
作者:真依然很拉风
通过对局部地区某一岗位的总体分析,找出该地区该职位的职业发展前景规律。本文基于拉勾上2016年12月到2017年1月深圳地区数据分析师招聘数据,为这一行业的朋友作为参考;虽然数据略为过时,但变化也不大,规律依然适用。
1、数据分析师主要还是
开发类职业
。开发类的职位,无论是市场需求还是薪资都是无可撼动的最高。
2、
地区方面
:如果你要在深圳找数据分析师的岗位,请去南山区,优先去科技园附近。
3、
薪资方面
,20K是业内中等水平;
4、
学历方面
,除非你直接攻读相关专业的博士,否则本科足矣;
5、
技能方面
:Hadoop和Spark这类大数据基础框架是市场最为重视的,因此Java是最为需要的语言。Python是首选的语言。
6、
公司选择方面
:数据表明大公司的需求和薪资都显著性强于小公司。
拉勾因其结构化的数据比较多因此过去常常被爬,所以在其多次改版之下变得难爬。不过只要清楚它的原理,依然比较好爬。其机制主要就是AJAX异步加载JSON数据,所以至少在搜索页面里翻页url不会变化,而且数据也不会出现在源代码里。
这是深圳地区的数据分析师页面,用Chrome检查打开。在XHR中可以看到一个以postionAjax.json开头的脚本,打开Preview看一下,可以看到:
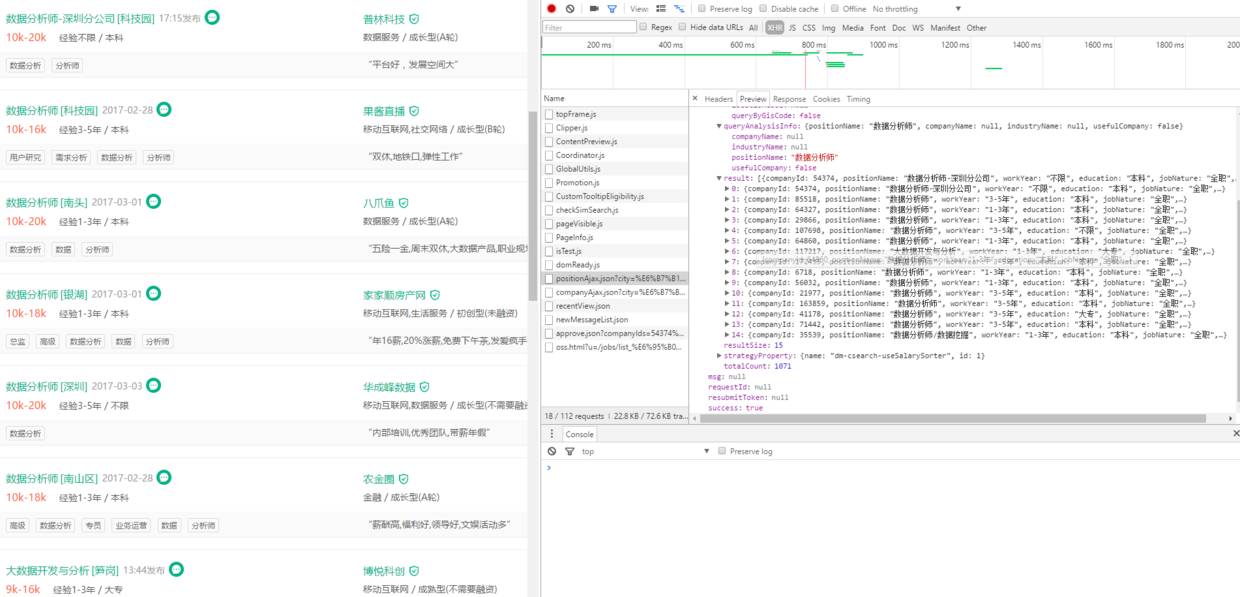
可以发现这些数据与前端的数据一致,此时我们已经找到了数据入口,就可以开始爬了。
在Headers里可以查看请求方式:
Request Header:
Request URL:https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false
Request Method:POST
Status Code:200 OK
Remote Address:106.75.72.62:443
从Request Header中可以看到,是用POST提交表单方式查询的(所以如果你直接点开Request URL你会发现数据不对,因为没有提交表单数据)。
那么我们就可以在Python中构造请求头以及提交表单数据来访问:
import requestsimport timefrom sqlalchemy import create_engineimport pandas as pdfrom random import choiceimport jsonimport numpy
engine=create_engine(dl = pd.read_sql("proxys",engine)def get_proxy(dl):
n = choice(range(1, len(dl.index)))
proxy = {"http":"http://%s:%s" %(dl["ip"][n],dl["port"][n]), "https": "http://%s:%s" % (dl["ip"][n], dl["port"][n])} return(proxy)def get_header():
headers = { "User-Agent": ""Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"", "Accept": "application/json, text/javascript, */*; q=0.01", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "Referer": "https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88?px=default&city=%E6%B7%B1%E5%9C%B3&district=%E5%8D%97%E5%B1%B1%E5%8C%BA", "X-Requested-With": "XMLHttpRequest", "Host": "www.lagou.com", "Connection":"keep-alive", "Cookie":"user_trace_token=20160214102121-0be42521e365477ba08bd330fd2c9c72; LGUID=20160214102122-a3b749ae-d2c1-11e5-8a48-525400f775ce; tencentSig=9579373568; pgv_pvi=3712577536; index_location_city=%E5%85%A8%E5%9B%BD; SEARCH_ID=c684c55390a84fe5bd7b62bf1754b900; JSESSIONID=8C779B1311176D4D6B74AF3CE40CE5F2; TG-TRACK-CODE=index_hotjob; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1485318435,1485338972,1485393674,1485423558; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1485423598; _ga=GA1.2.1996921784.1455416480; LGRID=20170126174002-691cb0a5-e3ab-11e6-bdc0-525400f775ce", "Origin": "https://www.lagou.com", "Upgrade-Insecure-Requests":"1", "X-Anit-Forge-Code": "0", "X-Anit-Forge-Token": "None", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.8"
} return(headers)def get_form(i):
data={"first":"false","pn":i,"kd":"数据分析师"} return(data)
districts = ["南山区","福田区","宝安区","龙岗区","龙华新区","罗湖区","盐田区","大鹏新区"]
pagenos = [22,10,1,4,1,2,1,1]
url_lists = ["https://www.lagou.com/jobs/positionAjax.json?px=default&city=深圳&district=%s&needAddtionalResult=false"%area for area in districts]
s = requests.Session()
s.keep_alive = Falses.adapters.DEFAULT_RETRIES = 10def get_jobinfo(i,j):
if i >= 8 or j > pagenos[i]: return("索引超标!")
resp=s.post(url_lists[i], data=get_form(j), headers=get_header())
resp.encoding="utf-8"
max_num = len(json.loads(resp.text)["content"]["positionResult"]["result"]) for k in
range(max_num): try:
json_data=json.loads(resp.text)["content"]["positionResult"]["result"][k]
df = pd.DataFrame(dict(
approve=json_data["approve"],
companyId=json_data["companyId"],
companyShortName=json_data["companyShortName"],
companySize=json_data["companySize"],
createTime=json_data["createTime"],
education=json_data["education"],
financeStage=json_data["financeStage"],
firstType=json_data["firstType"],
industryField=json_data["industryField"],
jobNature=json_data["jobNature"],
positionAdvantage=json_data["positionAdvantage"],
positionId=json_data["positionId"],
positionName=json_data["positionName"],
salary=json_data["salary"],
secondType=json_data["secondType"],
workYear=json_data["workYear"],
scrapy_time=time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))),index=[0])
df.to_sql(con = engine, name = "job_info", if_exists = 'append', flavor = "mysql",index=False) except:
print("第%d区,第%d页,第%d个出错了!"%(i,j,k))
以上这个函数就可以通过提交区和页数,返回当前页的职位数。
其实AJAX返回JSON数据的方式也有好处,数据都是规整的,不必花太多时间精力在数据清洗上。
至于职位详情的内容是写在源代码里的,这些用常规爬虫方法即可。
不过注意要加延时,拉勾的反爬虫措施还是比较严的,不加延时爬一小会儿就会被封IP。
区域分析
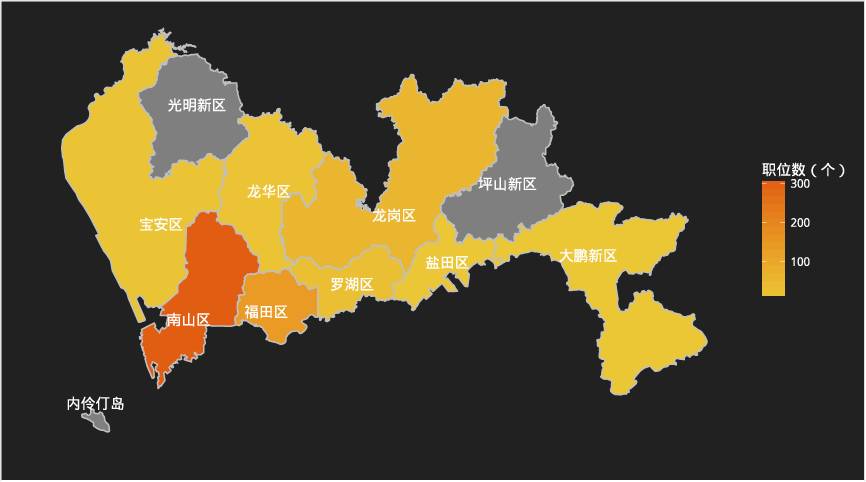
各区职位数
从拉勾爬取的数据拉勾,在深圳,对数据分析师需求量最大的地区为南山区,其次为福田区。这个当地的互联网企业分布有很大的关系,众所周知,深圳的互联网企业集中在南山区和福田区;
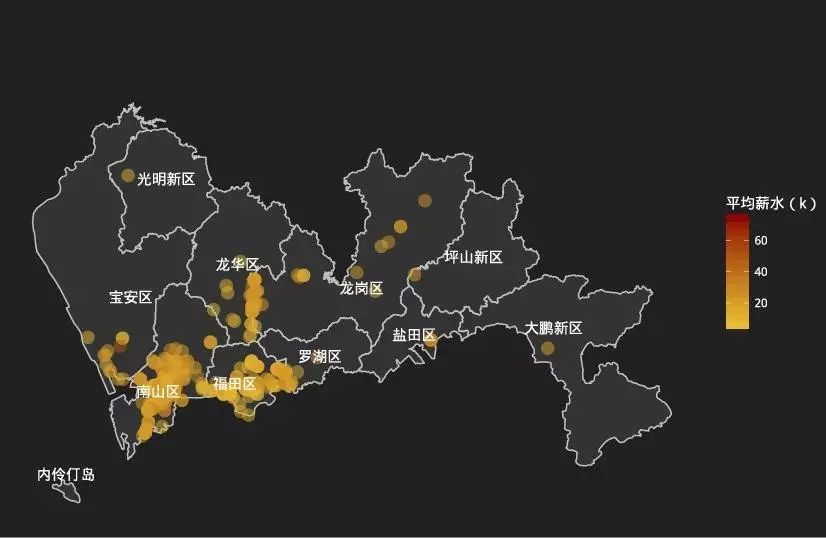
空间分布
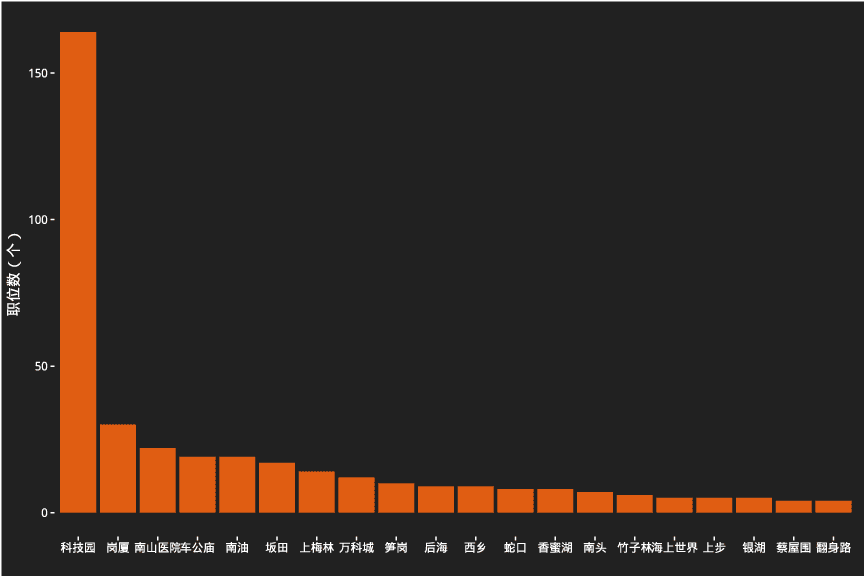
各区域板块职位数
频数分布
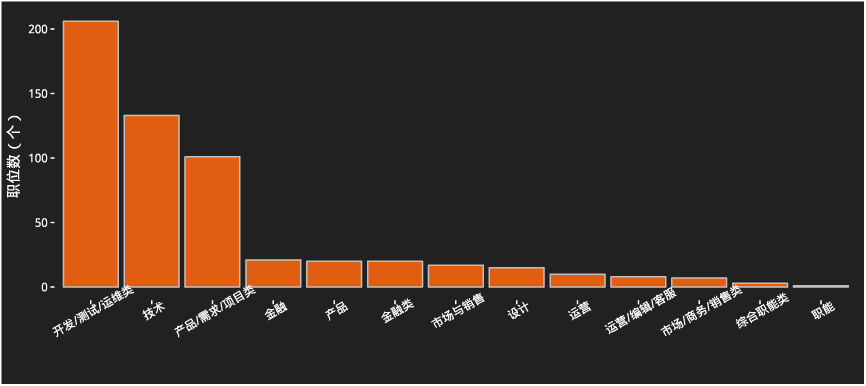
第一类别频数

第二类别频数
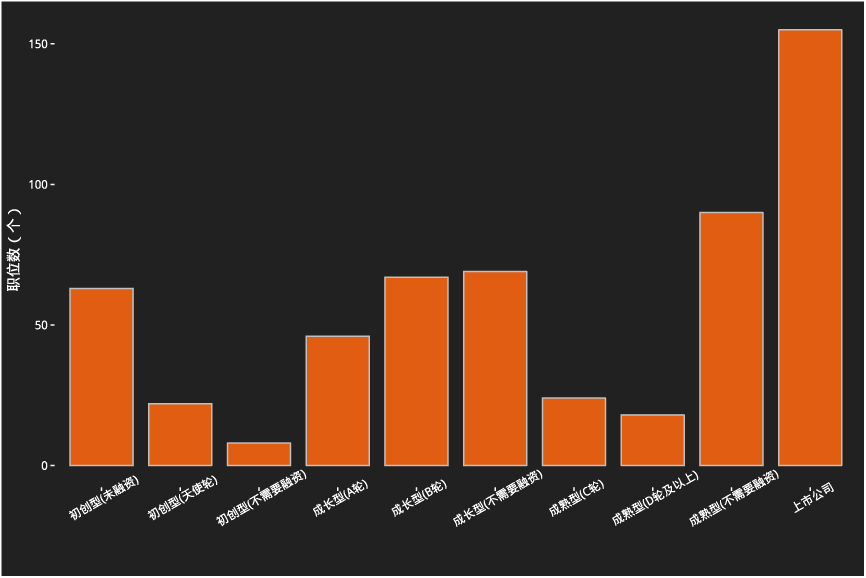
不同公司阶段招聘数量
薪资分布

全部职位平均薪资总体分布
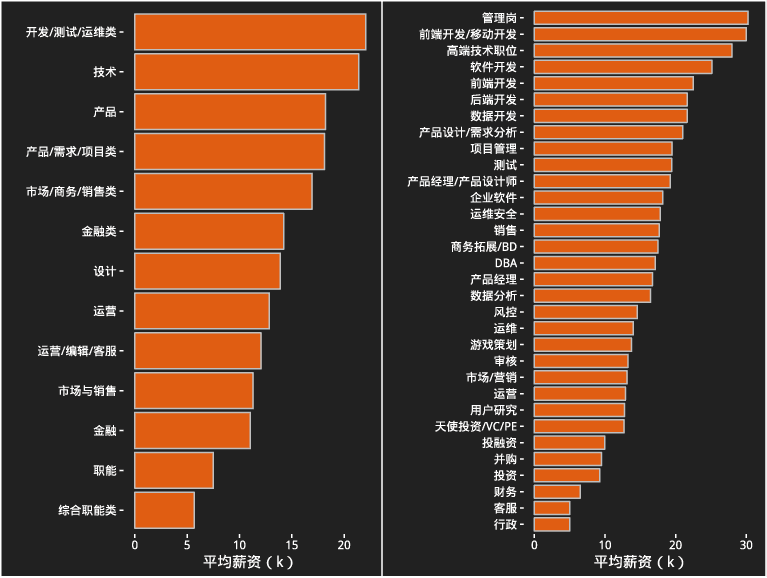
不同类别职位薪资分布
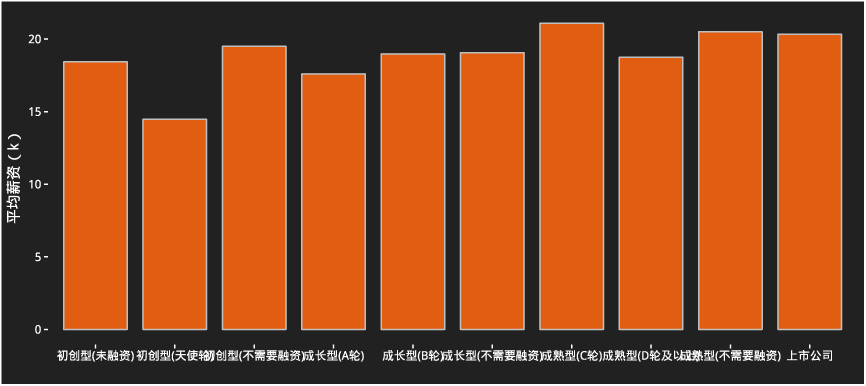
不同阶段公司平均薪资
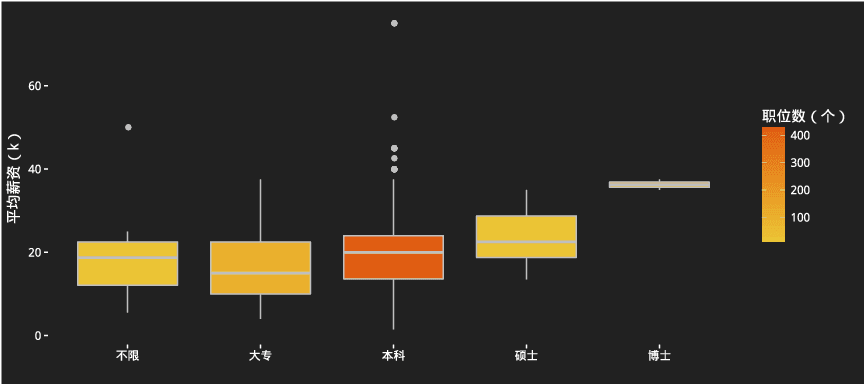
不同学历对薪资的影响
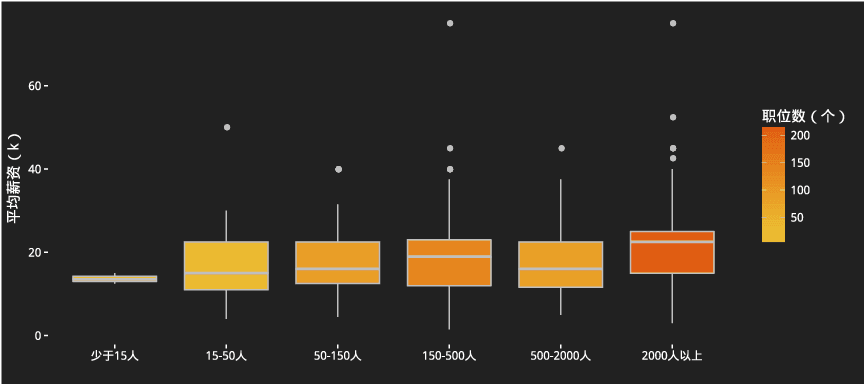
公司规模对薪资的影响
技术要求

数据分析师的技术要求
公司排名

高薪岗位top20
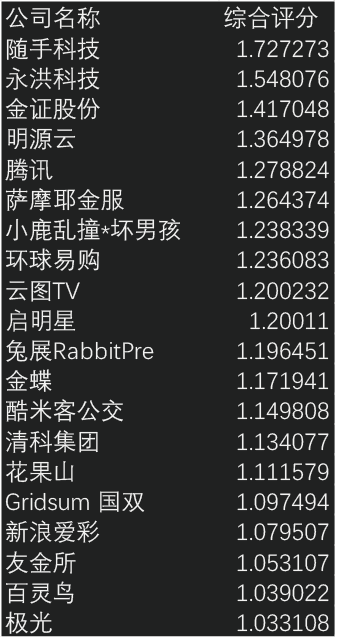
综合人气排名
结论
在现今的市场认知中,
数据分析师主要还是开发类职业。开发类的职位,无论是市场需求还是薪资都是无可撼动的最高
。因此所以如果你不会编程,或者不想作一个程序员(比如我),那么应该重新思考一下职业规划。
如果
你要在深圳找数据分析师的岗位,请去南山区,优先去科技园附近
。
如果你去找工作,HR问你期望薪资,你就说20K,因为这是业内的中等水平(这是考虑了最高薪资,不过考虑到大部分的最高薪资只是一个幌子,因此20K当然是虚高:))。30K基本就到了数据分析师的天花板,而这个天花板一般要5年以上的时间达到。
当然要找一个20K的工作也不是那么轻松。你首先要自己具备实力。对于学历,除非你直接攻读相关专业的博士,否则本科足矣,读个硕士作用并不大(尤其是国内的硕士),三年时间转化成工作经验价值更大。
至于技术方面,Hadoop和Spark这类大数据基础框架是市场最为重视的,因此Java是最为需要的语言
(这主要还是因为大部分的公司不知道数据工程师和数据分析师的区别,或者大部分的公司仍处于基础建设阶段,离数据挖掘、分析和应用还有不少距离)。
对于懂行的数据分析师来说,Python是首选的语言,毕竟全能;当然R也是越来越流行和被重视;SAS也不错,金融行业很需要。
无论是工程师还是分析师,
数据库和SQL始终是重要的基础技能。
当你足够牛的时候,就是你来挑选市场了。去大公司还是小公司?去大公司。数据表明大公司的需求和薪资都显著性强于小公司。在移动互联网收尾,人工智能兴起的大数据时代,没有数据、没有资金、没有技术的小公司实在难有作为。
当然拉勾的数据既不全面,也不一定都靠谱(事实上许多HR的招聘需求都是抄来抄去)。因此,以上所有结论一定有某种程度的偏差,仅供参考。
End
如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?









