选自Journal of Geek Studies
作者:Henrique M. Soares
机器之心编译
参与:机器之心编辑部
精灵宝可梦(Pokémon)取得举世瞩目的成功已逾 20 年,本文将通过机器学习的方法来解决「那个精灵宝可梦是谁?」的难题。本文提出了一个机器学习的预处理及分类流程,将会使用卷积神经网络对精灵宝可梦进行分类。本文作者为巴西圣保罗的独立研究者 Henrique M. Soares。此外,感兴趣的读者还可以点击文末「阅读原文」下载本文的 PDF 版本。
计算和图像识别
计算机被发明以来 [1],在日常生活中的使用就愈加频繁。最初它们的应用程序局限于解决数学问题,以及弹道学和密码学中的军事应用;而如今它们正在飞速地多样化发展。迄今机器已经在很多项任务中超越了人类,最近的例子便是 AlphaGo 打败了世界围棋冠军(Go Game Guru, 2017)。
这一成就证明了机器在智能应用方面的显著进步。具有几乎无限的组合 [2] 的围棋是无法用「蛮力」[3] 轻易解决的——而「蛮力计算」已经被计算机用在其它一些完美信息博弈(perfect information games)来对抗人类。
但请不要沮丧,并非所有人都会在未来与机器人的斗争中失败,因为计算机仍然还在学习人类与生俱来的能力:图像和模式识别。不管目前的计算机在这方面有多么擅长,人类也仍然能比它注意到更多:即使图 1 仅显示了一辆汽车,却存在不寻常的情况。

图 1:撞到树的汽车。机器(至少目前)还写不出这样的文本。(该图像提取自维基共享资源;Thue,2005)
但计算机就要赶上来了!机器学习技术(特别是监督学习方法)的进步,以及不断增长的用于此类算法的数据,都已让这一领域实现了巨大飞跃。2015 年,MSRA 团队训练了一个 150 层的残差神经网络集合,在同年的图像分类挑战中达到了 62%的平均精度,该挑战使用了一个包含超过 1000 个不同对象的数据集(Large Scale Visual Recognition Challenge, 2015)。

图 2:一些简单的东西对计算机而言可能会很难。
(「任务」;XKCD,https://xkcd.com/1425)。
所以我们想知道……对于过去 22 年中由世界各地的孩子们所解决的难题,机器能够办到吗?

图 3:那个精灵宝可梦是谁?(精灵宝可梦动画系列的截图)
精灵宝可梦
精灵宝可梦是一个十分成功的游戏及动画系列,它的目标受众是年轻人(尽管作者本人并不同意这种分类)。田尻智(Satoshi Tajiri)在 1995 年创建了这个系列,并为任天堂的掌上游戏机 Game Boy 发行了两款游戏。在游戏中,玩家将扮演一位精灵宝可梦训练师,捕捉并和目标生物战斗。这个系列极其成功,并很快红遍了世界(Wikipedia, 2017b)。
这个系列最初有 151 只妖怪(图 4),但如今的游戏已经完成了第七次迭代,共有 802 只妖怪。

图 4:从左到右分别为妙蛙种子(Bulbasaur)、小火龙(Charmander)和杰尼龟(Squirtle)
每个精灵宝可梦都通过所属的一或两种属性来表现其「元素亲和力(elemental affinity)」,以及相对于其他类精灵宝可梦的优缺点。这个功能在游戏玩法中至关重要,它能够建立一个深度且复杂的石头-剪刀-布机制,而这恰恰是战斗系统的基础。游戏中有 18 种属性(第一个游戏只有 15 个),如图 5 所示(Bulbapedia,2017)。

图 5:使用它们的惯用背景颜色所描绘的 18 种属性的精灵宝可梦。
本文检测了卷积神经网络(也称为 ConvNet)在指定精灵宝可梦游戏中的精灵后,执行宝可梦属性分类任务的表现。我将会展示收集的数据、预处理和训练流程,并会以所选模型的性能指标结束。所有的数据、实现代码、结果,以及对所有步骤做出解释的 Jupyter Notebook 都可以在一个 GitHub 库找到:
我将使用游戏精灵来训练模型。而从 Veekun(2017)能够获得数据集(精灵包)。这些精灵包拥有游戏的第 1 代到第 5 代的精灵。虽然又发布了新的游戏(和新的妖怪),但它们使用了三维动画模型,因此从游戏中提取资源会更困难,将其以转换成机器学习方法所支持的格式也会更难。因此本文将仅使用到第五代游戏为止的精灵宝可梦(共有 649 个)。
随即可以发现,游戏机硬件和软件的不同,造成了游戏间细节级别上的差异。任天堂发布的第一代掌上游戏机 Game Boy,尽管在数据集中存在一些色调信息,但单个精灵的色调几乎没有发生变化(如 Bulbasaur 是绿色,Charmander 是红色,而 Squirtle 是蓝色;如图 6 所示)。随着研究从 Game Boy Advance 进展到到任天堂 DS,我们能发现其细节水平不仅体现在色调方面,还体现在形状方面。
初看之下,我们还能识别图像分类任务中所遇到的一些典型问题。这些图像大小不同。尽管所有的图像的长宽比保持在 1:1,但它们已经从第一代的 40 像素宽度发展到了第五代的 96 像素宽度(请注意图 6 中每个精灵边界的刻度)。

图 6. 正如游戏和各代版本中所见,这是三个精灵宝可梦的变体样本。
此外,并非所有精灵在每个图像中都会填充相同的空间,最老一代的精灵似乎会填充图像相对更大的部分。这在相同代之间也会发生,特别是在更新游戏中,往往会涉及每个精灵宝可梦的大小差异以及进化(图 7)。

图 7:第五代游戏中的妙蛙种子的进化路线。随着精灵宝可梦进化,它也会变大,就会填充图像中更大的部分。
图像居中(Image Centering)
为了解决这个问题,我们要应用一些计算机视觉技术来识别图像中的主要对象,给它定下边界框,并将图像居中在这个框上。这个流程是:
1. 将图像转换为灰度。
2. 在图像上应用 Sobel 滤波器来突出精灵的边缘。Sobel 滤波器是一个 3×3 的卷积核(convolutional kernel,之后会介绍这些便利的工具的更多信息,也也可参见 Sckikit-Image, 2017),其会尽量逼近图像的梯度。对于给定的图像'A',Sobel 算子被定义为:
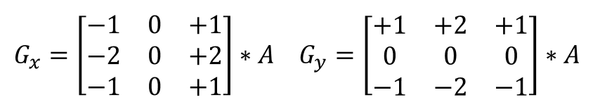
3. 填充图像中的孔,获得精灵宝可梦的轮廓。
4. 计算轮廓的凸包(Convex Hull),即包括轮廓中所有像素的最小凸多边形。
5. 根据之前计算的凸包定义矩形边界框。
6. 选择边界框内的内容,并将大小调整为 64 x 64 像素。

在遵循上述描述的流程之后,我们得到了新的精灵,其使图像上的精灵的填充率最大化。这些步骤是通过使用 skimage 完成的(skimage 是一个用于 Python 编程语言的图像处理库)。图 8 显示了第一代三个初始精灵和妙蛙花(Venusaur)的居中转换流程。
我们所提出的流程对于当前所面临的任务非常有效。由于其有着非常简洁的白色背景且我们的图片是非常简单的精灵,这样的结果也在我们的预料之中。
最后,让我们将我们的方法应用于我们所有的精灵和图像。图 9 显示了一群精灵宝可梦的结果。

图 9:几种第五代精灵宝可梦的居中处理结果
目标变量
现在我们有了全部的精灵宝可梦的图像来建立我们的图像数据集,我们必须根据我们想要预测的变量对其进行分类。在这篇论文中,我们将尝试仅使用每个精灵宝可梦的图像并根据其正确的属性对其分类。例如,在图 10 中,我们尝试使用边界框内的图像将精灵宝可梦分为 18 种属性之一,试图匹配其真实属性(在每个精灵宝可梦下方显示)。

图 10:精灵宝可梦和其各自的属性的样本。 顶行:妙蛙草 (左) 和波波 (右)。底行:大钢蛇 (左) 和菊石神 (右)
但是有一个问题。大多数精灵宝可梦,像图 9 和 图 10 的那些精灵宝可梦有双重属性。也就是说,它的真实属性将是那 18 种属性列表里的两种不同属性的组合。例如,在图 10 中,妙蛙草是草属性和毒属性,同时具有两种属性的优缺点。
考虑到这一点,我们必须对组合的属性进行目标分类。即使我们忽视属性顺序(也就是说[火与岩石] 和 [岩石与火] 是一个属性),我们最终还是会得到 171 个可能的类。(事实上,这个数字会小一点,154,因为并不是所有的组合都在游戏中存在)。
更糟的是,一些组合非常少见(图11),只有一个或者两个精灵宝可梦,从而限制了可用的学习样本。

图11:一些罕见的属性组合。顶行:熔岩蜗牛(Magcargo (左) )和溜溜糖球(Surskit (右)); 底行: 花岩怪(Spiritomb (左) )和席多蓝恩(Heatran (右))
由于上述原因,在本文中我选择忽略属性组合。因此,我们只考虑精灵宝可梦的主要属性。例如,在图 10 中,我们将有:妙蛙草:草属性、波波:一般属性、大钢蛇:钢属性、 菊石神:岩石属性
模型训练
选择模型
我使用卷积神经网络(Convolutional Neural Network)作为我们的数据集的预测器。神经网络是通常用于机器学习的许多种预测模型中的一种,包括被称为神经元的简单单元的互连网络。基于与生物系统内部运作的不严格的类比,神经网络可通过这些简单的单元学习复杂的功能和模式。
在其最简单的形式中,神经元只是其输入的线性函数,接着是非线性激活函数(图 12)。然而,通过一些层的组合,神经网络能够对目前的独立和非独立变量之间愈发复杂的关系进行建模。

图 12:神经网络的基本单元。

图 13.:一个稍微复杂的结构,带有一个隐含层的神经网络。
神经网络不是最近才提出的,1940 年就存在对其的研究了( Wikipedia, 2017a)。然而,直到近年来随着计算能力的进步以及用于其训练的反向传播算法的发展,才使得其使用变得更加广泛。
好了,这足以让我们明白一点神经网络了。但是,
「
卷积(convolutional)
」
是什么意思?让我们先来谈一谈核(Kernel)。
在图像处理中,一个核(也被称为卷积矩阵(Convolution Matrix)或掩码(Mask))是用于模糊、锐化、边缘检测等的小矩阵。通过对适当的内核计算矩阵卷积,产生新的图像从而获得效果。我们已经在我们的预处理流程中看到了一个在本文中使用的核,其中我们应用了 Sobel 核来检测精灵的边缘。

图 14:Sobel 核对妙蛙花图像的影响
卷积运算可以被看作是核在我们的图像上的滑动。核中的值以元素的方式乘以图像中下面的值,并将结果相加以产生该窗口上卷积的单个值。(关于卷积运算更好的解释请参考
http://setosa.io/ev/ image-kernels/)。
在图 15 中,我们应用垂直 Sobel 滤波器来检测颜色强度的明显变化。(在我们的灰度图像中,范围在 120 到 255 内)。
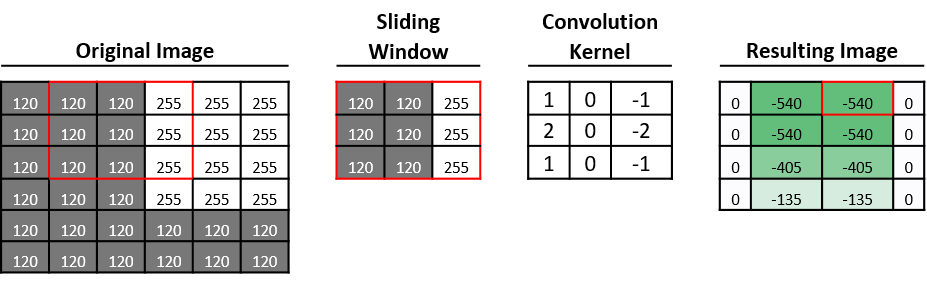
图 15 。卷积示例。图像中突出显示的红色区域正在使用垂直边缘检测器进行卷积,从而得到结果矩阵(resulting matrix)中红色框内的值。
但是这是怎么回事!这些核与神经网络有什么关系?关系大得超出了我们的想象!一个神经网络里的卷积层只是一种聪明的排列神经元及其相互连接的方式,以实现能够通过监督学习识别这些滤波器的架构。(同样,关于整个神经网络的东西可以参考http://cs231n.github.io/convolutional-network s/)在我们预处理流程中,我们使用了特殊的核,因为我们已经知道了一个十分擅长当前任务的核,但是在卷积网络中,我们让训练算法去找到那些滤波器,并在后续层中将其组合起来以实现越来越复杂的特性。
我们的神经网络的架构
对于我们的精灵宝可梦分类的任务,我使用了一个不太深的卷积网络

图 16:在本文中使用的神经网络的架构
图像的每一层在我们的卷积网络中表示为一个层。在每一个层后,我们获得表示该层输出的状态张量(张量的维度列在每个层的右侧)。
然后一个卷积层应用这些卷积运算。在第一层中,我们对输入图像应用 32 个大小为 5 的核,产生了 32 个大小为 60 x 60 的输出。(由于边界效应,每个卷积图像尺寸有所减少)
我们还使用了最大池化层( max pooling layers),通过获得其最大值简单地将张量区域减少到单个区域(图 17)。因此,在应用一个 2 x 2 的最大池化层之后,我们得到原始大小四分之一的张量。
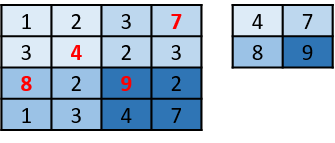
图 17:最大池化运算的示例
最后,我们将张量展平为一维,并将其连接到密集连接层以用于预测。我们最终层的大小为 18,与输出域大小相同。
训练和检验
为了实现我们的模型训练,我们要将数据集分为两部分:
(1)
「
训练数据集(training dataset)
」
将使用我们的训练算法从数据中学习模型参数;(2)
「
验证数据集(validation dataset)
」
将用于评估未知的数据的模型性能。这样,我们将能够识别过拟合问题(相信我,我们将看到很多过拟合[4])。
但是我们不能随意地选择精灵的随机样本。来自同一精灵宝可梦的精灵,在不同游戏中彼此非常相似,特别是在同一代游戏之间(图18)。

图18:来自精灵宝可梦白金版(左)和钻石版(右)的大比鸟(Bird Jesus)。等等...这是另一回事吗?
框1:表现测试指标
本文我们使用三个指标来评估我们的模型表现:
(1)准确度(Accuracy):获得精灵宝可梦正确属性分类的预测的百分比;
(2)精度(Precision):归类为真正属于该类(属性)的图像的百分比;
(3)召回率(Recall):归类为该类(属性)的图像的百分比。
准确度使我们能够得到模型的总体质量,精度和召回率用于衡量我们的模型的每个类的预测。
如果我们随机选择精灵,则会有使用与训练集相同精灵污染测试集的风险,这将导致对未知数据的模型表现的高估。因此,我对精灵宝可梦样本进行了挑选。也就是说,我将整个精灵宝可梦分配到了同一个集合,而不是分配单个精灵。这样,如果喷火龙被分配给测试集,它对应的所有精灵都将跟随,从而消除了污染的风险。
我使用了20%的精灵宝可梦作为测试样本,80%作为训练集,也就是有 2727 个精灵用来训练。
第一个模型:裸骨训练
在第一次尝试中,我用原始精灵的图像训练算法,同时保持训练/测试分开。该算法训练超过了20个 epoch [5],总共花了大约一分钟[6]。第一个训练获得的结果在图19中给出(参见框1表现度量查看解释)。
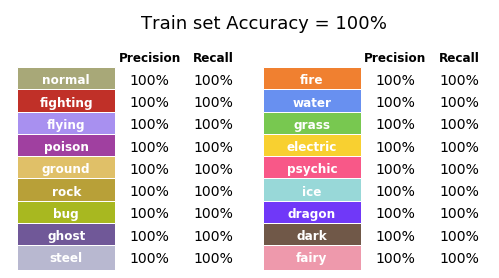
图19:第一次尝试中训练集的表现
结果令人吃惊!我们得到的所有分类都是正确的!但是这些指标能很好地估计未知数据的模型性能吗?那些指标是否显示,我们的模型学习训练样本,但对新数据适应不佳?扰乱警报:确实如此。让我们来看看它:图20展示了那些和我们验证集相同的度量。
看来,我们的模型确实过拟合了训练集,即使它的表现优于随机猜测。

图20:第一次尝试验证集的表现
但等一下......为什么我们没有任何飞行属性的精灵宝可梦?事实证明,只有一个精灵的主要属性是飞行(图21,龙卷云(Tornadus)),它被包括在了训练集中。

图21:在飞行属性中,龙卷云是独一无二的。
第二个模型:图像增强
我们并不惊讶测试集获得的第一个模型性能不佳。正如在介绍中所说,图像分类是计算机要解决的一个困难问题。我们的数据集太小,没有足够的变化,以致我们的算法不能在更广泛的应用程序中学习能够泛化的特征。
为了至少解决部分的问题,让我们应用一些图像增强技术。这涉及对训练图像应用随机变换,从而增强它们的变化。人类将能够识别皮卡丘,无论其方向如何(颠倒,倾斜到一侧等),我们希望我们的模型能达到相同的效果。因此,我对我们的训练数据集采用以下范围的变换(图22):(1)随机旋转高达40度;(2)随机水平移位高达20%的图像宽度;(3)随机垂直移位高达20%图像高度;(3)随机放大高达20%;(4)在垂直轴上取倒影;(5)在0.2弧度范围内的剪切变换。

图22:通过在图像增强流程获得的图像,某只妙蛙种子精灵。
我将这个流程应用到训练集中的所有精灵,为每个精灵生成10个新图像。这样,我们的训练集扩展到27,270张图像。但是,这就足够了吗?至少训练30 epoch后(这次时间花的稍长,总共超过10分钟),我获得了以下结果(图23)。

图23.第二个模型的训练集的表现。
等一下,我们模型的性能下降了吗?这个图像增强的东西不能改善我的模型?这有可能,但是,让我们不要根据我们训练集的表现就做假设。整体性能的下降是由于我们训练集变化的增加,如果能在验证集上取得更好的表现(图24),这或许是个好消息。
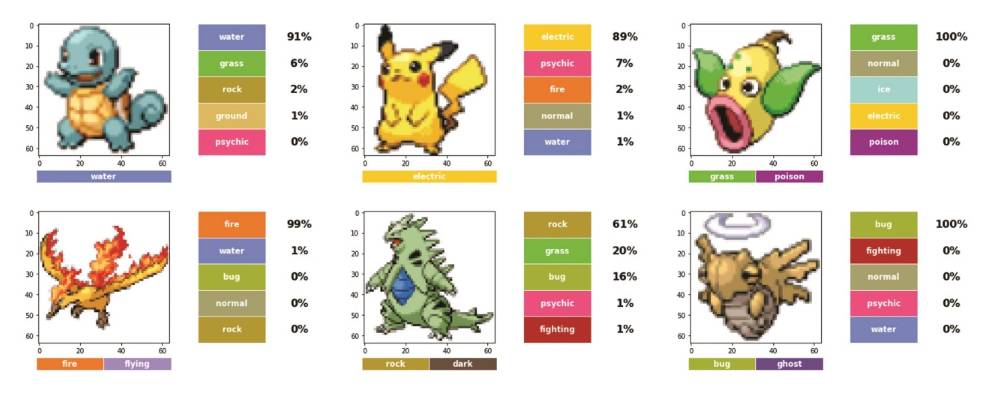
图24.第二个模型的验证集表现。
在这里,有了!图像增强实际上有助于提高模型表现。其中,准确率提高了14个百分点,达39%。我们可以继续尝试获得一个更好的模型,处理模型超参数或尝试网络架构,但我们就到此为止吧。
仔细观察分类









