
撰文| Brett Simpson等
来源| Arete Research
编译| 孙茜茜 微胖
长期芯片投资者应该关注什么类型的公司? 强大的市场需求究竟需要产品的哪种创新? AI芯片销售额将达到一个怎样的量级?这份简短的报告会告诉你一个参考答案。
9 月 18 和 19 日,在加州山景城举办了 AI Hardware Summit 会议,这是目前唯一专门致力于开发用于神经网络和计算机视觉硬件加速器生态系统的活动。
会上,来自 AI 芯片初创企业、半导体公司、系统供应商/ OEM、数据中心、企业、金融服务、投资者和基金经理等 250 多位先进技术领导者们,为新兴的 AI 芯片市场构建了一幅全面的架构路线图。
本文作者 Brett Simpson 等人是市场研究机构 Arete Research 的高级分析师。在参加完本次会议后,他们将一些新的观察和所感写下来,形成了这份简短的小报告「AI Silicon: New Dawn for Compute」。从题目可以看出,作者非常看好 AI 芯片的前景。
以下是报告的中文译文:
人工智能硬件峰会的五大要点:
-
几乎所有使 AI 计算加速的都是 7nm 芯片,由台积电制造。
另外,我们还看到了一系列新的高速接口芯片 (Serdes 56 / 112gbs)。
-
英伟达依旧是训练领域之王,我们将会看到其新款计算卡 Tesla T4(使用了全新的 12nm 制程工艺 图灵架构)的广泛使用。我们认为,它将在
2019 年继续占据主导地位。
长远来看,我们对 AI 较少依赖于 CUDA 和 GPU 的状况感到担忧。
-
我们认为 Intel 的 7nm AI 芯片(由台积电代工)支持 112GBs Serdes 和高速 DRAM。
明年,在 Cascade Lake 服务器中,DL Boost INT8 会协助提高深度学习推理性能。
-
所有的云计算服务商都在开发内部的芯片
,加速计划是不公开的。这种垂直推进是对芯片制造商的一个主要威胁。
-
在五年的时间中,我们看到:
新的模拟计算机
(神经形态)
的进步,
纳米线
对数字计算的部分挑战,
硅光子
代替了 SerDes(112GBs 以上),以及
更高速的存储器
对 AI 性能提升的助益。
未来十年,AI 芯片将不仅是半导体领域最有前途的增长领域之一,还可能扰乱传统的计算机市场。
专门针对 AI 开发的软件还有 99%没写出来。如今,只有不足1% 的云服务器为AI加速服务(今年的服务器总数为 5 百万台),企业服务器则是几乎零举动。训练和推理的工作量正以较低的基数倍增,但市场似乎一致认为,今天的加速硬件(GPUs,CPUs, FPGAs)已经远远满足不了市场的需求
——在我们看来,我们需要实现吞吐量的巨大飞跃(100 倍),以扩大 AI 的规模,并让 AI 变得无处无在。
好消息是,即将迎来结构性的创新,但是其作用需要一段时间才能显现出来。
2019 年以后,我们将看到:新的流程技术(7nm),新的计算机功能结构(芯片上的神经网络),新的芯片连接(56/112GBs SerDes),新的内存方法(HBM3,SRAM on-chip 等)和新的包装技术,所有这些都能大规模提升性能。
芯片行业正在进行创新反思,因为芯片的发展不能过多依赖制造业的萎缩来取得进展。机会来了。我们会继续看到,对长期投资 AI 芯片的投资者而言,投资台积电和主要的 DRAM 制造商仍是最佳选择。
我们上周参加了人工智能硬件峰会,了解了很多 AI 芯片替代品的现状。
有一件事是清楚的:我们从未见过如此多的公司(无论大小)像今天这样、进军新的芯片市场,毫无疑问,未来几年将会是一个令人着迷的时期,我们一定能见证这个市场的整合过程。
继谷歌的 TPU 领先之后,每个云计算服务商都在做内部的 AI 芯片。问题在于,要想影响市场的情绪,这一切需要的时间有多长。
毕竟,谷歌的 TPU 芯片已经到了第三代(2016 年中期推出第一代 TPU),但仍然承载不了 Tensorflow(或其他框架)所有工作量。
我们认为,其他云计算服务商将在 2020 年验证并量产他们的第一款 AI 芯片。
造新的 AI 芯片,有两种通用方法。
第一种方法是,在系统上进行创新,以更快的 I/O 和外部内存接口(英伟达、英特尔等)为重点来扩展性能。
第二种方法是,把所有的数据集中保留在芯片上(芯片上的神经网络)——包括大量的小核和芯片内存,以减少对外部 DRAM 的需求。第二种方法将在未来 6 个月内实现第一批 AI 芯片的商业化,但我们认为,7nm 工艺才是促使市场为其买单的优势(也就是 2020 年的增长)。
围绕人工智能的软件栈在快速发展,云计算服务商也推出了开源适配器,以支持在其框架中运行的各种芯片(例如 Tensorflow XLA、Facebook Glow)。随着新神经网络的成熟,每个人都会认同可编程性和灵活性的重要性。
这意味着,7nm 芯片潜在的目标是,16 位浮点运算的运算能力至少要达到 10TOPS。人们真正关注的是如何通过提高效率来提高性能,如通过支持稀疏数据结构、降低精度、使用 mini-batching、加快芯片互联速度(112GB Serdes)、使用更快的内存接口(远超 HBM2),以及新的多芯片先进封装。
英特尔:AI 领域的玩家

当人们普遍不再依赖通用 CPU 时,也不再十分信任英特尔计划在未来几年内为 AI 引入一些新的优化措施这件事。
英特尔去年 (2017 年) 的 AI 收入约为 10 亿美元,Xeon CPUs 也将继续在 AI 推理和 AI 训练方面发挥重要作用。
例如,英特尔在 Cascade Lake 的服务器架构中添加了大量新的指令,以提高其推理性能(声称在精度为 INT8 的情况下、性能提升了 11 倍)。我们预计,这些扩展将与 AMD EPYC2 规格区别开来。
我们还相信,英特尔的下一个 ASIC 芯片(将于 2019 年采样)将由台积电代工(7nm)
,将具有一些关键的专有接口,这将显著提高它的性能。
虽然当下 GPU 以低速(PCIE-3)与 CPU 相连,但是我们预计,新的服务器将 PCIE-4(16GB),仍会是数据输入 GPU 的关键瓶颈。
相比之下,我们认为,英特尔将在其 Xeon CPU 和 7nm Nervana 芯片之间构建专有接口,速度可达 112GB。英特尔正计划推出一种新的高带宽内存接口(这对云服务提供商来说,是一个关键的关注点),并积极参与新的多芯片包装。AI 的加速会导致更多的 CPU 被停用,英特尔正寻求通过围绕 Xeon 构建外围解决方案来获取价值。
时间会证明这是否有效,但为了在 2020 年对抗英伟达,这个目标十分明确。
英伟达:标准制定者
英伟达的 GPU 目前仍然是 AI 计算领域的王者,他们有实际的收益(支持所有的框架,所有的云计算服务商,所有的 OEM),他们的新品将有显著的性能提升——我们认为,其 T4 将被广泛采用,其新的 DGX2 服务器将在今年售罄。目前没有什么引人注目的替代品可供选择,我们认为,英伟达将继续占据主导地位(至少到 2019 年),但有两个主要问题让我们怀疑,英伟达是否能长期维持其领导地位:
首先
,我们认为,很明显的一点是,随着谷歌和 ONNX 等公司的努力,英伟达的软件护城河 (CUDA) 将变得不那么重要。
云计算服务商正积极提供开源插件,用于替代芯片解决方案,以支持 Tensorflow、Pytorch、CNTK、coff2 等框架,从而降低进入新的 AI 处理器的软件门槛。
其次
,是英伟达训练和推理芯片的经济性——虽然它们可以为许多 AI 工作节省 CPU,但是销售卡的超高利润率与昂贵的内存捆绑在一起(V100 是每张卡 1 万美元,P4 可能是每张卡 2000 美元),这只会让云端玩家拥抱其他架构。
图 1: 微软关于计算选择强调了我们的观点,即需要快速发展 GPU。
来源:微软在人工智能硬件峰会上的 PPT
尽管如此,英伟达有巨大的资源来超越竞争对手 (尤其是初创企业),它致力于每年为 AI 推出一种新的架构,可能在 2019 年首次推出 7nm 解决方案。
V100 和 T4 在很大程度上都被视为英伟达在 AI 领域的第一颗转换芯片(不再只是通用 GPU),因为它们是第一个支持张量核心和较低推理精度的芯片(INT8)。
随着英伟达 7nm 芯片的推出,我们期待,其性能在 2019 年会有另一个大的飞跃——有很多大幅提升吞吐量和延迟以提升效率的方法,我们预期,其下一代芯片更像以 AI 为中心的 ASIC,而不是 GPU。
云端的消费者告诉我们,他们使用 V100 GPU 来进行训练的频率很低(低至 15%),因为他们用 GPU 只是为了训练单一的神经网络。他们希望英伟达能将 GPU 虚拟化——尽管对 AI 计算的需求永无止境的,但这可能会给英伟达的 GPU 增长带来压力。
此外,英伟达如今拥有芯片对芯片的快速接口(NVlink2),运行速度为 25Gbs(远远超过仅 8GB 的 PCIE-3 或 16GB 的 PCIE-4)。我们预计,到 2019 年底,英伟达将支持 56Gbs 甚至 112 GB 的服务器,因为有些替代方案可以提升这些规格。
我们认为,英伟达的下一代架构将在 2019 年的 7nm 芯片上出现(超过 Volta / Turing),这将大大决定它能够在多大程度上拉开市场差距。
AI 芯片的替代品——即将到来
随着谷歌 TPU 的推出,每个云计算服务商内部都有了做 AI 芯片的项目,我们认为,这将在未来 18 个月内得到验证。
有些人公开表达了自己的意图。微软甚至在峰会上设立了招聘平台,这就是它渴望建立团队的表现。但有关这些项目的状况,我们无从得知:云计算服务商没有公开他们造芯计划的任何细节,所以我们不知道他们的项目进展。
我们认为,第一代转换芯片将像谷歌两年前对 TPU 的判断一样,专注于推理。Google Brain 的报告指出了一个具有讽刺意味的事实:当芯片行业达到摩尔定律的极限之际,AI 计算却出现了指数级增长,因此,架构(和软件协同设计)将成为关键的推动因素。
谷歌不仅使用 TPU 来处理越来越多的工作量,还用 GPU 测试大量即将上市的新系统。
这 50 多家创业公司的工作都是为了将他们的平台商业化,我们预计在未来 12 个月内会有 6 家公司推出首款转换芯片,将于 2020 年推出第二款(7nm 芯片)。
即使一些人工智能初创企业2019 年的销售额就可能达到 1 亿美元,但我们认为,到 2020 年才会有人超越这个数字。有许多令人印象深刻的初创公司,但其中许多还没有流片,因此很难对其性能进行验证。
云计算服务商们希望了解新的 AI 芯片的系统性能,因此,他们帮助建立了一个新的基准测试标准,名为 MLPerf。
我们认为,这将是分析特定模型的训练时间 (如果不要求准确性) 的关键标准,也有助于与目前市场领军者英伟达的培训平台进行比较 (英伟达尚未加入 MLPerf)。
很明显的一点是,许多初创企业以前从未进入过主要的云数据中心,也从未在前沿制造过芯片。
此外,只有少数参与者之前与云有密切的关系、在以云计算芯片为关键任务构建一个工程团队方面有丰富的经验。
表格 1:MLPerf 将通过一系列数据集和模型限制 AI 芯片的训练时间
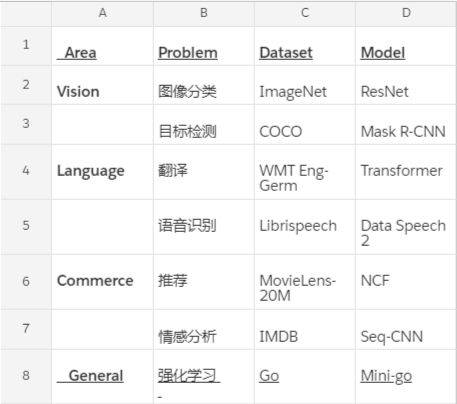
来源:MLPerf.com
云加速:巨大的市场机遇
以今天一台典型的云服务器配置为例(包括 2 个插座,10 核 Xeon E5 就是最受欢迎的销售平台之一),有大约 660 毫米的裸片大小来处理主 CPU 计算 (即两个 330 毫米的 CPU 芯片),主要由英特尔提供。但是,针对 AI 加速的服务器(比如英伟达 DGX-1)已经有多达 10 倍的硅芯片大小来处理计算加速,正如图 2 所示。
图 2:与大多数 Xeon 服务器相比,AI 加速训练服务器的芯片面积增加了大约 10 倍
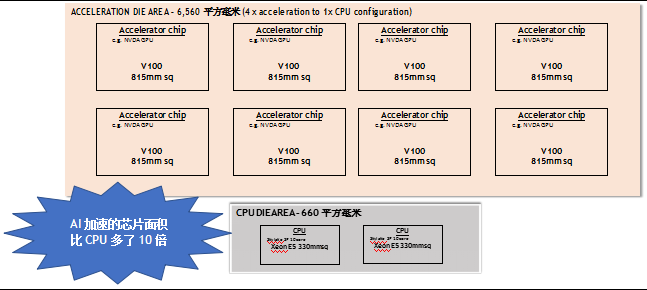
来源:Arete Research. 基于 NVDA 的 DGX-1V 服务器的模具区域。
这个裸芯片大小与 CPU 裸芯片大小的比率只会增加,因为随着时间的推移,每 CPU 4 个加速卡会上升到 6 个和 8 个。
我们相信,谷歌正计划明年将 TPU 芯片数量增加两倍。在训练应用中,英伟达的芯片需求量会继续大幅增长,而且从 2020 年开始,一大批人工智能创业公司将崛起。
但是,鉴于人工智能服务器目前在市场上的渗透率很低 (今年购买的云服务器中,只有不到 1% 的服务器支持加速度),长远来看,台积电机遇很大。
如果我们假设这种渗透率上升到 100 万加速 AI 服务器(今年低于 5 万),并且裸芯片大小通过缩小(即每台 AI 服务器 6,560mm)保持不变,这将转化为大约每年 20 万晶圆,或 30 亿美元的代工收入(假设每片晶圆 15,000 美元,收益率 55%)。这就是为什么我们继续认为台积电将作为 AI 芯片的长期关键受益者之一。
长远来看,还有哪些新技术?
峰会期间还有许多其他新兴技术在 3 - 5 年的视野中看起来很有趣。
显然,人工智能的边缘计算正在智能手机中进行,我们坚信每部智能手机都将在未来 2 - 3 年内拥有专用的计算机视觉 AI 处理器(在相机周围)。
谷歌的 Edge TPU 和英伟达的 DLA 是早期可授权的例子,我们看到 ARM 现在提供专用的 AI 许可证解决方案,而 Qualcomm,华为海思和寒武纪以及联发科则提供一系列智能手机和物联网解决方案。
一系列具有增强 AI 规格的嵌入式 SOC 即将推出,适用于相机,机器人,汽车等。英伟达的 Xavier 就是一个例子。我们将在即将发布的报告中研究自动驾驶汽车的汽车路线图,其中,AI 加速将发挥核心作用。
从长远来看,尽管存在摩尔定律的挑战,我们仍可以看到正在开发的一些新技术,以扩展计算性能。
其中一个更令人印象深刻的演讲来自 Rain Neuromorphics 和 Mythic,他们从五年的时间角度,谈了谈模拟计算商业化,比如使用类似大脑突触那样的松散几何形状,解决功率限制。
此外,Ayar Labs 阐述了为什么他们在硅光子微型化方面的突破,将导致更快的芯片互连(超过 112GB Serdes)的解决方案。
随着 Exascale 计算机预计将在 3 - 4 年内出现在我们面前,我们认为,人工智能正在全面推动反思,以实现性能的指数增长。
必要的披露
整体行业风险:算法变化可能需要比预期更长的时间,ETH 价格可能上涨到足以抵消近期的回报阻碍和难度变化,并且可能出现一种新的 GPU 可挖掘的加密货币,从而推动 GPU 需求。
不断恶化的全球经济环境可能会影响半导体行业,迅速造成严重的供过于求,晶圆厂利用不足,平均售价下降或库存减少。在 09 年期间,半成品销售下降 10%(外存储)。所有部门的竞争都很激烈。
智能手机领域是一个充满活力的市场,有数十家厂商生产着需要复杂软硬件集成技能的产品。虽然所谓「旗舰」设备的市场空间受到区分「黑色平板」(即主要运行 Android OS 的标准触摸屏设备) 困难的限制,但是,很难预测哪一家厂商与哪种特定型号相关。
AI芯片市场最强预判:华为苹果高通为何数亿美元豪赌7nm?
主流核心玩家比任何时候都渴望「爆款」的出现,以刺激阈值不断提升的消费者神经。从去年后半段开始风靡的「AI 手机」当之无愧成为「爆款」的热门关键词。人们期待 AI 拓宽手机终端的边界,一如当年智能机对功能机的颠覆。然而,如果 AI 手机的角逐只停留在参数对比和跑分排位,那么竞争远未触达本质。

撰文 | 四月
一面是市场销量增长乏力,一面是巨头对手步步紧逼,手机业竞争的残酷指数再度升级。
金九银十,手机市场亦是如此。在不到半个月的时间里,华为 Mate20、苹果 iPhone X 二代两款全球最强旗舰机即将揭开最后面纱,安卓阵营里的其他玩家 OPPO、小米、联想也在积极准备亮出更强底牌。
手机战场正酣时,来自 IDC 的全球手机市场报告却释放出不容乐观的信号:智能手机行业增速在过去一年遭遇了史无前例的滑铁卢,并且主要来自于中国智能手机市场的乏力。
主流核心玩家比任何时候都渴望「爆款」的出现,以刺激阈值不断提升的消费者神经。而从去年后半段开始风靡的「AI 手机」当之无愧成为「爆款」的热门关键词。人们期待 AI 拓宽手机终端的边界,一如当年智能机对功能机的颠覆。
自一年前的麒麟 970 问世以来,「全球首款 AI 芯片」的标签无疑为国产芯打上了一针强心剂。自 2000 元不到的荣耀 到 5000 元以上的华为 P20 Pro,麒麟 970 几乎把华为的所有机型都加持了一个遍。紧随其后发布的是苹果内置有神经网络加速模块的 A11 Bionic 仿生处理器,Face ID、Animoji 等创新应用让 iPhone X 惊艳四座。
而今年初高通开放的人工智能引擎 AI Engine 则让骁龙 845 在异构基础上实现了 CPU、GPU、DSP 等众多硬件模块的协同处理,让安卓玩家在终端侧就能够实现算法优化和 AI 应用。
内置AI芯片开始成为打造一款AI手机的必要条件。
可以预见的是,在即将开打的2018新机换购大战中,围绕高通、苹果、华为三大芯片巨头展开,以及三星、谷歌、联发科等选手积极参与的“AI芯”战场必将升级为要塞之地,头号玩家非骁龙855、麒麟980和苹果A12处理器莫属。
继去年的10nm工普及艺之后,摩尔定律快速进入到7nm世代。三大巨头不惜巨资押注台积电最新7nm工艺,背后是对于芯片AI化计算趋势的笃定,同时也为三家公司率先拿下了新一轮“AI芯”战场的入场券。
但同一水平线的起跑赛道并不代表着技术实力的追平,高通、苹果、华为三家公司在手机芯片领域的能力排位仍需全面分析。
作为全球第一大移动芯片供应商,高通占据着四成以上的 SoC(系统芯片)市场份额,以远高于竞争对手的市场地位占据绝对优势。从过往的市场表现来看,安卓准旗舰芯片骁龙855在年底发布后将统治全球智能 SoC 榜单大半年。
而与高通主要供货于安卓玩家不同,苹果A系列与华为海思芯片主要用于自产自用,凭借两家公司全球 Top3 的手机出货量带动其芯片出货。
低调的苹果虽然很少拿自家的处理器性能作为卖点,但一如苹果产品本身,每次A系列处理器的实际表现都能轻松凌驾于整个安卓阵营,即将出货的A12也不会例外。
过去一年,华为海思用麒麟 970 优秀的参数跑分向市场证明,高通和苹果在手机处理器领域并非不可战胜,但在过于激进的降库存战略已经引发部分「花粉」(华为用户)不满。这样的背景下,麒麟 980 承担着背水一战的民族使命,在产品周期已经领先的基础上,以求追平甚至超越同期对手芯片,摘下名副其实的安卓旗舰桂冠。
然而,如果AI手机的角逐只停留在参数对比和跑分排位,那么竞争远未触达本质。
从智能手机到人工智能手机的更新换代,市场的最大诉求点和期待究竟是什么? NPU 的打磨只为现有文字处理、语义理解、图片识别等功能的加速?特别开辟的神经网络加速器仅为 Face ID 等原生应用而建?
直面争议与质疑,别让AI手机仅止步于概念。
3亿美元入场券

手机处理器形态千万,却也逃不开IP垄断户ARM的影响。一款处理器的CPU性能强弱,除了和自主研发的架构相关,最重要的影响因素就来自于ARM的CPU核心。
实际上,ARM正是新一代7nm工艺背后最为有力的推动者。
今年6月,ARM发布了新一代移动处理器Cortex A76架构,使用7nm工艺制造,频率可达3GHz。和前代的A75相比,Cortex A76性能提升了35%,功效提高了40%。更为重要的是,Cortex A7能够提供高于现有机器学习的4倍性能,这恰恰也是苹果、华为、高通、联发科等一众手机芯片厂商翘首以盼的增长点。
据市场预测,目前开发10nm芯片的成本超过1.7亿美元,而7nm则达到了3亿美元,5nm更是高达5亿美元,3nm直接将超过15亿美元。随着工艺成本的大幅提升,仅高昂的入场券门票就足以甩开中低段位选手,在手机IC领域如今也只有华为、高通、苹果等敢于投入跟进这场豪赌。
相比三星的激进策略,稳扎稳打的台积电似乎更受手机厂商青睐,今年来自苹果、华为、高通的7nm订单全都押注在了台积电产线上,今年初正式投产预计明年将引入EUV光刻工艺。
按照台积电CEO魏哲家的说法,到2018年底将有超过50个产品完成7nm设计定案(Tape out)。其中,AI芯片、GPU和矿机芯片占了大部分的产能,其次是5G和应用处理器(AP)。与10nm工艺相比,台积电的7nm工艺密度提升为1.6倍。台积电声称其7nm工艺将性能提高20%,功耗降低40%。
电子创新网创始人张国斌评价道,不同于10nm仅用于移动处理器,7nm工艺将适用于各类处理器,所以7nm将是半导体工艺上的一个极其重要的工艺节点。可以预见的是,围绕这个节点EDA公司和IP将开发大量产品,7nm工艺将或类似于28nm工艺节点,将维持一段较长的生命周期。
此外,随着集成电路工艺要求的提升,针对芯片接点引脚和电路板连接的封装工艺也更为先进。
根据台积电公布的7nm工艺资料来看,台积电为7nm工艺开发了系统级封装技术SiP,它被认为是5G高速连接时代的重要封装技术,或将为后续的7nm手机引入5G功能提供预留便利。
芯片战略需要长期投入,在流片之前,长期的设计投入与验证布局更能体现手机和IC 厂商的前瞻性。
华为子公司海思半导体进军手机处理器至今已经5年有余,从最开始泥沙俱下的K3V2到去年广受好评的麒麟960,在风风雨雨中已经迭代了6代产品。有报道指出,在总共1万人的海思团队中,有3000人在做手机芯片。
自推出手机处理器以来,华为一直坚持在自家高端产品使用自家海思的处理器,虽然前期饱受非议,但在几乎所有的国产手机厂商都受制于高通或联发科的当下,尤其在「中兴事件」之后,华为在芯片自研技术道路的坚持获得了更多人支持。
与华为一样,芯片是苹果最重要,也是最为神秘的部门。
从2010年发布iPhone 4开始,苹果就采用了自主设计的A4处理器。苹果的芯片研发历程最早可以追溯到2007年。据首席财务官卢卡·马斯特里称,苹果每年数以十亿美元计的资金投入中,大部分都花在研发各种诸如芯片、传感器的基础技术上。
巨头很早就意识到,自研芯片能够让其将尽可能多的技术和生产流程掌握在自己的手里,从而实现对供应链的完全控制,让更多的创新技术变得难以复制。
在解决了设计研发、量产工艺等难题之后,芯片厂商摩拳擦掌为上市准备。然而,产线供货能力吃紧却成为三大巨头需要共同面对的当务之急。
就在上个月,台积电工厂遭到病毒攻击,并导致数条生产线被迫中断,而其中7nm制程的生产基地就被列入受影响的范围之中。对于即将开售的iPhone X二代及其A12 芯片,以及搭载麒麟980的华为Mate 20是否会受到产线停摆的影响仍是个未知数。
最强赛场
ARM和台积电为三大芯片巨头建立了牢固的先发优势,但核心的芯片架构设计才是各家形成差异化竞争格局的核心。

麒麟980将继续采用主芯片+NPU专用模块的设计。核心架构层面, CPU为ARM最新的四大核A76和四小核 A55,最高主频 2.8GHz,基带由Cat.18升级到 Cat.19。
专用AI 硬件处理单元层面,华为将继续沿用寒武纪IP核,预计将会是今年5月推出的第三代终端IP产品Cambricon 1M。
该NPU同样采用台积电7nm工艺生产,提供2Tops、4Tops、8Tops三种规模的处理器核,并支持多核互联,其8位运算效能比达5 Tops/W(每瓦5万亿次运算),性能比前任麒麟970采用的寒武纪1A高10倍。

值得注意的是,此前多份报告称华为麒麟980将采用ARM Cortex A77 CPU多核心,但随后遭到ARM官方的否认,麒麟980配备的是Cortex A76,虽然A 77性能更高但尚未公布。
而关于麒麟980将搭载华为新一代的自研GPU的传言也不攻自破。根据最近外媒关于麒麟980的参数信息,麒麟980将继续采用ARM提供的GPU Mail系列Mail-G72 MP24。相比麒麟970采用的Mail-G72 MP12系列,麒麟980的GPU核数提升到24核心,增加一倍。
今年苹果的A12芯片暂未被曝出大的升级处理。

此前曾多次准确爆料的移动处理器博主i冰宇宙表示,苹果A12可能沿用A11架构,处理器跑GeekBench 4单核成绩是5200分,而多核性能是13000分上下,相较于A 11跑分成绩,性能提升约25%,足以秒杀同期芯片。
目前,苹果正在解决功耗问题,7nm情况下平均功耗依然比预期高出23%。外媒评论称,苹果将重新设计功能的iOS12,此举有望降低对A12处理器的杀伤力。
值得注意的是,去年苹果发布的A11处理器只能称为仿生芯片,今年A12处理器定然将会在AI功能上大有改进,以达到真正的AI芯片级别。

对于高通而言,相比去年仅有SDK实现异构计算性能的提升,今年最大的惊喜将是引入NPU内核。这与去年麒麟970搭载的NPU类似将用于提升AI性能。
作为单纯的上游芯片供应商,高通在高性能之外,还需要考虑应用场景和工艺成本等要素,在AI芯片方案上相对华为和苹果更为保守也情有可原。
今年高通引入NPU之后,也预示着在人工智能大潮下,AI芯片的设计方向最终归一于独立AI模块的设计思路,多硬件单元组合式的异构计算单从SDK层面优化难免力不从心。
而在主流AI芯片玩家之外,三星、联发科,以及谷歌等选手也在积极试探市场。
今年3月,联发科的首款AI芯片Helio P60在国内亮相,与高通骁龙845一样没有独立AI处理单元,其设计初衷是通过多颗DSP的能力来提升图像后处理的运行效率,顺便可以做些AI相关的图像处理算法。
该芯片能够称得上现在市面上能够买到的最为实惠的一款AI芯片,出货量表现不错,同时为联发科第二季度财报赢来了超预期表现。
同样在3月,三星发布了型号为Exynos 9610 的新一代处理器,采用专用AI 硬件单元,三星称之为Vision Image Processing Unit(可翻译为视觉图像处理单元),可以算作是三星真正意义上的一款智能手机AI 芯片。

而早在去年10月,谷歌在Pixel 2系列智能手机就隐藏了一个秘密武器,即谷歌自己研发的第一款移动芯片,它被称为Pixel Visual Core,它是谷歌针对消费类产品的首款定制片上系统(SOC),目前专门用于加速相机的HDR+计算,使图像处理更加流畅和快速。
但目前该芯片还处于「休眠状态」。谷歌方面表示,在更新 Android Camera API 之后,以允许第三方摄像头开发人员使用 HDR +和 Pixel Visual Core,它们将成为 Android Oreo 8.1 预览中的开发人员选项。
内行看门道
实际性能并不等于峰值参数,还需要取决于软硬件协同优化效果。这一道理在华为麒麟与苹果A系列的对比中尤为明显。
去年,华为曾用植入了寒武纪A1的NPU在性能参数上碾压A11。比如,A11 Bionic内置的神经网络引擎浮点性能仅为0.6T(即能以每秒最高6000亿次速度处理机器学习任务),而麒麟970NPU的浮点性能达到1.9T,是A 11的三倍还多。
但是别忘了,苹果是最懂得软硬件结合的手机厂商,在浮点性能不及对手的劣势下却将能够最大化利用。早在iPhone X发布之前,苹果在去年年中的WWDC开发者大会上就已经推出Metal和Core ML两个不同层面的接口供开发者调用,以加速iOS平台上的人工智能应用。
苹果曾提到A11专门为Metal 2 和Core ML设计。有半导体业内人士猜测,A11可能对DSP进行调整,在软件层面针对CPU和GPU加速的硬软件结合实现的“神经网络引擎”。
参考海外知名处理器性能跑分工具,同时也是公信力最高的GeekBench 4实测结果。麒麟970(BLA-L29的Mate 10 Pro)的GeekBench 4跑分单核是2000分左右,多核6200分左右,而骁龙845的GeekBench 4单核在2500左右、多核在8500分左右。作为对比,A11单核和多核分別在4245和10100左右。
在主核CPU之外,影响终端性能表现,尤其是图像、影像等数据处理效率的核心还是GPU性能。相比高通,华为和苹果的AI芯片此前的短板之一都体现在GPU层面。
高通的 Adreno GPU 一直都是业界标杆,据说「虐杀」一众竞争对手的 Adreno 630(骁龙 845)还只是高通 Adreno 家族的中端低功耗产品,真正杀手级别的 GPU 是强化版的 Adreno 640 和堪比 PC 显卡的 Adreno 680。
不过按照高通一贯的新品节奏,骁龙 855 究竟采用哪款 GPU 可能到今年底才会正式揭晓。
曾有早期评论提到,麒麟970的能耗比是完全被骁龙835吊打的,甚至还不如骁龙820/821,三星Exynos 8890/8895,实际使用远远无法达到国内跑分测试数据。
麒麟970的Mali-G72 MP12在跑分上确实超越了Adreno 540,但是也仅限于跑分了,麒麟970的GPU跑分完全是不计功耗的跑分强行超越了骁龙835。按照这个趋势下去,如果麒麟980继续采用Mali系列的GPU,仍然远不如骁龙845,更不用提追平下一代架构提升的骁龙855了。





