问题导读
1.在url中,如何过滤不需要的内容?
2.如何获取404记录并且获取字段?
3.获取不能访问url列表的思路是什么?
about云日志分析实战之清洗日志4:统计网站相关信息
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22900
上篇文章简单的统计了一些信息,下一步希望找到404对应的url。
思路:
1.获取request字段
2.过滤不需要字符
3.实现获取url,并打印输出
1.创建getRequest函数获取request字段
[Scala]
纯文本查看
复制代码
?
|
1
2
3
4
5
6
7
8
|
def
getRequest(rawAccessLogString
:
String)
:
Option[String]
=
{
val
accessLogRecordOption
=
p.parseRecord(rawAccessLogString)
accessLogRecordOption
match
{
case
Some(rec)
=
> Some(rec.request)
case
None
=
> None
}
}
|
2.创建extractUriFromRequest函数
[Scala]
纯文本查看
复制代码
?
|
1
2
|
def
extractUriFromRequest(requestField
:
String)
=
requestField.split(
" "
)(
1
)
|
这个目的大家可以猜猜它的作用
获取404页面,并且打印出请求的URL.
[Scala]
纯文本查看
复制代码
?
|
1
2
3
4
5
|
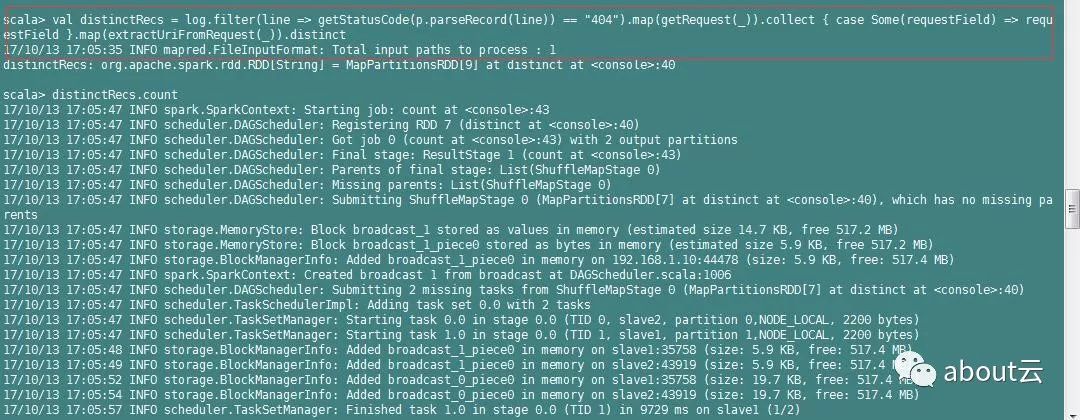
val
distinctRecs
=
log.filter(line
=
> getStatusCode(p.parseRecord(line))
==
"404"
)
.map(getRequest(
_
))
.collect {
case
Some(requestField)
=
> requestField }
.map(extractUriFromRequest(
_
))
.distinct
|
[Scala]
纯文本查看
复制代码
?




