点击上方蓝色“
石杉的架构笔记”,选择“设为星标”
回复“PDF”获取独家整理的学习资料!



随着微服务架构的兴起,越来越多的公司会在实际场景中遇到分布式事务的问题。特别是在金融应用场景,几个跨进程的应用共同完成一个任务,就更离不开分布式事务的参与。而对于分布式事务而言,2PC、
TCC
也是经常被提到了,不过在面对长业务流程,并且很难进行
TCC
改造的场景,会选择使用
Saga
分布式事务。今天会给大家介绍
Saga
实现分布式事务的内容:
随着互联网的快速发展,原来的单体应用已经很难支撑大流量高并发的请求了,因此软件系统由原来的单体应用逐渐向分布式过度,如图1所示,左边的
Web
App
包含了UI和服务的模块,在转变以后会对应右边的微服务架构,服务之间存在关联地相互调用。
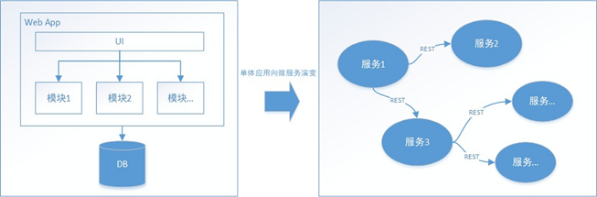
图
1
单体到分布式的系统架构过渡
在进行分布式部署之后,会存在多个服务共同完成一个事务操作,并且这些服务彼此都存在于不同的服务器或者网络环境,服务之间需要通过网络远程协作完成事务称之为分布式事务。例如:银行转账业务、下单扣件库存等。
在分布式事务场景下,如果对数据有强一致性要求,会在业务层上才去
“
两阶段提交
”
(
2PC
)
的方案。
如果保证最终一致性的话可以采取
TCC
(
Try
Confirm
Cancel
)
模式
。虽然
TCC
保证最终一致性的模式被业内广泛使用,但是对于某些分布式事务场景,
流程多、流程长、还可能要调用其它公司的服务。特别是对于不可控的服务(其他公司的服务),这些服务无法
遵循
TCC
开发模式
,导致
TCC
模式的开发成本增高
。体现在具体场景中,以金融核心的业务为代表(渠道层、产品层、集成层),其特点是:流程多、流程长、调用不可控服务。同时也是应为流程长,事务边界太长,加锁时间长,
使用
TCC
模式
会影响并发性能。
鉴于此类业务场景的分布式事务处理,提出了
Saga
分布式处理模式。
Saga
是一种
“
长事务的解决方案
”
,更适合于
“
业务流程长、业务流程多
”
的场景。特别是针对参与事务的服务是遗留系统服务,此类服务
无法提供
TCC
模式下的三个接口,
就可以采用
Saga
模式。
其适用于的业务业务场景有,金融机构对接系统(需要对接外部系统)、渠道整合(流程长)、分布式架构服务等。其优势是一阶段提交本地事务,无锁,高性能;参与者可异步执行,高吞吐;补偿服务易于实现,因为一个更新操作的反向操作是比较容易理解的;当然其也存在缺点,就是不保证隔离性。
1987
年普林斯顿大学的
Hector Garcia-Molina
和
Kenneth Salem
发表了一篇
Paper Sagas
,讲述的是如何处理
long lived transaction
(长活事务)。
Saga
是一个长活事务可被分解成可以交错运行的子事务集合。其中每个子事务都是一个保持数据库一致性的真实事务。
在这位老兄的论文中提到,
每个
Saga
由一系列
sub-transaction Ti
组成
。
每个
Ti
都有对应的补偿动作
Ci
,补偿动作用于撤销
Ti
造成的结果
。这里可以理解为,针对每一个分布式事务的每个执行操作或者是步骤都是一个
Ti
,例如扣减库存是
T
1
、创建订单是
T
2
、支付服务是
T
3
。那么针对每个
Ti
都对应一个补偿动作
Ci
,例如回复库存
C
1
、订单回滚
C
2
、支付回滚
C
3
。
Saga事务有两种恢复策略:
向前恢复
(
forward recovery
)
,
也就是
“勇往直前”。
对于执行不通过的事务,会尝试
重试事务,这里有一个假设就是每个子事务最终都会成功。这种方式适用于必须要成功的场景,
如图
2
所示,上面的图例,子事务按照从左到右的顺序执行,
T
1
执行完毕以后
T
2
执行,然后是
T
3
、
T
4
、
T
5
。

图2
Saga事务执行的策略
事务恢复的顺序也是按照:
T
1
、
T2
、
T3
、
T
4
、
T
5
的方向进行,如果在执行
T
1
的时候失败了就重试
T
1
,以此类推在哪个子事务执行时失败了就执行哪个事务。因此叫做
“勇往直前”。
向后恢复
(
backward recovery
)
,在执行事务失败时,补偿所有已完成的事务,
是
“一退到底”的方式
。
如图
2
所示,下面的图例,子事务依旧从左往右执行,在执行到事务
T
3
的时候,该事务执行失败了,于是按照红线的方向开始执行补偿事务,先执行
C
3
、然后是
C
2
和
C
1
,直到
T
0
、
T
1
、
T
2
的补偿事务
C
1
、
C
2
、
C
3
都执行完毕。也就是回滚整
个
Saga
的执行结果。
上面介绍了Saga的概念和事务恢复方式,每个事务存在多个子事务,每个子事务都有一个补偿事务,其在事务回滚的时候使用。由于子事务对应的操作在分布式的系统架构中会部署在不同的服务中,这些子事务为了完成共同的事务需要进行协同。
实际上在
启动
一个S
aga
事务时,协调逻辑会告诉第一个
S
aga
参与者
,也就是子事务,去执行本地事务。事务完成
之后S
aga
的
会按照执行顺序调用S
aga
的下一个参与的子事务。这个过程会一直持续到
S
aga
事务执行完毕。
如果在执行子事务的过程中遇到子事务对应的本地事务失败,则
S
aga
会按照相反的顺序执行补偿事务。
通常来说我们把这种Saga执行事务的顺序称为
个
S
aga
的协调逻辑
。这种协调逻辑有两种模式,
编排(
Choreography
)和控制(
Orchestration
)
分别如下:
编排(
Choreography
)
:参与者(子事务)之间的调用、分配、决策和排序,通过交换事件进行进行。是一种去中心化的模式,参与者之间通过消息机制进行沟通,通过监听器的方式监听其他参与者发出的消息,从而执行后续的逻辑处理。由于没有中间协调点,靠参与靠自己进行相互协调。
控制(
Orchestration
)
:
S
aga
提供一个控制类,其方便参与者之前的协调工作。事务执行的命令从控制
类发起,按照逻辑顺序请求
Saga
的参与者,从参与者那里接受到反馈以后,控制类在发起向其他参与者的调用。所有
Saga
的参与者都围绕这个控制类进行沟通和协调工作。
下面通过一个例子来介绍这两种协调模式,假设有一个下单的业务,从订单服务的创建订单操作发起,会依次调用支付服务中的支付订单,库存服务中的扣减库存以及发货服务中的发货操作,最终如果所有参与者(服务)中的操作(子事务)完成的话,整个下单事务就算完成。
编排(
Choreography
)
,由于没有中心的控制类参与参与者操作之间的协调工作,因此通过消息发送的方式进行协调。
如图
3
所示:
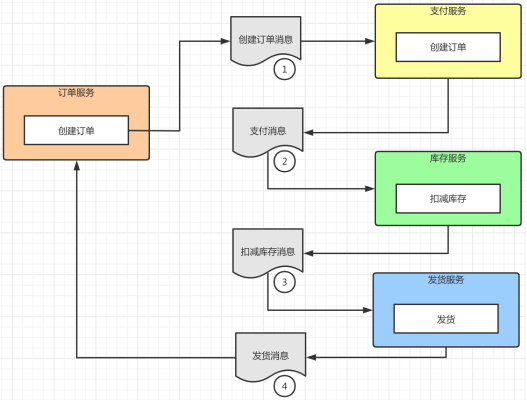
图3
编排模式-事务执行成功
1. “订单服务”中执行“创建订单”操作,此时会发送一个“创建订单消息”到队列中。
2. “支付服务”监听到队列中的这个订单消息,调用“支付订单”的操作,同时也发送“只服务消息”到队列中。
3. “库存服务”在监听到“支付消息”之后会进行“扣减库存”的处理,并且发送“扣减库存消息”等待下一个消费者接受。
4. “发货服务”作为整个事务的最后一个子事务,在接到“扣减库存消息”以后会执行发货的子事务,完成事务以后会给“订单服务”发送“发货消息”,订单服务在接受到消息以后完成整个事务闭环,并且提交。
上面说的是事务执行成功的情况,如果事务执行失败那应该如何处理?
如图4所示:
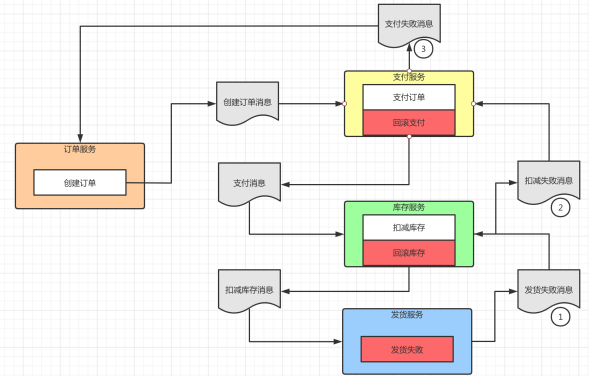
图4
编排模式-事务执行失败
1. 假设在执行“发货”时子事务失败了,会发送“发货失败消息”。
2. 库存服务在接受到“发货失败消息”之后会执行“回滚库存”的操作,该操作将原来扣减的库存加回去,同时发送“扣减失败消息”。
3. “支付服务”在接受到“扣减失败消息”之后会执行“回滚支付”,进行退款的操作,同时发送“支付失败消息”。订单服务在接受到该消息以后将下单事务标记为失败。
从上面的描述可以看出
编排的好处
:
简单:每个子事务进行操作时只用发布事件消息,其他子事务监听处理。
松耦合:参与者(服务)之间通过订阅事件进行沟通,组合会更加灵活。
当然也有一些
缺点
:
理解困难:没有对业务流程进行完整的描述,要了解整个事务的执行过程需要通过阅读代码完成。增加开发人员理解和维护代码的难度。
存在服务的循环依赖:
由于通过消息和事件进行沟通,参与者之间会存在循环依赖的情况。也就是
A
服务调用
B
服务,
B
服务又调用
A
服务的情况。这也增加了架构设计的复杂度,在设计初期需要认真考虑
。
紧耦合风险:每个参与者执行的方法都依赖于上一步参与者发出的消息,但是上一步的参与者的所有消息都需要被订阅,才能了解参与者的真实状态,无形中增加了两个服务的耦合度。
控制(
Orchestration
)
,其核心是定义一个控制类,它会告诉参与者(服务)应该执行哪些操作(子事务)。










