前两天,我给我学习社群的同学们出了一道心算题:
结果怎么样?有一半的同学没算对。他们普遍抱怨,过程中要记住的数字太多,脑子不够用了。我内心演算了一下,计算过程还蛮复杂的:
7x2 = 14
识别个位:4
识别十位:1
将4存储进结果的“个位”
将数字1存储进临时的“进位”
9x2 = 18
识别个位:8
识别十位:1
提取存储于“进位”中的数字1
8+1 = 9
将9存储进结果的“十位”
清空“进位”中的数字
将数字1存储进临时的“进位”
……
这么列下去的话,估计要超过50步。把过程画出来,会比较容易看清楚。
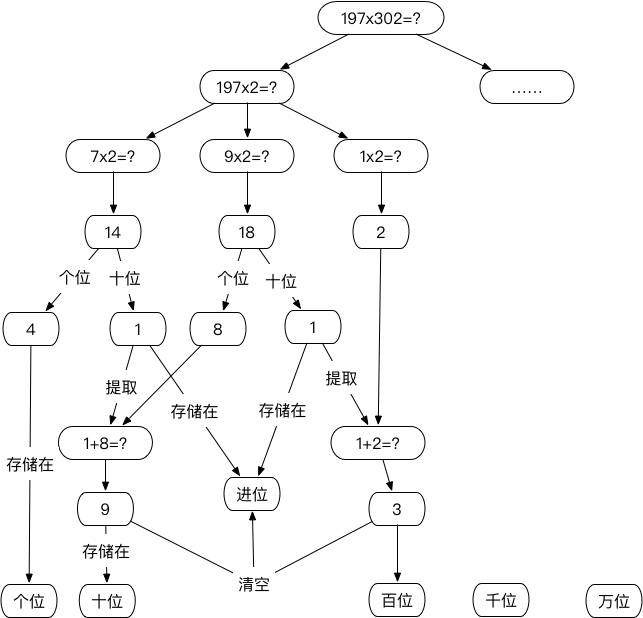
可以看到,在任何一个步骤,我们都需要记住几个数字:
-
当前相乘的两个数字
-
它们相乘结果的个位和十位
-
需要进位的数字
-
临时结果的个位、十位、百位……
也就是说,当我们的结果是一个五位数的时候,我们需要同时记住10个数字,并且还要有余力进行计算。难怪这么多同学算错了,他们的感受是:
整个计算过程要完全在大脑中进行心理模拟,没有任何辅助的技巧,很难记住中间过程,也很难不出错。

不过,也有同学算对的了。他们并不是记忆力特别好,而是用了一些巧妙的方法:
换一种表达方式(200-3)+(2+300),然后慢慢算。
即使这样也不容易,有几位同学就用了同样的方法,但结果依然悲催:
(200-3)×(300+2)然后……算出来5949……脑子里把这等式拆开的时候很乱,然后把200×300算成6000了……低级错误。
又如:
197x(300+2)=59100+394=(200-3)x302=60400-906=减错了🤣
这个小练习引导我们思考,我们的大脑是如何工作的?从上面计算的过程来看,它跟计算机的工作过程很类似:接受输入信息,把信息存储在内存或硬盘中,然后对信息进行加法、乘法、清零、移动等处理。
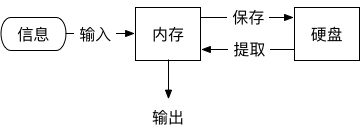
于是,科学家们参考这个过程,提出了人类的
信息加工系统模型
。
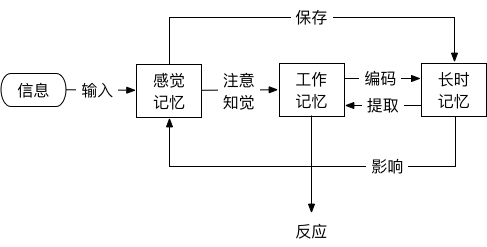
这个模型包含三个主要部分:
感觉记忆、工作记忆和长时记忆
。它们各有怎么样特别的功能和特征?让我们继续用以计算机做类比:
一、感觉记忆
感觉记忆对输入信息进行初步处理,让你知道进入的信息“是什么”,并把结果传输到工作记忆中,这个过程相当于把键盘的输入转换成数字信号。
当我们感受到信息后,就开始注意并知觉信息。注意力是有选择性的。例如,当我们听到手机“叮咚”的提示音后,就会注意并意识到微信的信息进来了,而咖啡馆的背景音乐即使放了一整天也很难引起我们的注意。
注意力也是一种有限资源
,如果养成了一听到提示音就看手机的习惯,我们恐怕就很难再专注地学习和工作了。
二、工作记忆
工作记忆相当于内存和CPU
,负责对信息进行各种处理。当信息通过注意和觉知进入工作记忆后,我们开始对信息进行分类、比较、计算、分析等等的认知加工。工作记忆是我们加工信息的工作台,新信息在这里与长时记忆中的已有信息进行整合,成为长时记忆的一部分。但工作记忆只是一张很小的工作台,它的
容量非常有限,只能存储5-9条信息,而能同时加工的信息更少,只有2-3条。
另外,信息在这张工作台上保持的时间也不长,只有15-20秒,要想延长,就要在内心不断复述这些信息。
心算为什么这么容易出错?因为你需要动用几乎所有的工作记忆存储单元,并且需要不断在内心复述临时计算结果,这两件事耗尽了你几乎所有的认知资源。所以算错的同学们不必伤心,这跟智力无关。
三、长时记忆
长时记忆相当于硬盘
,负责存储信息。经过了良好处理的信息,会存储到长时记忆当中。长时记忆的容量几乎是无限的,因此,它的瓶颈不在存储,而在提取。
你有没有这样的经历:当回忆某件事时,你却偏偏想不起来某个经历过的细节?这种状态,就是提取失败。提取失败说明信息在你的长时记忆中并没有得到有效的组织,许多记忆信息甚至处于“孤岛”状态,难以被激活(忆起)。
理解了信息加工的过程,特别是工作记忆和长时记忆的特征后,我们就可以知道:为什么脑子不够用?通常来说,这主要有两个原因:
-
受工作记忆加工容量和保持时间的限制,无法处理大量信息;
-
信息没有以良好的结构存储进长时记忆,导致无法长期记住和灵活提取。
怎么办?两个问题,逐个击破。
有几个方法可以克服或缓解工作记忆的局限:
一、组块(chunking)
请尝试记住这些字母:
现在尝试这个:
当零散信息被组合成若干个有意义的组块时,我们就能记住更多信息。
但是,组块跟个人是否有足够的背景知识有关。如果你没听说过FBI和CIA,组块就不成为组块,它还是三个随机字母的组合。
再做一个练习:请尽量记住下面这排汉字,可以不按顺序记忆。这个练习不限时间,你爱看多久看多久,完成后请继续阅读。
二、自动化(automaticity)
不需要意识控制就能运用的技能,叫做自动化的基本技能。技能的自动化是一个过程,一个好例子就是学开车。在一开始,新手司机会被大量的信息淹没:交通标志、行人和其它车辆状态、自身手、脚和眼的动作协调等等。但是,当学会开车之后,这一切都退隐幕后,不会对司机造成干扰,他甚至可以一边开车一边听音乐,同时还和朋友聊天。
因此,对于学习者来说,
应该尽量让常用的、低阶的技能实现自动化。
当识字达到了自动化水平,你就能腾出更多的工作记忆空间用在理解文章内容上。当理解达到了自动化水平,你就能更多地进行评价、比较、反思等高阶思维。
三、双加工(dual processing)
科学家们发现,不同类型的信息在工作记忆中有不同的处理模块,已知的有语音环和视空间模板。语音环对言语和声音(包括默念的声音)进行处理,例如本文一开始的心算练习中,像7x2=14这样的计算是放在语音环处理的。视空间模板是操作视觉信息的地方,试做一下这个练习:
大多数人都会在脑海中创造一个“d”,然后旋转它。这就是视空间模板的操作。
有趣的是,语音环和视空间模板不会互相干扰——你可以同时使用它们。这给了我们一个提升信息处理能力的机会。
例如,在学习时,先看一组照片或一段视频(视觉信息),然后和同学讨论(语音信息),又例如,在读书(语音信息)的同时做视觉笔记(视觉信息)。在《学习的原理》系列文章中,每一篇文章我都运用了大量的图表,这就是把语音信息和视觉信息进行结合的例子。










