引言
Seq2Seq 于 2013年、2014 年被多位学者共同提出,在机器翻译任务中取得了非常显著的效果,随后提出的 attention 模型更是将 Seq2Seq 推上了神坛,Seq2Seq+attention 的组合横扫了非常多的任务,只需要给定足够数量的 input-output pairs,通过设计两端的 sequence 模型和 attention 模型,就可以训练出一个不错的模型。除了应用在机器翻译任务中,其他很多的文本生成任务都可以基于 Seq2Seq 模型来做,比如:文本摘要生成、对话生成等,由于 Seq2Seq 模型中 sequence 的灵活性,很多有意思的应用也随之诞生。本文将会带着大家一起来看看 Seq2Seq 好玩的应用。
热门应用
机器翻译
神经机器翻译(Neural Machine Translation)是 NLP 中最经典的任务,也是最活跃的研究领域之一,Seq2Seq 提出之后,最早应用于 nmt 任务。当前,主流的在线翻译系统都是基于深度学习模型来构建的,包括 Google、百度等,整体效果取得了非常显著的进步(当然,在刚刚推出的时候还是有很多槽点的)。每年都有特别多的 paper 在 Seq2Seq 模型上提出一些改进方案。
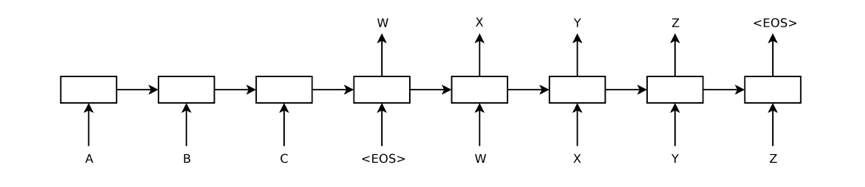
▲ 图1:典型的 Seq2Seq 模型图
上图是典型的 Seq2Seq 模型图,输入序列是 ABC,这里的 ABC 可以是字符、单词和短语,表示句子结尾符;目标序列是 WXYZ,模型分为两部分,一部分是 encoder,将输入序列进行编码表示,另一部分是 decoder,以 encoder 的表示作为 condition,将目标序列解码出来。由于文本通常是一个变长的序列,所以通常用 RNN、LSTM、GRU 以及他们的变种模型对文本进行建模。
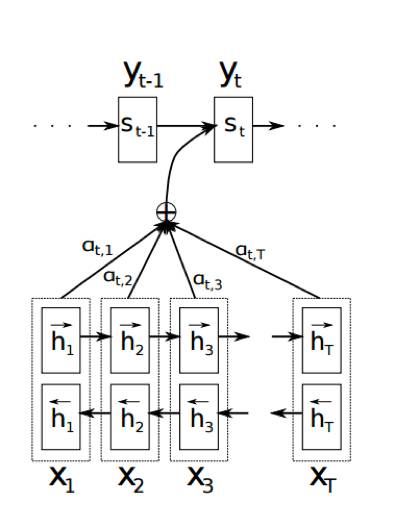
▲ 图2:attention 模型图
attention 模型在 Seq2Seq 提出一年之后被提出,这里的 attention 和人的一些行为特征有一定相似之处,人在看一段话的时候,通常只会重点注意具有信息量的词,而非全部词,即人会赋予每个词的注意力权重不同。attention 模型虽然增加了模型的训练难度,但提升了文本生成的效果。attention 模型非常的灵活,变种很多,回头有空一起来总结下 attention 和它的各种变种模型,这里就不再赘述了。
文本摘要
文本摘要也是一个非常经典的 NLP 任务,应用场景非常广泛。我们通常将文本摘要方法分为两类,extractive 抽取式摘要和 abstractive 生成式摘要。前者是从一篇文档或者多篇文档中通过排序找出最有信息量的句子,组合成摘要;后者类似人类编辑一样,通过理解全文的内容,然后用简练的话将全文概括出来。在应用中,extractive 摘要方法更加实用一些,也被广泛使用,但在连贯性、一致性上存在一定的问题,需要进行一些后处理;abstractive 摘要方法可以很好地解决这些问题,但研究起来非常困难。
也是基于 Seq2Seq+attention 模型在 nmt 任务中的成功,2016 年有很多的工作都是套用 Seq2Seq+attention 来做 abstractive 摘要任务,取得了一定的突破,但做的任务比较简单,输入是一句比较长的话(比如新闻的开头部分),目标是生成一个标题(比如新闻的标题)。直接套用 Seq2Seq 模型可以得到不错的效果,但 OOV(未登录词)问题是一个棘手的问题,在这个领域提出了 Pointer、CopyNet 等优秀的工作,这类模型的思路也是模仿人类的行为,即人在阅读一些内容时,很多的词(比如一些实体词,地名、人名等)并不能理解,只能进行“死记硬背”,也就是模型中的 pointer 或 copy,在生成每一个 token 时,判断一下是否需要从输入序列中进行 copy,不需要的话直接生成。当然很多工作在解决这个问题时,采用了一种“降维”的思路,即将最小单元从 word 降为 char,尤其对于英语摘要问题,char 的规模比如 word 来说非常小,而中文的效果不会那么明显,因为毕竟汉字的数量也非常多。
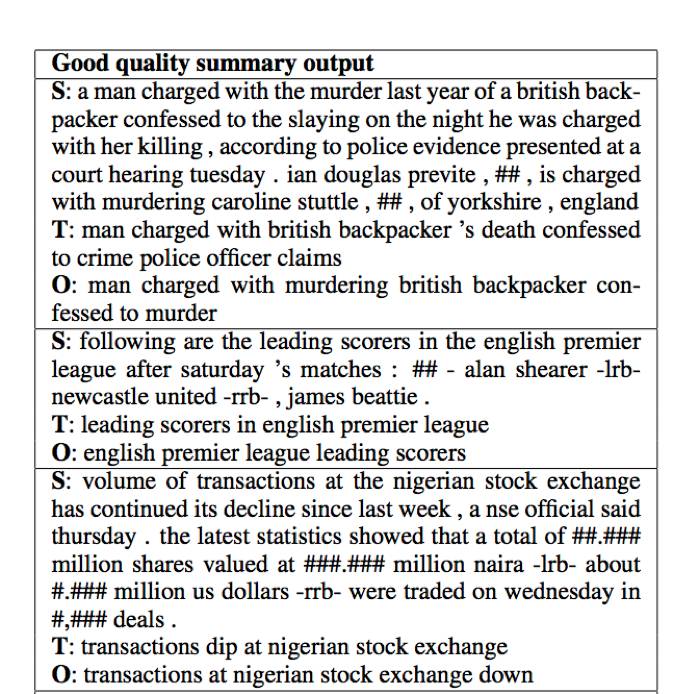
▲ 图3:模型生成的摘要结果
上图给出了「Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond 」一文中模型生成的摘要结果,S 为输入序列,即待摘要的内容,T 为目标序列,即给定的摘要内容,O 为输出序列,即算法生成的摘要内容。
利用 Seq2Seq 模型来解决文本摘要问题现在仍然停留在输入序列比较简短的情况,即 sentence-level abstractive summarization 问题,对于 document-level 和 multi document-level 的问题相关工作还很少,而解决这类更加真实的摘要问题,往往还是需要依赖 extractive 的方法,借助深度学习的优势做一些 ranking model。
关于文本摘要这块,去年我写了个系列博客(点击“阅读原文”进行访问),大家感兴趣的可以读一读,内容都是 2016 年的相关工作。文本摘要在去年火了一阵子然后沉寂了,最近 arXiv 上又不断地更新出一些不错的工作,大家可以关注 PaperWeekly官方微博(@PaperWeekly)和公众号的【每周值得读】栏目,我们会第一时间为大家推荐本周最新的高质量工作。
对话生成
Chatbot 是当前最火的创业领域,是投资的焦点,客观地讲,但真正特别好用的 Chatbot 几乎没有。C 端的 Chatbot 产品比较少,微软小冰算是其中最杰出的代表,小冰的定位并非帮助用户解决什么具体的实际问题,而是情感陪伴,做一个更像人的 bot,从这个角度来看,小冰是非常成功的。做一个有情感的 bot 其实比做一个所谓“有用”(比如:查天气、订机票等)的 bot 更难,上周 PaperWeekly 报道了一篇清华大学计算机系朱小燕、黄民烈老师团队的工作:PaperWeekly 第35期 | 如何让聊天机器人懂情感,他们的工作做了一件有趣的事情,给定 context 和情感选项(比如:开心、忧伤等)来生成具有指定情绪的 response,结果可参考下图。
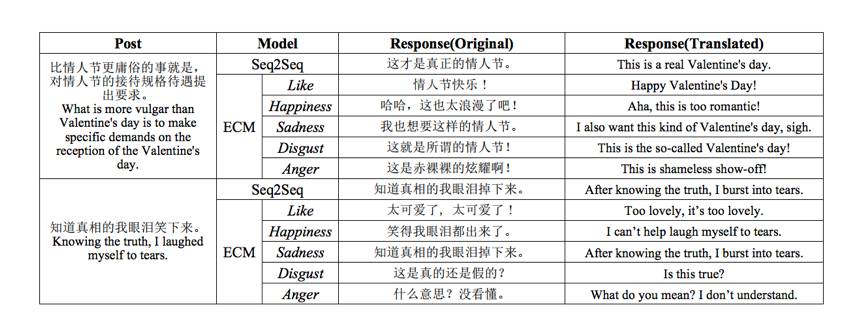
▲ 图4:根据情感选项生成对应情绪的回复
目前大多数 Chatbot 公司都在做 B 端,主要以客服业务为主。B 端之所以更容易接受现在大家不成熟的技术,是因为从某个角度上说,Chatbot 提高了生产效率,节约了成本,但这并不意味着 B 端所对应的 C 端的用户可以接受。Chatbot 的答非所问常常可见,对于 context 的理解也很差,做到“千人千面”的个性化就更加困难了。
Seq2Seq 模型提出之后,就有很多的工作将其应用在 Chatbot 任务上,希望可以通过海量的数据来训练模型,做出一个智能体,可以回答任何开放性的问题;而另外一拨人,研究如何将 Seq2Seq 模型配合当前的知识库来做面向具体任务的 Chatbot,在一个非常垂直的领域(比如:购买电影票等)也取得了一定的进展。但整体看来,这种生成式的方法在实际应用中问题颇多,首先是训练数据的问题,大家都知道方法是怎样的,但没有数据,再好的模型也没有意义。另外,Seq2Seq 做文本生成本身仍有很大的空间可以做,有很多的问题还没解决好,所以在工程应用中效果一般,业界的通用做法仍是几年前的做法,基于模板、基于规则和基于检索的方法来做,只是说利用了一些深度学习模型改进了传统的模板、规则和检索方法而已。
Chatbot 是个泡沫极大的领域,创业公司宣传的 Chatbot、投资人理解的 Chatbot、媒体鼓吹的 Chatbot 和用户期望的 Chatbot 其实都是不同的。Chatbot 是个综合性的工程问题,需要很多技术成熟了才能真正的解决好。回头有空了,可以好好对比一下现有的产品,检验下大家的产品是不是和宣传的一致。
趣味应用
诗词生成
让机器为你写诗并不是一个遥远的梦,Seq2Seq 模型一个非常有趣的应用正是诗词生成,即给定诗词的上一句来生成下一句。PaperWeekly 第23期 | 机器写诗,来自中科大的王哲同学为大家 survey 了这个领域的一些工作,他的 paper「Chinese Poetry Generation with Planning based Neural Network」也提出了一种诗词生成模型,为了保证后面几句诗词在生成的时候与诗词主题的相关性,在 Seq2Seq 基础上提出了一个 planning 模型,用来生成写作大纲。

▲ 图5:左边是机器生成的诗词,右边是一首宋代诗词
生成 commit message
今年 ACL 录用一篇非常有趣的 paper「A Neural Architecture for Generating Natural Language Descriptions from Source Code Changes」,输入 code 的修改信息,输出用自然语言生成的 code commit message,大家在用代码版本控制器 commit code 时,通常需要写个 commit message 来标记改动的记录。本文的工作利用 Seq2Seq 模型,帮助大家在 commit 代码的时候直接用算法生成 commit message。作者将代码开源在了 GitHub 上(https://github.com/epochx/commitgen)
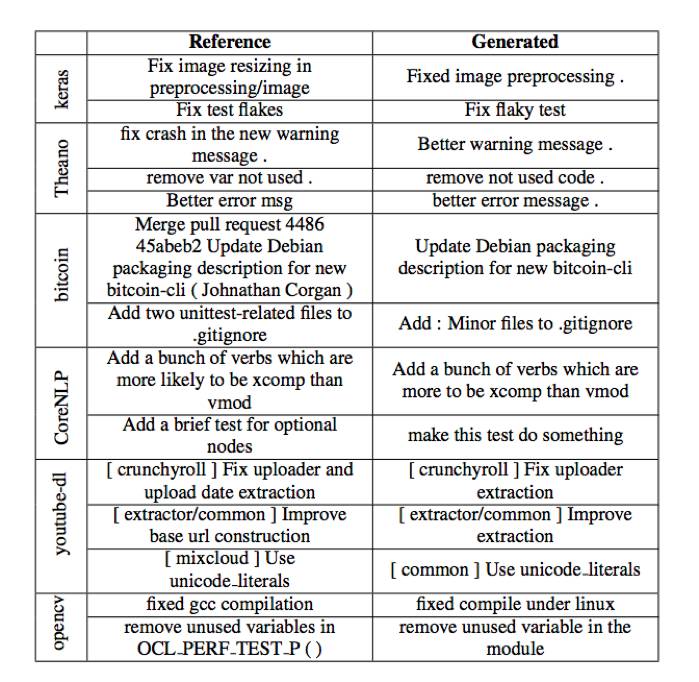
▲ 图6:左边是参考信息,右边是算法生成信息
生成代码补全
写代码需要有两个利器,一个是机械键盘,一个就是 IDE,好的 IDE 可以帮助我们省去很多的工作。2016 年底发表在 arXiv 上的一篇 paper「Learning Python Code Suggestion with a Sparse Pointer Network」,研究的问题非常有意思,就是大家常见的 IDE 代码补全功能。现有的 IDE 对静态编程语言支持的比较好,对于动态编程语言支持的一般,而且一般都是补全某个函数或者方法之类的,而不能给出更复杂的代码。本文针对这个问题,构造了一个大型的 Python code 数据集,并且用了比较流行的 Pointer Network 模型来做端到端的训练,取得了不错的效果。
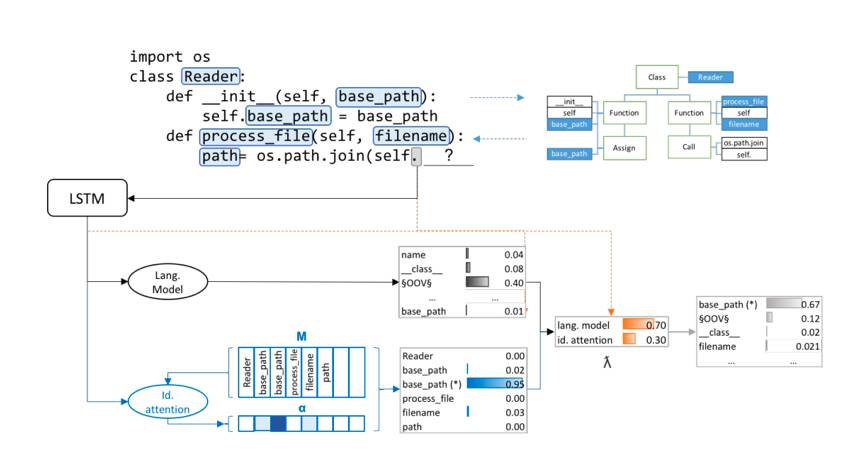
▲ 图7 Seq2Seq 生成代码提示的模型图
代码补全在实际应用中非常有用,但想做到很复杂、很智能的补全还有很长的路。不过这个 topic 还是一个非常有意思的东西。
从web页面图片中生成对应html代码和从公式图片中生成latex代码
Harvard NLP 组一个非常有意思的工作「What You Get Is What You See: A Visual Markup Decompiler」,研究的问题是如何从 web 页面图片中生成对应 html 代码,以及如何从公式图片中生成 latex 代码,为此作者构造了两个相关的大型数据集,采用了 Seq2Seq 模型来解决这个问题。第一个问题如图8:

▲ 图8:从 web 页面图片中生成 html 代码
第二个问题如图9:

▲ 图9:从公式图片中生成 latex 代码
第二个问题有一定的实际意义,公式和文本不同,通过 OCR 识别之后,并不太方便显示在文本编辑工具中,本文的工作将其进一步映射为 latex 代码,可以非常好地解决 pdf 文本化的问题。
本项目主页地址:http://lstm.seas.harvard.edu/latex/,包括开源的数据、代码和 demo 演示。
故事风格改写
利用 Seq2Seq 模型还可以做一些类似故事风格改写的应用,比如 2016 年的这篇工作「A Theme-Rewriting Approach for Generating Algebra Word Problems」,给定一个简单的数学应用题,然后给定一种故事风格(比如:星际争霸),生成该种风格下的应用题描述,如图10所示:

▲ 图10:一道应用题被改写为三种故事背景下的应用题描述
对于很多孩子来说,在作业中看到熟悉的动画片或者漫画人物会增加他们学习的兴趣,这个应用可以非常好地将已有的文本改写为另外一种故事风格。本项目的数据集和代码都已开源,地址如下:
https://gitlab.cs.washington.edu/kedzior/Rewriter/
总结
本文列举了几种 Seq2Seq应用场景,包括了经典的机器翻译、文本摘要和对话生成等,也包括了一些非常有趣的应用,比如:根据公式图片生成 latex 代码,生成 commit message 等。自然语言生成(NLG)是一个非常有意思,也非常有前途的研究领域,简单地说,就是解决一个条件概率 p(output| context)的建模问题,即根据 context 来生成 output,这里的 context 可以非常零活多样,大家都是利用深度学习模型对这个条件概率进行建模,同时加上大量的训练数据和丰富的想象力,可以实现很多有趣的工作。Seq2Seq 是一个简单易用的框架,开源的实现也非常多,但并不意味着直接生搬硬套就可以了,需要具体问题具体分析。另外,RNN 系的模型非常难训练,尤其是多层 RNN 模型,如何优化 RNN 训练过程也是一个非常值得研究的方向,比如最近的一篇工作「Learning to Skim Text」就是通过一种策略来做 RNN 优化。此外,对于生成内容的控制,即 decoding 部分的研究也是一个非常有意思的方向,比如:如何控制生成文本的长度,控制生成文本的多样性,控制生成文本的信息量大小,控制生成文本的情感等等。
本文对 Seq2Seq 的一些应用进行了简单的介绍,希望可以抛砖引玉,看到更多好玩的工作被推荐出来。
关于PaperWeekly
PaperWeekly是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事AI领域,欢迎在公众号后台点击「交流群」,小助手将把你带入PaperWeekly的交流群里。









