
关注
鸿蒙技术社区
,回复
【鸿蒙】
送价值
399元
的鸿蒙
开发板套件
(数量有限,先到先得),还可以
免费下载
鸿蒙
入门资料
!
👇
扫码
立刻关注
👇

专注开源技术,共建鸿蒙生态
最近,我一直在研究 Pulsar 及其与 Kafka 的比较。通过快速搜索,你会看到这两个最著名的开源消息传递系统之间正在进行的"战争"。
图片来自 Pexels
作为 Kafka 的用户,我着实对 Kafka 的某些问题感到困惑,但 Pulsar 却让人眼前一亮、令我非常兴奋。所以最后,我设法花了一些时间了解背景资料,并且做了很多研究。
在本文中,我将重点介绍 Pulsar 的优势,并说明 Pulsar 胜于 Kafka 的理由。让我们开始!
Kafka 是消息传递系统之王。它由 LinkedIn 于 2011 年创建,并在 Confluent 的支持下得到了广泛的传播。
Confluent 已向开源社区发布了许多新功能和附加组件,例如用于模式演化的 Schema Registry,用于从其他数据源轻松流式传输的 Kafka Connect 等。
数据库到 Kafka,Kafka Streams 进行分布式流处理,最近使用 KSQL 对 Kafka topic 执行类似 SQL 的查询等等。
Kafka 快速,易于安装,非常受欢迎,可用于广泛的范围或用例。从开发人员的角度来看,尽管 Apache Kafka 一直很友好,但在操作运维方面却是一团糟。
因此,让我们回顾一下 Kafka 的一些痛点:
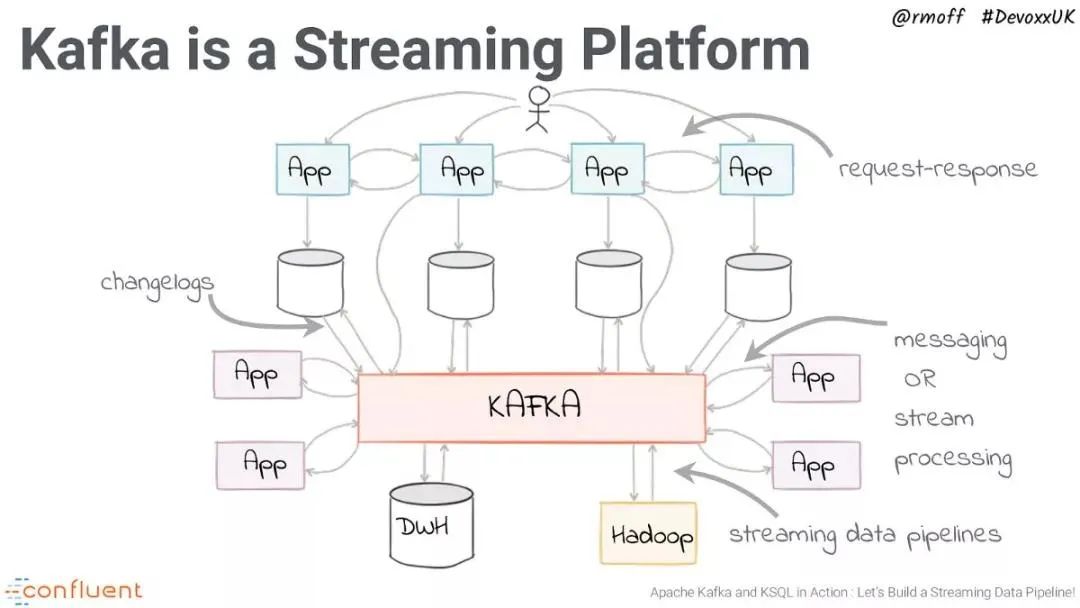
Kafka 演示[2]
Kakfa的诸多痛点如下:
-
扩展 Kafka 十分棘手,这是由于 broker 与存储数据的耦合架构结构所致。剥离一个 broker 意味着它必须复制 topic 分区和副本,这非常耗时。
-
没有与租户完全隔离的本地多租户。
-
存储会变得非常昂贵,尽管可以长时间存储数据,但是由于成本问题却很少用到它。
-
万一副本不同步,有可能丢失消息。
-
必须提前计划和计算 broker、topic、分区和副本的数量(确保计划的未来使用量增长),以避免扩展问题,这非常困难。
-
如果仅需要消息传递系统,则使用偏移量可能会很复杂。
-
集群重新平衡会影响相连的生产者和消费者的性能。
-
MirrorMaker[3] Geo 复制机制存在问题。像 Uber 这样的公司已经创建了自己的解决方案来克服这些问题。
如您所见,大多数问题与操作运维方面有关。尽管安装起来相对容易,但 Kafka 难以管理和调优。而且,它也缺乏应有的灵活和弹性。
Pulsar 由 Yahoo!在 2013 年创建,并于 2016 年捐赠给 Apache 基金会。Pulsar 现在是 Apache 软件基金会的顶级项目。
Yahoo!、Verizon、Twitter 等公司已在生产中使用它来处理成千上万消息。它具有运行成本低、灵活等特性。Pulsar 旨在解决 Kafka 的大部分难题,使其更易于扩展。
Pulsar 非常灵活:
它既可以应用于像 Kafka 这样的分布式日志应用场景,也可以应用于像 RabbitMQ 这样的纯消息传递系统场景。
它支持多种类型的订阅、多种交付保证、保留策略以及处理模式演变的方法,以及其他诸多特性。
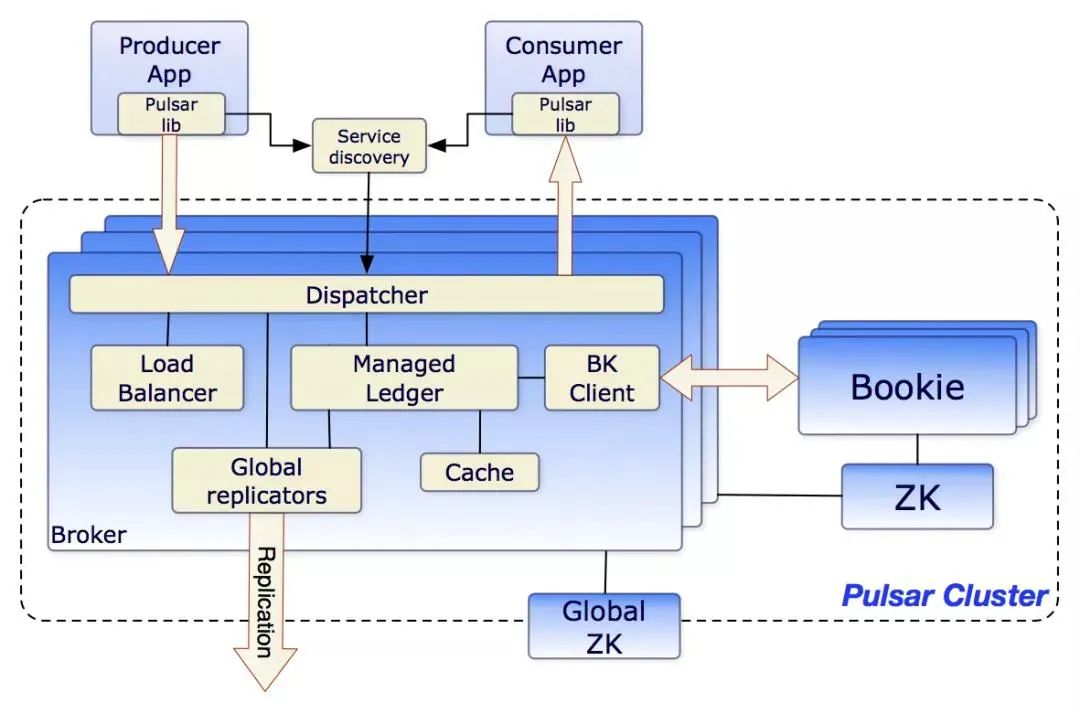
Pulsar 架构图[4]
Pulsar 的特性如下:
-
内置多租户,
不同的团队可以使用相同的集群并将其隔离,解决了许多管理难题。它支持隔离、身份验证、授权和配额。
-
多层体系结构:
Pulsar 将所有 topic 数据存储在由 Apache BookKeeper 支持的专业数据层中。
存储和消息传递的分离解决了扩展、重新平衡和维护集群的许多问题。它还提高了可靠性,几乎不可能丢失数据。
另外,在读取数据时可以直连 BookKeeper,且不影响实时摄取。例如,可以使用 Presto 对 topic 执行 SQL 查询,类似于 KSQL,但不会影响实时数据处理。
-
虚拟 topic:
由于采用 n 层体系结构,因此对 topic 的数量没有限制,topic 及其存储是分离的。用户还可以创建非持久性 topic。
-
N 层存储:
Kafka 的一个问题是,存储费用可能变高。因此,它很少用于存储"冷"数据,并且消息经常被删除,Apache Pulsar 可以借助分层存储自动将旧数据卸载到 Amazon S3 或其他数据存储系统,并且仍然向客户端展示透明视图;Pulsar 客户端可以从时间开始节点读取,就像所有消息都存在于日志中一样。
-
Pulsar Function:
易于部署、轻量级计算过程、对开发人员友好的 API,无需运行自己的流处理引擎(如 Kafka)。
-
安全性:
它具有内置的代理、多租户安全性、可插拔的身份验证等特性。
-
快速重新平衡:
分区被分为易于重新平衡的分片。
-
服务器端重复数据删除和无效字段:
无需在客户端中执行此操作,也可以在压缩期间删除重复数据。
-
内置 Schema registry(架构注册表):
支持多种策略,易于操作。
-
地理复制和内置 Discovery:
易于将集群复制到多个区域。
-
集成的负载均衡器
和 Prometheus 指标。
-
多重集成:
Kafka、RabbitMQ 等。
-
支持多种编程语言,
例如 GoLang、Java、Scala、Node、Python…...
-
分片和数据分区在服务器端透明进行,
客户端不需要了解分片与分区数据。

Pulsar 特性列表[5]
Pulsar 入门非常容易,使用前提是安装 JDK。
①
下载 Pulsar 并解压缩(备注:目前 Apache Pulsar 最新版本为 2.7.0):
$ wget https://archive.apache.org/dist/pulsar/pulsar-2.6.1/apache-pulsar-2.6.1-bin.tar.gz
$ wget https://archive.apache.org/dist/pulsar/pulsar-2.6.1/connectors/{connector}-2.6.1.nar
③
下载 nar 文件后,将文件复制到 Pulsar 目录中的 Connectors 目录。
Pulsar 提供了一个称为 Pulsar-Client 的 CLI 工具,我们可以使用它与集群进行交互。
$ bin/pulsar-client produce my-topic --messages "hello-pulsar"
$ bin/pulsar-client consume my-topic -s "first-subscription"
举一个客户端示例,我们在 Akka 上使用 Pulsar4s。
首先,我们需要创建一个 Source 来消费数据流,所需要的只是一个函数,该函数将按需创建消费者并查找消息 ID:
val topic = Topic("persistent://standalone/mytopic")
val consumerFn = () => client.consumer(ConsumerConfig(topic, subscription))
然后,我们传递 ConsumerFn 函数来创建源:
import com.sksamuel.pulsar4s.akka.streams._
val pulsarSource = source(consumerFn, Some(MessageId.earliest))
Akka 源的物化值是 Control 的一个实例,该对象提供了一种"关闭"方法,可用于停止消费消息。现在,我们可以像往常一样使用 Akka Streams 处理数据。
val topic = Topic("persistent://standalone/mytopic")
val producerFn = () => client.producer(ProducerConfig(topic))
import com.sksamuel.pulsar4s.akka.streams._
val pulsarSink = sink(producerFn)
完整示例摘自 Pulsar4s[6]:





