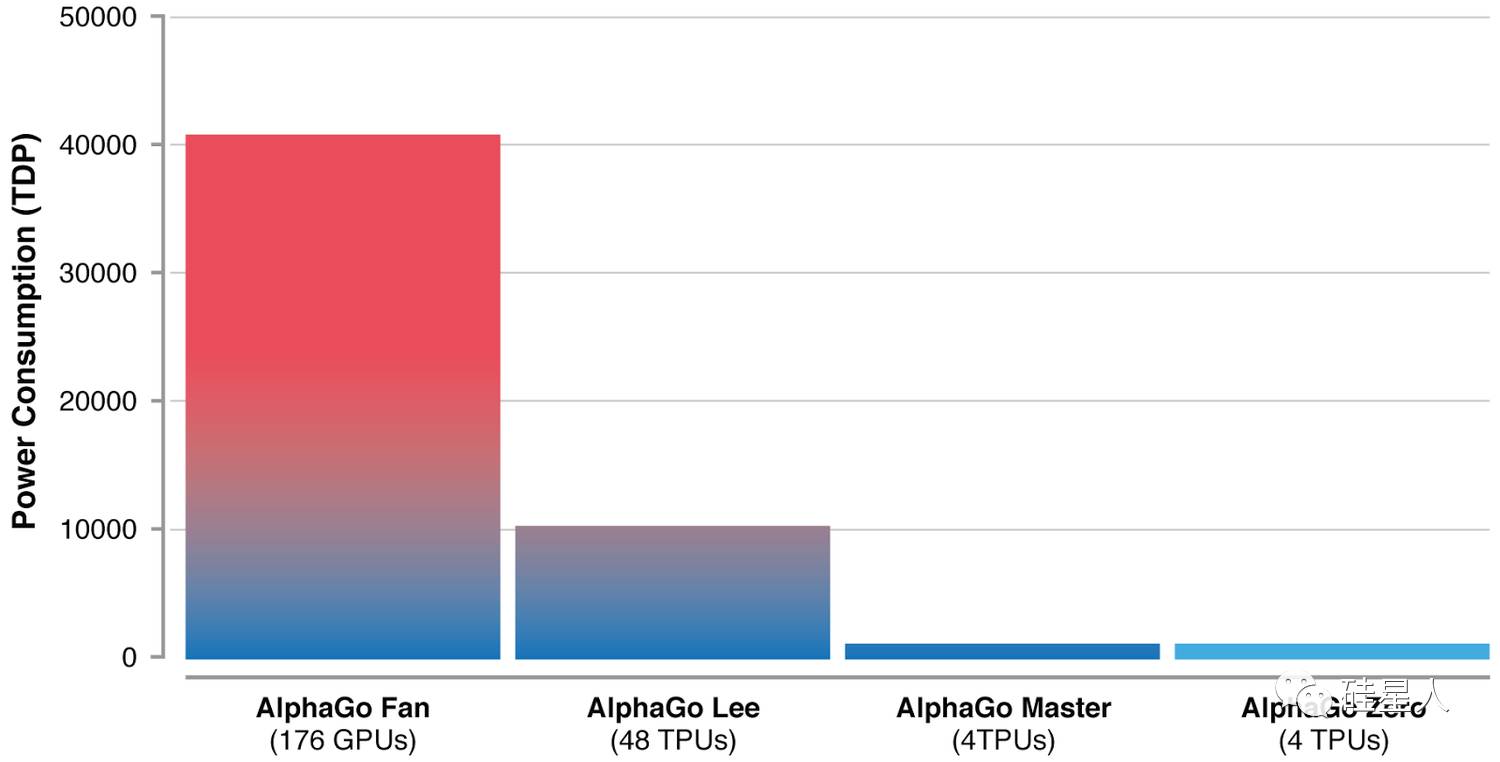
那么,如果我们把今天的 AlphaZero 跟 AlphaGo Zero 拿来横评一下呢?
其实 DeepMind 已经在论文里把答案放出来了。AlphaZero 训练所用的 TPU 数量降低到 4 台,跟 AlphaGo Zero 一样,AlphaGo Zero 训练三天。
结果,双方战绩基本五五开,AlphaZero 执白时胜 31 负19,执黑时胜 29 负 21,维持约 3:2 的战绩。

也就是说,AlphaZero 的确比 AlphaGo Zero 强,但并没强多少。
至于将棋、国际象棋,在这两个项目上 AlphaZero 取得了非常惊人的成果,分别用 2 小时 和 4 小时训练击败了各自领域最强的棋软 Elmo 和 Stockfish。
但前提是,
这是两个规则复杂程度和变数显著低于围棋的游戏。毕竟 DeepMind 已经是一群站在围棋人工智能顶端的男人和女人,轻松拿下将棋和国际象棋,满级玩家闯进新手村,赢多少也不意外了。
4
AlphaZero 真正的亮点:泛化能力
泛化能力是一个术语,根据百科资料,指的是机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
简单来说:同一个人工智能,不经过(复杂的)调整,能比较好地应付几种不同的任务,取得不错的结果,我们就说它的泛化能力比较不错。
在 AlphaZero 的案例里,就是用同一个深度神经网络结构去下将棋、国际象棋和围棋三种规则完全不同的游戏,都能取得
目前最优秀的结果,超过最强的对手(人或棋软)。
但是按照一位人工智能行业人士的说法,AlphaZero 的泛化能力究竟只是在游戏这种完美信息博弈里适用,还是可以适用更大的场景,目前不得而知。
DeepMind 还没有提供足够的证据,证明该公司在这篇论文里提出的新研究方法,除了下棋还能否被用于解决其它更真实和复杂的问题——毕竟不少人在解读类似的论文时,都会开这样的脑洞。
事实上,用更高的视野去看泛化这件事,人们期待看到的是通用人工智能(General AI),一个足以解决大量,甚至所有问题的人工智能系统的出现。
想要实现通用人工智能,目前学术界有不少角度。比如有类脑计算,真正模拟人脑神经元的连接和信息处理方式来设计神经网络结构;也有元学习 (Meta Learning),也即 Learning to learn,让计算机掌握学习这个能力,举一反三等。
强化学习也是一个主流的途径之一,而且由于已经出现了几年时间,目前发展的最好。尽管如此,最近机器学习圈也开始出现“强化学习被高估了”的讨论,而且愈演愈烈。据机器之心报道,就在即将召开的人工智能学术峰会 NIPS 上,已经有人开始嘲讽强化学习和 DeepMind。
该峰会主席伊莎贝尔·基昂 (Isabelle Guyon) 教授认为,机器学习没有魔法,目前的机器学习也没有产生革命性的影响。她表示,「目前所应用的大部分算法,20 年前都已经有了。只不过我们很幸运,赶上了算力达到了一定的标准,让很多需要大量数据的算法有了实现的可能。」在 AlphaZero 的惊人表现的背后,你也能看到这位教授的观点应验。
实现通用人工智能的路还很长,中间难免有热潮和泡沫,而在过去,人工智能已经四次被这样的泡沫所淹没。
对于 DeepMind,
对于 AlphaZero 论文,或许
我们应该更冷静地看待和解读。

长按二维码关注“硅星人”,
让你看到最不一样的硅谷!






