
主图:Instagram Explore。
作者 曼诺维奇(Lev Manovich)
文章出处 An expanded version of the article published in Flash Art International no. 316, September–October 2017.
在1950年代,人们对人工智慧的初始愿景是能够教导电脑执行一系列认知任务,包括下棋、解决数学问题、理解书面与口头语言,以及辨识影像内容等。今日的人工智慧(尤其是监督式机器学习[supervised machine learning]的形式)俨然成为让现代经济体更有效率且更安全的重要工具,因为它能够执行决定消费性贷款、过滤求职申请,以及察觉诈骗等功能。
相较而言,较不为人所知的是,人工智慧如今也在我们的文化生活中扮演同样重要的角色,并且使美学领域日益自动化。试想影像文化(image culture)的例子。Instagram Explore会依据我们曾按过讚的内容来推荐图像与影片。Artsy.net则是会推荐近似你正在网站上浏览的艺术作品[1]。每一种影像应用程式都会依据所谓「优美摄影」(good photography)的规范自动修正我们所拍摄的照片。有些应用程式旨在「美化」自拍照。其他应用程式则会自动编辑你所拍摄的原始影片,从而创造一系列风格各异的短片[2]。由EyeEm开发,名为The Roll的应用程式能够自动评比你所拍摄照片的美学特质(图一)。这套系统只需20张照片就能从中得知摄影者的个人风格,并从其庞大资料库中检索出类似的影像[3]。当你上传图片至EyeEm市场待售时,该服务会自动产出关键字[4]。此外,Google也设计出一套模仿专业摄影师技巧的系统,例如选择一张适合进行编辑、裁剪或使用滤镜等功能的照片(图二)。[5] 除了影像文化之外,从Spotify、iTunes,以及其他音乐服务的音乐推荐功能、电玩游戏的人物与环境产出,到流行风格的创造,都涉及人工智慧的运用[6]。

(图一):训练EyeEm美学评比系统的照片样品。来源:Appu Shaji, “Personalized Aesthetics: Recording the Visual Mind using Machine Learning,”

(图二):Neural network learned to automatically apply “dramatic mask” filter to new photos after being trained on 15,000 professional photographs landscapes. Left: original photos. Center: filter mask. Right: filtered photos.经过15,000张专业风景照片的训练后,神经网络学会如何把「戏剧面具」(dramatic mask)这项滤镜功能自动应用于新的照片上。左图:原始照片;中图:滤镜;右图:使用滤镜后的照片。来源:Hui Fang and Meng Zhang.
此种自动化是否随著时间的推移而减损了文化多样性?举例而言,应用至使用者照片的自动编辑功能是否把我们对照片的想像标准化?另外,既然我们反对单靠臆测或顺从经常毫无根据的直觉,那么我们是否能够使用人工智慧方法和大量文化资料样本来量化当代文化中的多样性与差异性,并且追溯它们如何随著时间变迁?
时至今日,人工智慧已将美学选择自动化,自动推荐我们应该观看什么、聆听什么,或如何打扮,同时也在某些美学生产领域扮演更重要的角色,例如消费性摄影(当代手机相机的许多特点都是透过人工智慧的协助)。未来人工智慧将在专业文化生产当中发挥更大的效用。越来越多时尚、标志、音乐与电视广告的设计以及其他文化产业类别的创作都已开始使用人工智慧。然而,到目前为止,主要还是由人类专家做最终决定,或是以电脑生成的想法或媒介为基础来进行实际生产。《冰与火之歌》(Game of Thrones)便是绝佳例证。电脑提出情节方面的想法,但实际的写作与节目发展还是由人类来执行。因此,我们只能讨论真正由人工智慧驱动的文化,而非从头到尾均由电脑创作的媒体产品。在此种未来情境中,人类不再决定是否应该把这些产品呈现给观众。人类只相信人工智慧会做出最好的选择。但我们还没走到那一歩。举例而言,IBM的华生(Watson)人工智慧系统在2016年创造出第一部由人工智慧製作的电影预告片[7]。然而,这套系统只是从该电影中选出适合放在电影预告片裡的诸多镜头片段,影片编辑工作仍需仰赖人类来处理。
在今日,文化生产的自动化通常使用称为「监督式机器学习」的人工智慧当代形式。作法是灌输许多类似物件给电脑,例如某一种特殊类型的电影预告片,电脑将逐渐学习到这种类型的原则。事实上,人工智慧扮演的是艺术理论家、艺术史学家,或电影学者的角色,反覆研究某一个文化领域的诸多作品,进而找出它们的共同模式。
然而,这裡有一个关键的差异。人类理论家或史学家提出的是我们能够理解的明确原则。举例而言,用于大学电影研究课程的标准教科书——《经典好莱坞电影》——为「典型好莱坞电影如何运用电影这种媒介的技术与说故事的形式?」[8] 等问题提出解答。但许多以文化实例训练人工智慧的结果,通常都是一个黑箱。人工智慧能够正确地归类我们给予它的新实例——例如,它可以决定某个特定影片是否确实属于「经典好莱坞电影」。但我们无法得知电脑的决策过程。同样地,它能够区分不同艺术家或电影导演的作品,并产出相同风格的新作品;但我们通常无法得知电脑究竟学习到什么。
此乃人工智慧应用于文化领域的关键议题之一。机器学习的结果是否可解读,还是它只是一个黑盒子,虽有生产效率,但却无益于人类对该范畴的理解?将机器学习扩大应用于新文化物件的创造,是否能够向我们呈现既存物件的共同模式?即便真是如此,它会以让非电脑科学背景的人也能理解的形式出现吗?此外,利用机器学习来生产电影、广告、设计、影像、音乐等等的公司,是否愿意揭露它们所学习到的事物?
幸运的是,学术界业已开始使用人工智慧和其他计算方法来研究文化,其研究成果已发表与公开,在这些研究中所使用的符码与资料集也可供所有人取得。自2000年代中期起,电脑科学与社会科学的研究者已开始使用越来越多的样本,以量化方法分析当代文化。有些研究著重内容特徵的量化与数以十万计或百万计的文物之美学。其他研究则是建立模型,预测哪些文物会受欢迎,以及它们的特徵如何影响他们受欢迎的程度(或是可被记忆、有趣、美感,或创意的程度)[9]。
这些研究大多使用分享在社交网络上的庞大内容样本,以及在这些网络裡的使用者行为资料。研究者发表成千上万的论文,运用电脑分析在最受欢迎的社群网络与分享媒体(例如Weibo、Fabebook、Flickr、YouTube、Pinterest、Tumblr,以及Instagram)上的影像、影片、贴文与行为之特徵。
让我们以关于Instagram的研究为例。为了聚焦于使用量化研究方法的论文,我在「Instagram」这个名称后面加上「资料集」(dataset)一词,然后用Google Scholar搜寻。「Instagram dataset」的搜寻结果有9,210篇期刊文章与会议文章(检索日期为2017年7月15日)。这裡有些2014至2017年发表的论文,可以让你初步理解在此研究中所提出的问题。其中一篇论文分析了Instagram上最受欢迎的主题,以及发布共同主题的使用者类型[10]。另一篇文章以Instagram的410万张照片为样本,测量使用滤镜对于浏览与评论次数的影响[11]。还有另一篇论文从Instagram收集了550万张有脸孔的照片,分析其时间与使用者族群趋势。这些自拍照来自世界上117个国家,该篇论文也检验了另外三种上传这些自拍照原因的假设。于2017年发表的一篇论文则是使用一亿张在世界上44座城市拍摄的Instagram照片,分析其人物穿著与流行风格[12]。
那么,以现有的数位化档案和计算方法去分析历史文化中的模式又有何进展?这类研究中最有趣的实例包括〈迈向对艺术影响的自动化探索〉[13]、〈测量当代西方流行文化的演变〉[14]、〈拍摄时间、拍摄课程与流行电影的加速发展〉[15]、〈无所不在的艺术:艺术资料分析的多重任务深度学习〉[16]。
第一篇论文提出一个自动探索艺术家之间相互影响的数学模型。研究者以66位知名艺术家共1,710幅画作的图像来测试这个模型。虽然该研究发现的某些影响与艺术史学者经常描述的一样,但此模型亦指出存在于艺术家之间的其他视觉影响,所以还是有提供新的资讯。第二篇论文使用1955至2010年间共464,411首歌曲的资料集来检视流行音乐的变迁。该资料集涵盖「各式各样的流行音乐类型,包括摇滚乐、流行乐、嘻哈音乐、金属音乐,以及电子音乐」。研究者的结论是,随著时间的推移,出现「音调转换的限制」与「音色风格的同质化」。换言之,音乐的变化减少了。第三篇论文则是分析1912至2013年间共9,400部英语电影在平均拍摄时间方面的逐渐变化(图三)。第四篇论文在432,217张艺术图像的资料集中,使用机器学习来预测艺术家姓名、作品创作时期,以及作品使用的媒材。
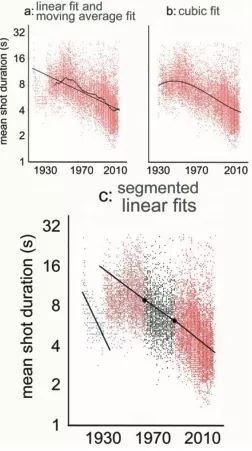
(图三):图表显示1912至2012年间共9,400部电影逐渐减少的拍摄时间。每部电影的平均拍摄时间以一个点表示。这些图表显示出可能符合这些资料的不同线图。来源:Cutting, J. E. & Candan, A. (2015)
这些论文,以及其他许多论文,都包含宝贵且具有原创性的见解,若只靠「纸上谈兵」或採用小型团体民族志观察是不可能获得这些见解的,因而必须仰赖计算方法。由于这些研究大部分都使用统计学途径,因而有一个共同的限制。「统计学」的意义之一,就是它是某个资讯集合的特徵摘要,但我们都知道,摘要会排除某些细节,因为它小于原始资讯。因此,若我们为了找出模式或提出相关性,而使用统计学途径来概述某个文物收藏,或有关文化行为(例如分享、按讚,或评论社群网络上的特定图像)资讯的某个资料集,这些途径就无法适用于此资料集中的所有内容。举例而言,前述关于Instagram图像滤镜影响的论文,在分析数百万张照片之后,发现「使用滤镜的照片被浏览与被评论的可能性将分别增加21%和45%」。但在该样本中,绝对有许多其他使用滤镜的照片并未获得更多的浏览数或更多的评论,因为统计学预测只在某些时刻有效。(虽然针对文化类型与时期的非量化研究,例如《经典好莱坞电影》,也只是概括提出某一特定电影集合所共有的艺术手法与传统,但它们亦特别分析其他无法被化约为属于这些传统的重要电影。还记得罗兰.巴特(Roland Barthes)的著作《S/Z》并未宣称要描述巴尔札克(Balzac)短篇故事中的所有符码,亦未主张它们构成了某种系统。)[17]
对科学而言,一个只有某些时候有效的统计模型是个问题,因为科学假设这种模形应该准确捕捉到某个现象的特徵。然而,我们可以在不受这类假定限制的情况下使用计算方法研究文化,这便是我称为「文化分析学」(Cultural Analytics)的另类研究典范[18]。在这个典范中,我们并不想「解释」大部分或甚至是某些使用简单数学模型的资料,并把无法透过我们的数学模型解释的其馀资料视为「错误」或「噪音」。我们也不想假设文化变异是一种相对于平均值的偏差。我们既不想假定在某一种类型媒介中佔大量比例的作品只有一种或几种模式,例如「英雄般的旅程」、「黄金比例」,或「二元对立」,也不想预设如某些19世纪艺术史学者所宣称的每一种文化都历经相同的几个发展阶段。
我相信,我们可以在无须假设文化多样性是某些类型或结构变异所造成的情况下来研究文化多样性。这是否意味著我们只对差异感兴趣,以及我们不计代价想避免任何一种简化?假定文化模式的存在,意味著接受下列事实:我们在分析资料时就是在进行至少某种简化。不这么做,我们便无法进行比较,除非我们正在处理的是极端的极简主义或连续群体(seriality),这类艺术家(例如勒维[Sol LeWitt])的作法是,在维持其他一切事物相同的情况下,只改变单一变数。
我们可以将文化分析学定义为在不同尺度上对文化模式的量化研究。如此一来,我们便必须立刻把这项陈述加以质化。儘管我们想找出文化资料中的重複模式,但我们应该永远记住,它们只解释了文化产物的某些层面以及人们对它们的反应。
除非是另一种文化产物的完美複製,或是为了与他人相同而以机械式或演算法产出,否则每一种表情与互动都是独特的。在某些案例裡,此种独特性在分析中并不重要,但在其他例子则非如此。举例而言,我们从Instagram自拍照的资料集中自动选取出的脸部特徵,揭露了人们以这种媒介在我们分析的特定城市与时期当中再现自我的方式,以及这些方式之间耐人寻味的差异(图四[19])。但我们不厌其烦浏览Instagram、观看其中无数脸孔与身体的原因,在于它们都是独一无二的。让我们著迷的,并非重複的模式,而是独特的细节及其组合(图五)。
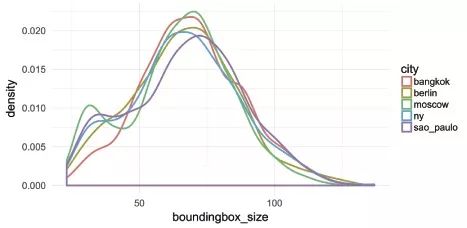
(图四):在五个城市所拍摄共3,200张Instagram自拍照中脸部大小的分布,检索日期:2013年12月。每个城市各有640张照片。,
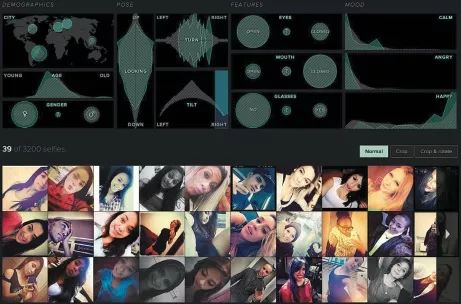
(图五):selfiecity.net的萤幕截图,显示出一组採用类似脸部角度拍摄的Instagram自拍照。此种脸部角度的相似性反而突显出人物脸部在其他面向上的差异。
文化分析学的最终目的,应是钜细靡遗地映射与理解全球由当代专业者和使用者所创造的文化产物,也就是聚焦于众多文化产物之间的差异,以及他们的共同特质。19与20世纪缺乏适当的科技来储存、组织与比较大型文化资料集,导致简约文化理论的盛行。时至今日,我们可以只用一部电脑来映射与视觉化数以千万计的物件之间的数千种差异。我们因而不再有任何藉口让自己仅关注文化产物或行为之间的共同性。我们更应加以归类,或是将它们视为一般类型的实例。鑑于当代文化生产与动态的规模,我们也许必须先提取模式,以便勾勒其概略模样,但最终,当我们只专注在个别物件之间的差异,这些模式便将逐渐没入背景,或甚至完全消解。对我而言,这是使用人工智慧方法来研究文化的终极许诺。
注释





