
如果你订阅了 Linux Kernel 的 maillist,你一定发现最近 Linus 又爆粗口了,而这次的对象是 ext4 文件系统。
On Sun, Aug 6, 2017 at 12:27 PM, Theodore Ts'o
wrote:
>
> A large number of ext4 bug fixes and cleanups for v4.13
A couple of these appear to be neither cleanups nor fixes. And a lot
of them appear to be very recent.
I've pulled this, but if I hear about problems, ext4 is going to be on
my shit-list, and you'd better be a *lot* more careful about pull
requests. Because this is not ok.
Linus
而这已经不是 Linus 第一次对 ext4 文件系统表达不满了。
尽管 ext4 文件系统已经发布了多年,也被广泛应用于桌面及服务器,但关于 ext4 存在可能丢数据的 Bug 报告就一直没有中断过。例如在 2012 年的一封
邮件
中,Theodore Ts'o 报告了一次严重的 Bug,已经影响了部分 Linux 稳定版本的内核。
如果你持续关注文件系统或内核技术,你一定注意过这样一篇文章:
Fuzzing filesystem with AFL
。Vegard Nossum 和 Quentin Casasnovas 在 2016 年将用户态的 Fuzzing 工具 AFL(American Fuzzing Lop)迁移到内核态,并针对文件系统进行了测试。
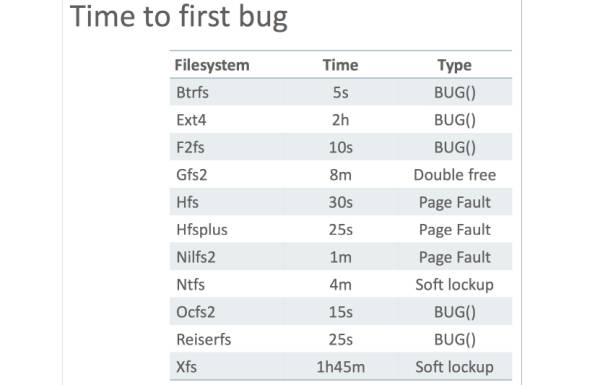
结果是相当惊人的。Btrfs,作为 SLES(SUSE Linux Enterprise Server)的默认文件系统,仅在测试中坚持了 5 秒钟就挂了。而 ext4 坚持时间最长,但也仅有 2 个小时而已。
这个结果给我们敲响了警钟,Linux 文件系统并没有我们想象中的那么稳定。而事实上,在 Fuzz 测试下坚持时间长短仅仅体现出文件系统稳定性的一部分。数据可靠性,才是文件系统中最核心的属性。然而 Linux 文件系统社区的开发者往往都把注意力放在了性能,以及高级功能的开发上,而忽略了可靠性。
今天,我们就带大家回顾一下 Linux 文件系统的黑历史,希望能够警醒大家,不要过分相信和依赖文件系统。同时,在使用文件系统构建应用时,也需要采用正确的“姿势”。
谈到 Linux 文件系统,不得不提到 POSIX(Portable Operating System Interface),这样一个奇葩的标准。而开发者对于 POSIX 的抱怨,可谓是罄竹难书。
作为一个先有实现,后有标准的 POSIX,在文件系统接口上的定义,可谓是相当的“简洁”。尤其当系统发生 crash 后,对于文件系统应有的行为,更是完全空白,这留给了文件系统开发者足够大的“想象空间”。也就是说,如果一个 Linux 文件系统在系统发生崩溃重启后,整个文件系统的内容都不见了,也是“符合标准”的。
而事实上,类似的事情确实发生过:在 2015 年,ChromeOS 的开发者曾报告了一个 ext4 的问题,有可能导致 Chrome 发生崩溃。而来自 ext4 开发者的回答是,
“Working As Intended”
。
在历史上,不断有人尝试给文件系统提供更加严谨的 Consistency(一致性)定义,尤其是 Crash-Consistency(故障后的一致性)。到目前为止,尽管 POSIX 也经历了几个版本,但关于文件系统接口的定义,还是那个老样子。而 POSIX 标准,也是造成了文件系统各种问题的一个很重要的因素。关于各种一致性的定义,我们后面也会有文章专门进行介绍。
文件系统一直有着光辉的发展历史,也孕育了许多伟大的 Linux 内核贡献者。从最早的 FFS,到经典的 ext2/ext3/ext4,再到拥有黑科技的 Btrfs,XFS,BCacheFS 等。
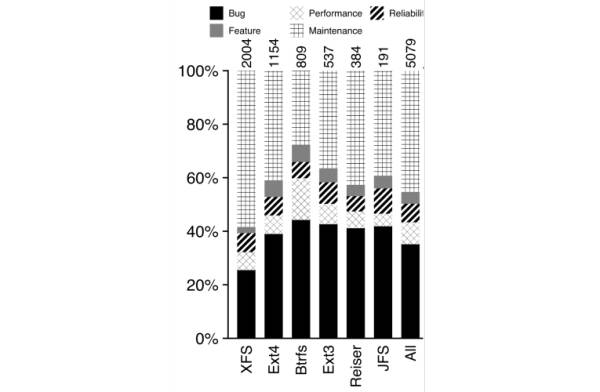
然而软件开发的过程,当然不是一帆风顺的。威斯康辛大学麦迪逊分校的研究者曾在 FAST '13 上发表过一篇著名的论文
《A Study of Linux File System Evolution》
。文章对 8 年中,Linux 社区与文件系统相关的 5079 个 Patch 进行了统计和分析。从其数据中可以看出,有将近 40% 的文件系统相关的 Patch 属于 Bugfix 类型。换句话说,每提交两个 Patch,就有可能需要一个 Patch 用于 Bugfix。
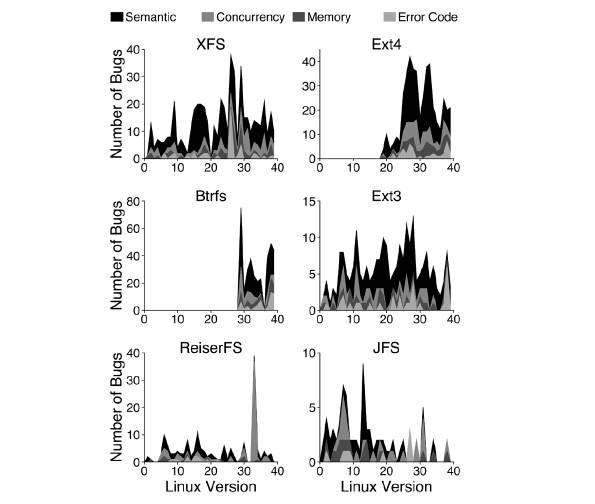
而文件系统的 Bug 数量并没有随着时间的推移而逐渐收敛,随着新功能不断的加入,Bug 还在持续不断的产生。而 Bug 的集中爆发也往往源于大的功能演进。
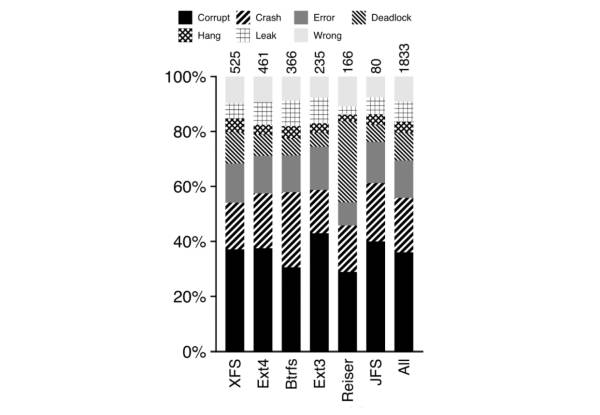
而从上图中可以看出,在所有的 Bug 中,有接近 40% 的 Bug 可能导致数据损坏,这还是相当惊人的。
可以想象,在 Linux 文件系统的代码库中,还隐藏着许多 Bug,在等待着被人们发现。
哥伦比亚大学文件系统领域著名的专家 Junfeng Yang,曾经在 OSDI '04 上发表了一篇
论文
,该论文也是当年 OSDI 的最佳论文。在这篇论文中,Junfeng Yang 通过 FiSC,一种针对文件系统的 Model Checking 工具,对 ext3,JFS,ReiserFS 都进行了检查,结果共发现了 32 个 Bug。而不同于 AFL,FiSC 发现的 Bug 大部分都会导致数据丢失,而不仅仅是程序崩溃。例如文章中指出了一处 ext3 文件系统的 Bug,该 Bug 的触发原因是在通过 fsck 进行数据恢复时,使用了错误的写入顺序,在 journal replay 的过程中,journal 中的数据还没有持久化到磁盘上之前,就清理了 journal,如果此时发生断电故障,则导致数据永久性丢失。





