
来源:本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
概要:
一个好的机器学习平台,不光是个铁锹,它必须是个现代化大型自动化挖掘机。只有让大数据以更廉价的方式得到,才能让人工智能更好走向最高峰。
科技巨头加注人工智能仿佛是场竞赛。
前不久,Uber正式推出机器学习平台Michelangelo,希望通过这个平台全面处理工作流程,并推动AI普及化。恰巧就在当天,量子位在人工智能计算大会(AICC)上注1,遇到并专访了Uber机器学习负责人王鲁明。
对于这个机器学习平台的意义,Uber机器学习负责人王鲁明介绍说,Top级企业真正的核心竞争力就是数据和平台,如果我们把大数据看成一个金矿,那这个平台就是挖掘金矿的工具。
“一个好的机器学习平台,不光是个铁锹,它必须是个现代化大型自动化挖掘机。只有让大数据以更廉价的方式得到,才能让人工智能更好走向最高峰。”
关于Uber这个名为Michelangelo的机器学习平台,其负责人王鲁明还向量子位分享了更多幕后故事。
能做什么?

我们先从结果上来看,Michelangelo到底可以做些什么?
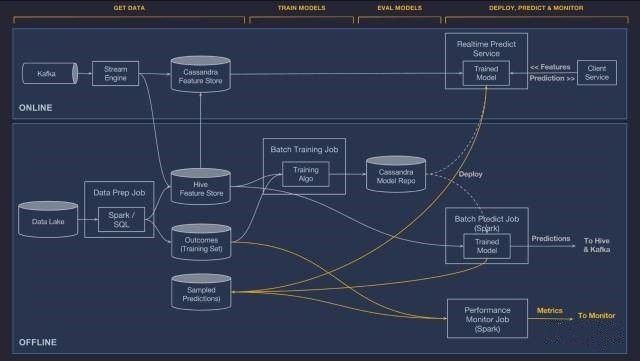
Uber方面的说法是,Michelangelo的主要作用是能够让内部团队可以无缝构建、部署和运作适合Uber量级的机器学习解决方案,可以覆盖端到端机器学习工作流,包含:管理数据、训练、评估和部署模型,以及监控预测。该系统还支持传统的机器学习模型、时间序列预测和深度学习。
在Uber内部,Michelangelo是Uber工程师和数据科学家实际使用的机器学习系统,有几十个团队使用它构建和部署模型。由于该系统部署在多个Uber数据中心上,还会影响到专门的硬件,以及对Uber最高加载量的在线服务提供预测。
归根结底,Michelangelo的出现,把Uber内部分散在各个业务团队中的机器学习开发需求集中起来,减少重复开发的资源浪费。
一开始走了弯路
王鲁明称,这个机器学习平台创建于2015年年底,当时最大的需求来自大量团队在实际工作中需要用到机器学习。
在这个平台推出前,Uber内部每个团队都“各自为政”——自己做自己的机器学习开发,所以中间必然有大量重复的工作,效率也比较低。
这直接促成了Michelangelo建立,不过也并不意味着一路顺利。
现在总结起来,最大的弯路在于对深度学习不够专注。而围绕非深度学习切换了不同的平台,比如H2O之类的,最后才决定使用Spark ML作为自己的机器学习平台。
“当时的出发点是尽可能使用开源资源,在开源的基础上有一些Uber的开发和创新,也尽可能把这些开源和创新回馈给整个社区。在Spark ML我们做了很多工作,比如加了很多新的算法,像我们前段时间加了Siri的算法,这个是原来Spark ML不支持的。”王鲁明透露说。
其后直到2016年7月,Uber机器学习平台才加入了对深度学习的支持。这才算真正让Michelangelo走上了正轨。
现在,有几十个来自Uber的内部用户通过Michelangelo来满足自己在机器学习方面的要求,并且让任务变得更富效率,几乎所有的测试工作,都可以在Michelangelo上完成。
“具体业务团队只需要专注他们所需的业务需求上,然后思考用什么样的算法去解决业务需求的问题。他们不需要考虑数据从哪里来、需要多少台机器、机器在何方?这些问题都由Michelangelo承担。”
王鲁明进一步明确说,Michelangelo实际上提供的就是一个端到端的解决方案,可以帮助Uber内部团队完成挑选数据、建立模型、训练模型、模型比较、管理,最后把最佳模型进行分析、计算和处理。
因为Uber的业务涉及全球成百上千个城市,而且每一个城市还可以按照区域往下建模型,因此一个“用户”可能就会有几千个模型,这就要求Michelangelo能够给这几千个模型同时支持、平衡和分析。
过去,涉及较大数据的模型,单机训练可能要将近1个月的时间,但现在整个效率已经大大提升,整个技术从定向到开发,时间周期大大缩短。
王鲁明举例说,内部一个项目此前花了4个月时间,但换到Michelangelo后,整个周期变成了1个月。
实际应用
对于Michelangelo的实际应用,王鲁明举了几个例子。
一是Uber的无人驾驶业务,之前围绕深度学习方面的工作都在其他平台或买一台4GPU的单机进行训练,但现在已经完全转到了Michelangelo上。
二是Uber的街景车业务,在获取了众多高精度相片中,需要对图像中的价值信息进行提取。一开始街景车团队在Caffe1.0上进行,不过只有单机版的Caffe1.0显然拖慢了效率。
20人规模的团队,需要在模型和机器之间的管理、共享和资源分配上浪费精力,甚至需要人工去修改机器是否在用,非常落后且低效。
而换到Michelangelo之后,“用户”不用再去记住模型和具体机器的对应关系,整个平台互联互通,就好似在一台机器上一样。
以上都是深度学习的案例,Uber还有一些非深度学习解决的问题。
比如有人叫车时,周围有十几个司机,选哪个司机来与乘客匹配?如果没有选好的话,司机和乘客都有可能取消,而取消就是对所有人都存在损失——即便没有经济上的,也有时间成本和用户体验上的。
所以这个模型核心要解决的问题是最大概率减少“取消”的操作,“取消率”越低,效果越好。
类似的模型也应用于Uber Eats上,其中关于食物的推荐、下订单后所需时长,其中都是机器学习的应用,而目前所有这些机器学习的应用,都在Michelangelo上实现。
深度学习非万能
王鲁明也解释了为什么Michelangelo平台并非全部使用深度学习的原因。
一方面跟深度学习目前存在的“瓶颈”有关,另一方面与Uber实际应用需要密不可分。
这位Uber机器学习负责人表示,深度学习的第一个问题是“不好解释”:为什么起作用、为什么不起作用,无据可查。
另一个问题是在具体应用中模型层数的问题,以自动驾驶举例,可能一千层在测试中效果很好,但真正实际应用中,40毫秒之类的时间内,如此深的计算来不及,即便配上最好的GPU,也迫使你需要把模型层级变得更窄,这就会造成限制。
目前,对于上述情况,Uber内部的解决方案主要通过降低计算量和提升计算力两大方面来展开。









