 我 相 信 这 么 优秀 的 你
我 相 信 这 么 优秀 的 你
已 经
置 顶
了 我
翻译|王洪岩
选文|小象
转载请联系后台
◇
◆
◇
◆
◇
起源
尽管现在网络上大肆宣传,但人工智能并不是什么新东西。上世纪50年代其实就出现AI领域的一些基础。如果我们排除纯哲学推理过程,也就是从古希腊到霍布斯,莱布尼兹到帕斯卡,正如我们所知,
人工智能正式的起始于1956年的达特茅斯大学
,在那里所有最显赫的专家们都聚集在一起进行头脑风暴,以解决智能模拟的问题。
这件事发生于阿西莫夫设计他的机器人三大定律之后几年,更贴切的说是图灵在1950年发表他那篇最著名的论文之后,论文第一次提出会思考的机器的说法,而且更著名的是用以测试机器是否具备智能的
图灵测试法
。
在达特茅斯大学的夏季会议的内容和思想一发表,便赢得了大量的政府资助,用于对非生物智能的研究。

◇
◆
◇
◆
◇
恶灵威胁
在那时候,人工智能看似非常容易实现,但是结果表明并非如此。在60年代末,一些研究者发现实现人工智能是非常困难的,这使得相关的基金开始撤资。
这种现象在人工智能发展历程上,被称之为“人工智能影响”,该影响由两部分组成:
1. 持续的对于人工智能将在未来几十年内出现的承诺;
2. 当人工智能遇到某些问题时对于其研究大打折扣,不断的重新定义何为智能;
在美国,美国国防高级研究计划局的为人工智能研究出资主要是为了建立一个完美的翻译机器,但是两件连续的事故破坏了该提议,起因于之后被称之为的第一个“人工智能之冬”;
事实上,1966年的语言自动处理委员会报告以及紧接着1973年的莱特希尔报告,评估了在当前发展状况下的人工智能发展的合理性,并对于创建一个智能思考的机器的可能性做出了消极预测。
这两个报告联合地指出了有限的设计算法的数据和现阶段稀缺的计算引擎资源,从而使得该领域研究的坍塌,人工智能成为整个时间段都非常不光彩的事。
◇
◆
◇
◆
◇
复制品的攻击
在80年代,尽管有一些英国和日本的资金在支持着“专家系统”,也就是一种狭义的人工智能,被定义为早期AI。
这些程序可以模拟在某些特定领域的人类的专家,但是并没有激起新的投资趋势。那些年最活跃的参与者是日本政府,并且其对于创建第五代计算机的迫切性迫使美国和英国来继续在人工智能的投资。
但是这个黄金时代没有持续很长时间,当投资的目标没有达成后,一个新的危机开始了。1987年,个人电脑成为比LISP机更有力的工具,也就是多年研究人工智能的产物。这些歹势“第二次人工智能之冬”的开始,美国国防部高级研究计划局明确表明立场反对人工智能的探究和投资。
◇
◆
◇
◆
◇
智能的回归
幸运的是,该阶段结束于MIT的Cog项目建造了一个仿人类的机器人和动态分析和规划工具——该工具偿还了美国政府自1950年以来的所有投资。1997年的时候深蓝打败世界棋王,显然此时人工智能重新回到世界舞台。
在过去的二十年中出现了很多学术突破,为人工智能领域做出了贡献。但为什么只有在近年才广泛进入了大众视角,被捧为了学术典范?有许多原因可以让我们理解为什么我们要这么深入的研究人工智能,但是我们认为有一个具体事件可以解释过去五年来的趋势。
如果我们看下图,就可以注意到尽管现在实现了较大的发展,但是人工智能直到2012年年末才真的被大众认识。该图由CBInsights创建,他们是根据一些特定的词汇或者主题来产生发展趋势图(本图中就是人工智能和机器学习)。
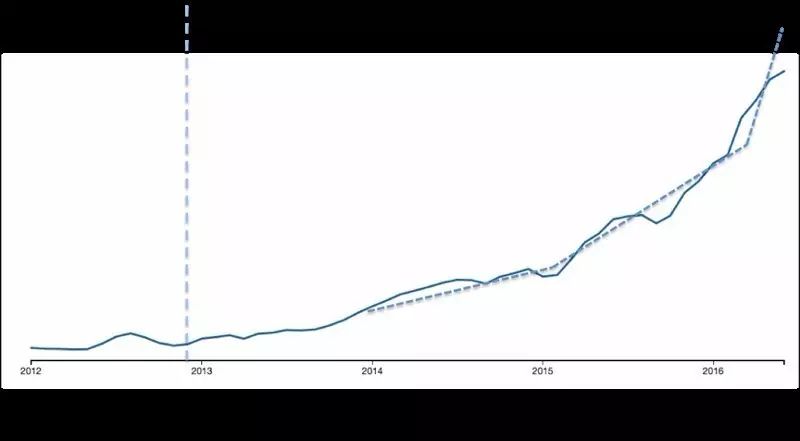
在这里,我进一步细节地画出了具体的引发新的人工智能研究浪潮的日期,2012年12月4日(Krizhevskyet al., 2012)。在那个周四,一些研究者在神经信息处理大会上展示了一些卷积神经网络的细节问题,该方法使得他们在ImageNet图像分类大赛中保持优异的成绩,该算法将图像分类正确率从72%提高到85%,并将神经网络确立为人工智能的基础。
在不到两年间,该领域的发展将ImageNet的比赛图像分类精度提高到96%,甚至比人类肉眼识别率(95%)还略高。
该图也同时表明了三个主要的人工智能增长趋势(点画线),描述了三个主要事件:
1. 2014年1月的谷歌创建的DeepMind已经三岁了;
2. 2015年2月 (Mnih etal., 2015) 大于8000人签署了由DeepMind发表的关于增强学习的研究而成立的未来生活研究所的公开信;
3. 2016年1月由DeepMind的科学家在Nature上发表的关于神经网络的文章(Silveret al., 2016) ,以及接下来2016年3月AlphaGo战胜李世石的消息。(其他的惊人成就可以查看Ed Newton-Rex的一篇文章)
◇
◆
◇
◆
◇
新的希冀
人工智能是一个高度依赖于基金的研究因为他是个长期研究过程,并且需要不计其数的精力和资源投入才能够完全实现。
现在已有一些我们可能在接下来的一个巅峰时期可能产生的担忧,当然现在的惊喜也会在那时候停止。
然而,正如其他人一样,我相信该新的领域是特别的,由于以下三个原因:
1. (大)数据,因为我们终于有足够的数据来训练算法;
2. 技术革新,由于存储能力、计算能力、算法理解,更好的带宽、更低的技术成本,这些允许模型得到他们需要的信息;
3. 由于Uber和Airbnb等商业模型所引入的资源民主化和更有效地分配,也就是表现于云服务(Silveret al., 2016) ,和GPU的同步计算。
◇
◆
◇
◆
◇
参考文献
· Dhar, V. (2016). “The Future of Artificial Intelligence”.Big Data, 4(1): 5–9.
· Krizhevsky, A., Sutskever, I., Hinton, G.E. (2012).“Imagenet classification with deep convolutional neural networks”. Advances inneural information processing systems: 1097–1105.
· Lighthill, J. (1973). “Artificial Intelligence: A GeneralSurvey”. In Artificial Intelligence: a paper symposium, Science ResearchCouncil.
· Mnih, V., et al. (2015). “Human-level control throughdeep reinforcement learning”. Nature, 518: 529–533.
· Silver, D., et al. (2016). “Mastering the game of Go withdeep neural networks and tree search”. Nature, 529: 484–489.
· Turing, A. M. (1950). “Computing Machinery andIntelligence”. Mind, 49: 433–460.





