本文介绍了字节跳动豆包大模型团队提出的SuperClass预训练模型,该模型是一个超级简单且高效的预训练方法,无需额外的文本过滤或筛选,直接使用原始文本的分词作为多分类标签。实验结果表明,SuperClass在多种纯视觉任务和视觉语言多模态下游任务上表现出色,具有与CLIP相当或更优的Scalability。本文详细阐述了SuperClass的实现原理、技术亮点及实验结果,并讨论了其相较于CLIP的优势。
SuperClass是一个简单、高效、具有良好Scalability的预训练模型,通过舍弃文本编码器,直接使用原始文本的分词作为多分类标签,实现了对视觉模型的高效训练。
相较于CLIP,SuperClass在模型大小、数据集大小、纯视觉任务和视觉语言多模态下游任务上的表现均有所优势,同时无需文本编码器和构建大规模Batch Size,更加适合应用于大模型预训练场景。
实验结果表明,SuperClass在各种模型大小和数据集大小上都取得了不错的精度,在纯视觉任务和多模态下游任务上的表现均优于或相当于CLIP。
近日,字节跳动豆包大模型团队提出 SuperClass,一个超级简单且高效的预训练方法。该方法首次舍弃文本编码器,直接使用原始文本的分词作为多分类标签,无需额外的文本过滤或筛选,比 CLIP 具有更高的训练效率。
实验结果表明,SuperClass 在多种纯视觉任务和视觉语言多模态下游任务上表现出色,并且在模型大小和数据集大小方面具备与 CLIP 相同或更优的 Scalability 。本文将介绍 SuperClass 的实现原理、技术亮点及实验结果。
CLIP,可谓 AI 大模型中的“眼睛”。该模型通过将图像与文本对齐,实现了图像与语言之间的理解与关联。近些年来,CLIP 被广泛应用于视觉理解、图像问答、机器人/具身智能等多个领域,在 GitHub,该模型 Star 数量高达 25.9k。
但 CLIP 自身结构对计算量的高要求,限制其进一步应用与发展。
字节跳动豆包大模型视觉基础研究团队于近日公布最新成果
SuperClass
,该模型首次去掉了文本编码器,仅利用海量的图像-文本数据集预训练,无需文本编码器及构建大规模对比 Batch Size,就能得到强大甚至表现更好的视觉模型。
取代 CLIP 的对比学习方法,SuperClass 不仅成功解决计算负担重的问题,同时可获得效果可观的视觉模型。
实验结果表明,SuperClass 在各种纯视觉场景和视觉-语言多模态场景下均优于 CLIP,同时基于分类的方法,模型展现出与 CLIP 相当,甚至更优的 Scalability。

目前,论文成果和代码仓库已对外公开,并被 NeurIPS 2024 接收。
SuperClass: Classification Done Right for Vision-Language Pre-Training
论文链接:
https://arxiv.org/abs/2411.03313
代码链接:
https://github.com/x-cls/superclass

高计算量带来 CLIP 的限制
近年来,基于 Web-Scale 的图像-文本数据集的预训练方法已彻底改变计算机视觉领域,尤其 Contrastive Language Image Pretraining (CLIP) 及其系列模型获得了越来越多关注,并已成为大多数当前视觉语言模型(VLM)的默认选择。
CLIP 的广泛应用源自于三方面优势:首先,优越的视觉表征能力,大幅提升零样本视觉识别的精度和下游任务适配的泛化性。其次,CLIP 表现出不错的 Scalability,一定程度上,能持续受益于更大模型和更多数据。第三,强大的跨模态能力,本质上,CLIP 就是为连接文本与图像而设计的。
尽管 CLIP 已取得成功,但要达到更佳性能,模型在训练时就需要非常大的 Batch Size 用于对比学习,同时,还需要大量计算资源进行文本编码。对于计算量的高要求一定程度上限制了该技术应用与进一步发展。

首创超级简单的多分类方法,无编解码器
面向上述问题,豆包大模型团队在业内率先提出一种全新、超级简单的多分类方法 SuperClass。
无需文本编码器和解码器,也无需额外文本过滤和筛选,仅使用原始文本,团队实现了监督视觉模型的高效训练,同时具有良好的模型和数据 Scalability。
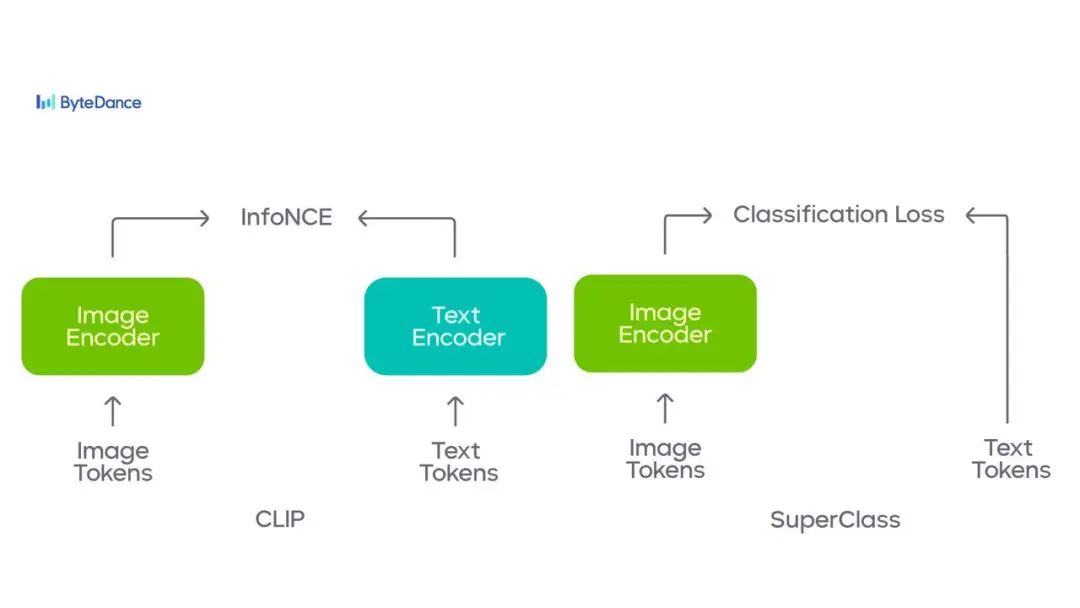
实现原理
我们希望建立一个基于图像分类的预训练方案,保持简单性、可扩展性和高效率,同时精度可以与 CLIP 相媲美。因此,我们采用 Vision Transformer (ViT) 作为视觉编码器的主干网络,后接全局平均池化层和一个线性层作为分类头。
在训练步骤中,我们的方法类似于典型监督多标签分类网络,输入一张图像,提取全局特征,并通过分类层获得逻辑向量
。分类标签从图像对应的文本中得到,分类损失由文本衍生的分类标签和预测向量共同构成。
文本映射成分类标签
与之前的基于分类方法不同,对于一个包含 N 对图像 I 和文本描述 T 的图像-文本数据集
,我们直接使用现有子词级别分词器(如 CLIP 或 Bert 中使用的分词器),词汇表大小为
,输入文本
并获得相应的子词 ID 集合
作为分类标签。
集合
中的标签满足
。分类标签
将被转换为
-hot 向量
,其中当
在集合
中时
,否则
。
与之前基于分类的预训练方法相比,我们的方法不需要任何预处理或手动阈值设置,同时,它也避免了之前方法可能遇到的词表溢出(Out-of-vocabulary)问题。
分类损失函数
业内已有大量研究探讨多标签分类损失函数。然而,值得注意的是,我们的目标是预训练视觉编码器,而不是真正专注于多标签分类准确率。因此,我们对几种多标签分类损失进行了消融实验,包括 Softmax Loss、BCE Loss、Soft Margin Loss、ASL 和 Two-way Loss。
令人惊讶的是,简单的 Softmax 损失产生了最佳预训练结果。这可能是因为当前多标签分类损失建立在标签精确且完整的假设基础上,努力优化正负类别之间的间隔。然而,图像-文本数据中存在固有噪声,且文本在完整描述图像内容方面的局限性,意味着图像中所有对象并不总在配对文本中被提及。
在多标签场景中,通过以概率方式描述标签来应用 Softmax 损失,其中
是归一化加权标签。

逆文档频率作为类别权重
在子词词汇表中,每个词都承载着不同程度的信息量,不同类别之间并非同等重要。此外,考虑到子词词典中包含许多语句常见词,这些词与视觉内容无关,并不能提供有效的监督信息。
因此,团队认为,携带大量信息的词在训练过程中应被赋予更大权重。我们使用
逆文档频率
(
Inverse Document Frequency
或 IDF )来衡量信息量,IDF 包含特定词的样本数量越少,该词区分不同样本的能力就越强。
我们使用类别(子词)的逆文档频率(IDF)统计作为分类标签的权重,为分类标签
分配不同的权重
:

其中,
是图像-文本对的总数,
是子词
的文档频率(df),也就是包含子词
的文本数量。为了更加便于使用,我们在训练过程中实现了在线 IDF 统计,无需在训练前离线统计。这使得 SuperClass 方法更加友好且便于移植。

SuperClass 不仅简单和高效,还能学习到更好的视觉表征
由于不需要文本编码器和构建巨大的相似性矩阵,SuperClass 可以节省大约 50% 的显存使用,加速 20% 以上。
为了更好度量预训练得到的视觉表征能力,我们固定住训练好的视觉模型的参数,将其应用到 Linear probing 、zero-shot 、10-shot 等分类任务,同时接入到 LLM 做视觉和语言多模态下游任务进行评测。
所有实验中,我们均采用和 CLIP 相同的模型和训练参数设置。
更好的视觉表征
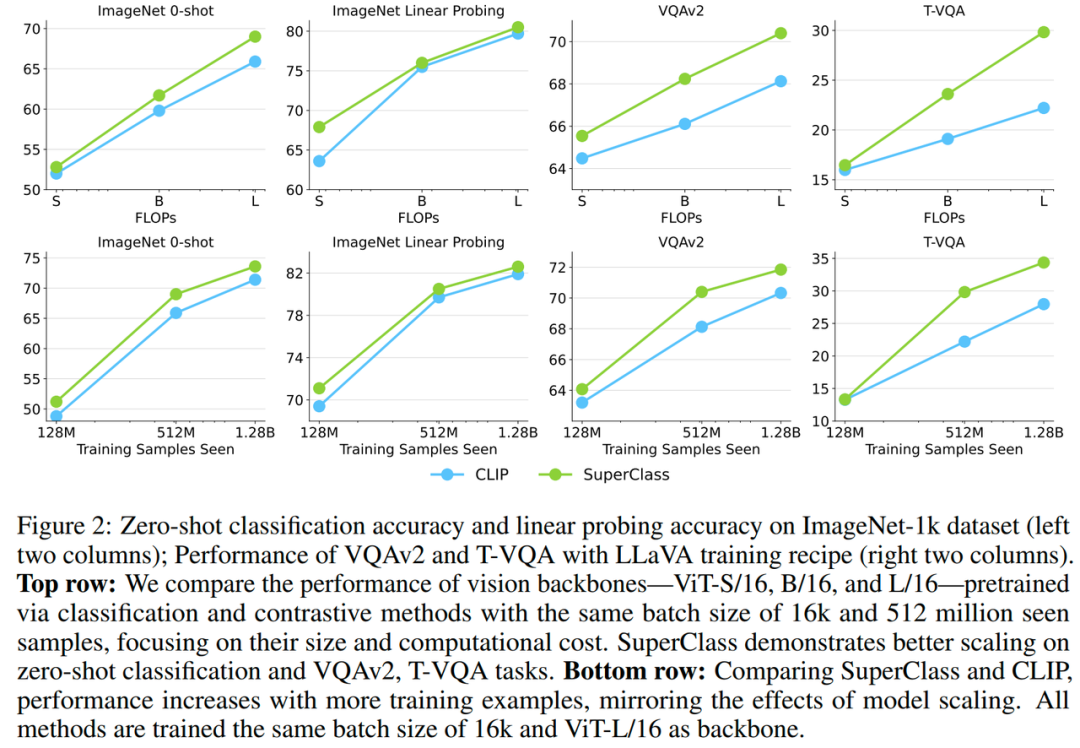
结果显示,SuperClass 在各种模型大小和数据规模都取得不错的精度。与其他无监督方法相比,SuperClass 由于依靠语义信息作为监督,训练数据多样,在各种图像分类数据集和不同分类任务上均取得更好精度。
与 CLIP 相比,SuperClass 在使用相同数据集的训练参数设置下,图像分类精度也基本优于 CLIP 模型,比如 ImageNet linear probing 分类,SuperClass 比 CLIP 高 1.1% (85.0 vs. 83.9) 。考虑到 SuperClass 无需文本编码器和构建大规模 Batch Size ,使其更加适合应用于大模型预训练场景。
更好的跨模态能力
CLIP 广泛应用的另一个场景是多模态理解,作为多模态大模型中的视觉编码器,展现了很好的跨模态能力。在预训练过程中,SuperClass 的特征也对齐到了文本空间,同样可应用于多模态理解任务中。
本文采用了 2 种大语言模型,按照 clipcap 中的设置,使用 GPT-2 作为 Decoder,在 COCO captions 上评估 image captioning 能力。根据表 3 的结果所示,SuperClass 取得了略优于 CLIP 的 CIDEr 结果。

另外按照 LLaVA 的设置,使用 7B 的 LLM 评估了更多的多模态下游任务,同样 SuperClass 也取得了更好的精度。
更多实验配置和测试细节请移步完整论文(
https://arxiv.org/abs/2411.03313
)。
更好的可扩展性 Scalability
团队对比了 SuperClass 和 CLIP 在不同的模型大小和不同的数据规模下的精度,包括纯视觉任务和多模态下游任务:
1. 在纯视觉任务和多模态下游任务上,SuperClass 和 CLIP 具有相似的
Scalability
;
2. 在 Text-VQA 任务上,SuperClass 明显取得了比 CLIP 更好的精度和
Scalability,团队推测,SuperClass 训练可能可以学习到更强的 OCR 能力。
展望未来,团队会继续推进图像文本预训练技术迭代,基于文本顺序信息,训练得到更强视觉模型,以便更好地服务于视觉和多模态相关的任务。点击阅读原文,前往豆包大模型团队官网,或点击下方卡片关注公众号,了解更多信息。
🔍
现在,在
「知乎」
也能找到我们了
进入知乎首页搜索
「PaperWeekly」
点击
「关注」
订阅我们的专栏吧






