本文是阿里巴巴的一篇论文介绍投稿。这篇论文被收录于2017国际知识发现与数据挖掘大会(KDD),主要在商品智能排序领域进行了研究。
这篇论文主要讲述,去年双11期间,淘宝搜索在有限计算资源情况下,如何拿到更好的排序结果、保证用户的搜索体验、以及点击、成交量和成交额等目标的完成。
实际的结果是,去年双11当天,淘宝搜索引擎的负载在最高峰也没有超过70%,CPU的使用率降低了约45%,搜索的平均延迟下降了约30%,同时带来的GMV提升了近1%。
以下是这篇论文的详细介绍。
《多层级联学习在大型电商排序系统的应用(Cascade Ranking for Operational E-commerce Search)》
作者:刘士琛,肖非,欧文武,司罗
该论文设计并实现了一种级联式电商搜索方式:它的主要思想是将一次排序分成递进的多个阶段,各阶段使用逐渐复杂的特征去得到逐渐准确的结果。在靠前阶段使用简单特征过滤显然不合要求的结果,在靠后阶段使用复杂特征辨别难以区分的结果。除此以外,算法结合电商场景的特殊性,严格限制了引擎的响应时间以及返回商品的数量,以保证用户的搜索体验。
离线实验和在线实验均验证了算法的正确性以及有效性,对比传统的方法能提升准确率的同时大幅提升了计算性能;在去年双11,在新增了大量准确又耗时的计算特征(包括强化学习和深度学习特征)的情况下,算法极大的保证了引擎的效率,使排序对引擎的压力下降40%,同时使排序效果有较大提升。
面临的问题
淘宝的搜索系统无疑是全球最大的电商搜索系统。“最大”这里包括商品量、用户量,包括引导的成交额、点击成交量,还包括引擎的访问次数、访问QPS…这样一个搜索引擎,所需要面对的访问压力也是巨大的,尤其在“双十一”等大促场景,压力更是平时的数倍。
另外一般搜索引擎的目标主要是引导点击,而在电商中,排序的结果更希望引导的是成交量和成交额。
因此我们的搜索系统、排序方案需要考虑多种实际问题。首先是在有限计算资源情况下,如何拿到更好的排序结果;其次是怎样保证用户的搜索体验,包括结果返回时间、返回商品量等;最后是怎么保证电商场景下的多目标,包括点击、成交量和成交额。
已有方法的不足
学术界和工业界都有大量learning to rank方面的研究,均期望能通过机器学习,为用户给出更优的排序结果。然而绝大部分相关工作都集中在如何提升排序的质量,却并不关系排序的效率,而太低效的排序方案在实际的工业在线应用中,往往是不可接受的。
淘宝搜索和其他类似应用主要采取的解决方案是使用一种“两轮排序方案”:在第一轮使用非常简单的特征去得到一个小的候选集;第二轮在小的集合上做复杂的排序。可是这种启发式的方案并不能保证性能与效果的取舍是最优的。基于以上考虑,我们需要一种全新的、工业可用的、能更合理平衡效率与性能的排序方案。
CLOSE排序算法,平衡性能与效率,保障用户体验
论文受图像中快速目标检测算法的启发,发现并不是引擎中的每个商品都需要全部特征参与计算、排序——一些基本特征能帮助过滤掉大多数商品;逐渐复杂的特征过滤逐渐难以区分好坏的商品;全部特征排序剩余商品。
基于这样的思想,论文提出了一种多轮级联排序方法Cascade model in a Large-scale Operational Ecommerce Search application(CLOES)。
CLOES主要采用了一种基于概率的cascade learning方法,将排序分为多轮计算;将排序效果和CPU的计算量作为优化目标,一起建立数学模型,同时优化。
除了考虑性能与效率,算法还考虑了用户的搜索体验,保证用户在输入任何一个query后都能在限制时间内得到足够的返回结果。最后CLOES还考虑了电商场景的特殊性,保障了多目标的平衡与可调整。
平衡性能与效率的排序(Query-Dependent Trade Off Between Effectiveness and Efficiency)
论文最重要的部分就是怎么样去平衡一个排序算法的性能和效率,那么我们主要使用的方法是cascade learning,即将一次排序拆分成多个递进阶段(stage),每个阶段选用逐渐复杂的特征去过滤一次商品集合。同时我们使用learning to rank设定,将排序问题转化为一个二分类问题,预估每个商品的点击率。
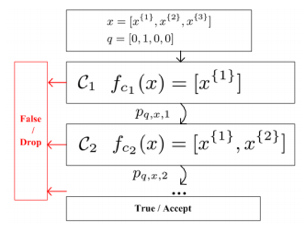
如图所示,我们记一个商品x(表示为一个k维向量)在Query q下,能通过第j个stage的概率为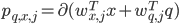 ,其中
,其中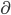 表示sigmoid函数。那么一个商品最终能被点击的概率为能通过所有stage的概率之积:
表示sigmoid函数。那么一个商品最终能被点击的概率为能通过所有stage的概率之积:
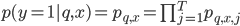
我们通过极大似然估计去拟合样本,使用负的log似然来表示损失函数,那么基础的损失函数可以表示为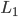 。关注的是排序的准确性:
。关注的是排序的准确性:
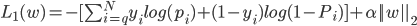
其中左边项表示似然函数,影响模型的准确度;右边项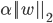 表示正则项,一方面是防止过拟合,另一方面能预防特征相关导致的ill-condition问题。
表示正则项,一方面是防止过拟合,另一方面能预防特征相关导致的ill-condition问题。
由于在实际的搜索排序中,我们除了效果,性能也是不得不关注的部分,因此我们需要将系统的性能性能消耗也加到目标中。我们可以求CPU的总消耗等于每个stage下的性能消耗之和: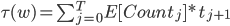 。其中
。其中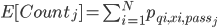 表示每个stage上需要计算的商品量的期望,
表示每个stage上需要计算的商品量的期望,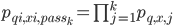 表示商品x能进入第j个stage的概率,
表示商品x能进入第j个stage的概率,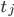 表示在第j个stage上的feature进行一次计算的总耗时。那么我们得到一个新的loss
表示在第j个stage上的feature进行一次计算的总耗时。那么我们得到一个新的loss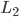 ,除了考虑排序的效果,兼顾了模型的计算量:
,除了考虑排序的效果,兼顾了模型的计算量:
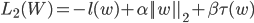
通过调整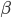 ,我们能调节系统的性能与效率。越大,系统负载越低,但排序结果也越差;越小,排序结果越好,但系统开销越大。
,我们能调节系统的性能与效率。越大,系统负载越低,但排序结果也越差;越小,排序结果越好,但系统开销越大。
用户体验保障(Multiple Factors of User Experience)
如果直接使用上述模型,确实可以直接降低引擎的负载,但是仍然存在2点用户体验上的问题:1是对于某些query(特别是hot query),可能计算latency仍然会非常高;2是某些query(一般是长尾query)下,返回给用户的结果特别少。那么为了解决这2个问题,我们进一步的增加了2个约束:单query下的latency不能超过100(只是举例,不一定是100)ms;返回给用户的结果数不能小于200。那么很自然的,我们会想到使用类似SVM的loss形式:
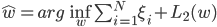
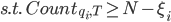
上述公式可以比较直观的理解为当query下的latency小于100ms(N的值)的时候,loss为0;大于100ms时,loss为(latency-100)的线性倍数;返回结果数类似。然而该函数是非凸、不可导的,并不利于问题的求解。因此为了求解的方便,我们使用了一个凸近似函数modified logistic loss去逼近SVM loss,可以证明,该loss和hinge loss是几乎一致的,当我们取一个较大的 的时候:
的时候:
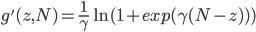
综上,我们考虑了用户的2种体验之后,最终的目标函数可以写成下面形式:
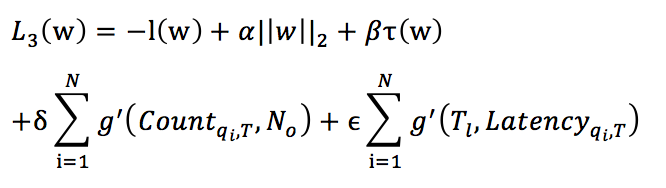
其中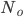 表示期望返回给用户的最少结果数(例如200),
表示期望返回给用户的最少结果数(例如200),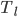 表示希望的最大latency(例如100ms)。通过最小化
表示希望的最大latency(例如100ms)。通过最小化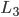 ,我们既能在有限的计算资源下得到更好的排序结果,又能兼顾用户的搜索体验。
,我们既能在有限的计算资源下得到更好的排序结果,又能兼顾用户的搜索体验。
商品场景下的多目标(Importance Factors of E-commerce Search)
电商搜索与网页搜索或者广告有较大区别:我们关注的不仅是点击 ,成交量、成交额等指标同样重要。然而如果我们将所有正样本(点击和成交)一样处理,由于点击样本量远大于成交样本,那么我们更像在学习一个CTR任务;这在我们想得到更高的成交额或GMV时是不合理的。因此我们为不同类型、不同价格的正样本设置了不同的权重。更具体的,我们会区分样本商品的log(价格)、点击和成交,于是在表示准确的似然项上,做了如下修正:

在上式中,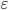 越大,成交样本的权重更高;
越大,成交样本的权重更高;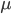 越大,价格因素的影响越大。权重的作用主要会体现在优化过程的梯度求解上。
越大,价格因素的影响越大。权重的作用主要会体现在优化过程的梯度求解上。
离线与在线验证
为了验证算法的有效性,我们随机采样了线上一天的日志做交叉验证,数据取自2016年10月底。我们主要考察的指标有2点:测试集上的AUC以及性能总消耗。对比的算法有1,使用全部特征做一次排序;2,使用简单特征做一次排序;3,线上使用的2-stage方法;4,CLOES算法,取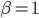 ;5,CLOES算法,取
;5,CLOES算法,取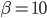 。
。
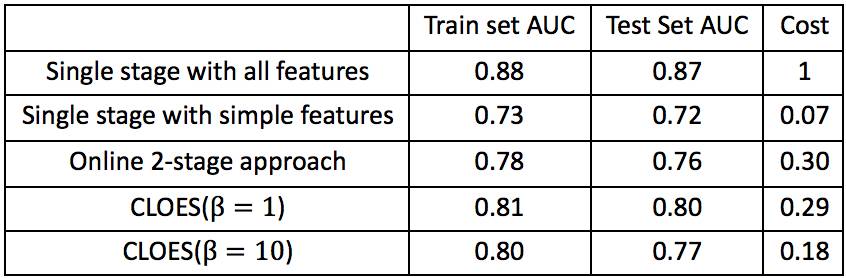
实验结果如下表。从表中我可以看到使用全部特征的准确率无疑是最高的,然后计算消耗也是最高的;线上使用的2-stage方法能显著的降低计算效率的问题,只有方法1的30%,但是AUC也降低到0.76。我们主要对比的是现在线上使用的方法3—2-stage approach,使用了CLOES,在几乎相同的计算消耗下,AUC能从0.76提升到0.80;在几乎相同的AUC下,计算消耗能从30%进一步下降到18%。
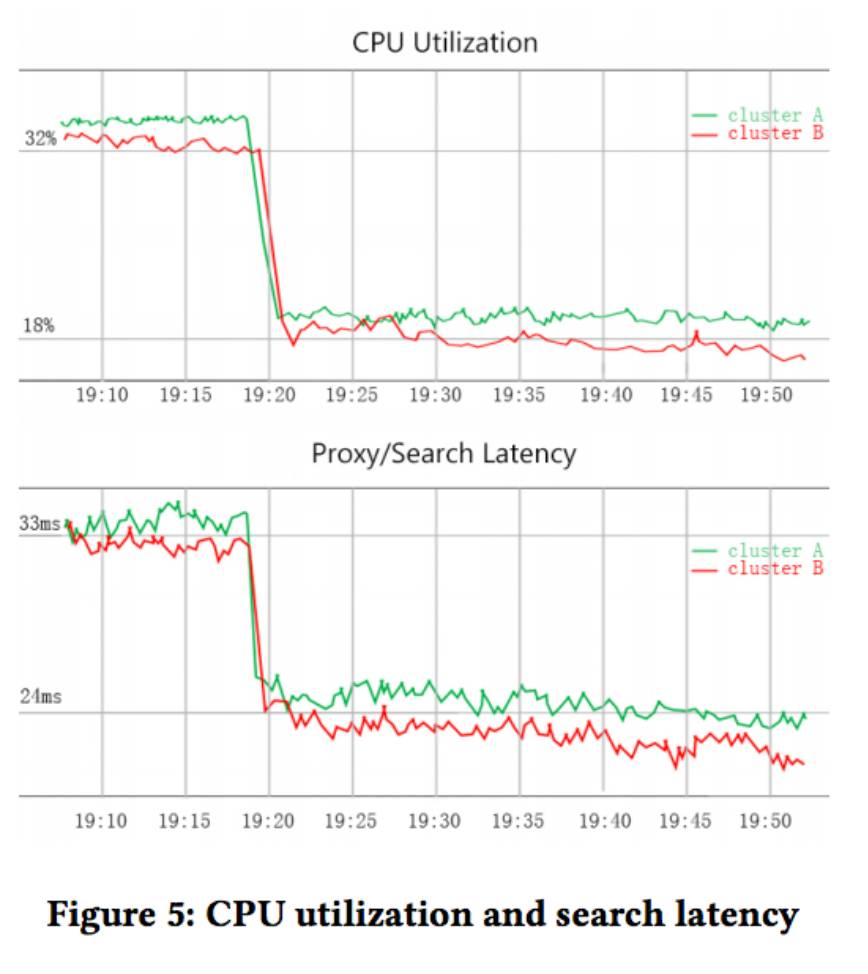
在离线验证了算法效果后,我们在双11前夕对算法进行了上线,以期望降低引擎的计算压力。上线期间的引擎CPU使用率以及平均搜索latency变化如下图:可以看到CPU使用率从32%下降到18%;而平均的搜索latency从33ms下降到24ms,图中有2条曲线分别表示引擎的2个集群。
需要注意的是,在引擎压力大量下降的情况下,线上的排序指标,包括CTR和GMV是略上升的。
受益于CLOES,在双11当天,引擎的负载在最高峰也没有超过70%,CPU的使用率降低了约45%,搜索的平均延迟下降了约30%,同时CLOES本身带来的GMV提升了近1%。考虑到其他因为性能改善而能上线的特征(包括实时特征和RNN特征等),排序的CTR提升有10%-20%,同时成交量、GMV等指标也有大幅提升(指标对比基于标准A/B Test)。
其他的实验结果以及算法细节请见原文。
总结
搜索对于电商来说是最大的流量入口,搜索排序的质量对用户的体验、对商家的收入、对平台的效率都会起到至关重要的作用。未来搜索会继续以用户的搜索体验为主要目标,为用提供能更优质、更能满足用户个性需求的排序结果。
从技术上,多种机器学习技术都会与搜索排序相关,例如:考虑到用户的长期体验,我们需要强化学习技术;考虑数据的分布不一致等问题,需要counterfactual learning技术;考虑更好的个性化体验,需要representation learning的相关技术;考虑更具交互性的搜索,我们需要自然语言处理,知识图谱等方面技术……淘宝搜索会持续的优化用户的购物体验,同时希望贡献更多优秀的算法、解决方面给工业应用及学术研究。
论文下载
https://arxiv.org/pdf/1706.02093.pdf
量子位AI社群7群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot2入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot2,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。







