GPU 成为在构建深度学习系统时必不可少的需要关注的方向,但是诸如如何选择一款 GPU 来搭建深度学习平台,如何升级自己的 GPU 之类的问题一直困扰着开发者。现在,这些问题都将由来自英伟达的深度学习专家为你解答。
编辑|陈思
注:本内容整理自 2017 年 6 月 26 日 InfoQ 英伟达在线直播课堂
GPU 成为每一家企业在构建深度学习系统时必不可少的需要关注的方向,与此同时英伟达每一年在推出新的 GPU 架构和依托于此的新的产品,其最推先推出的 Volta 架构,比起当前 Pascal 的性能提升了 5 倍,优于两年前推出的 Maxwell 架构 15 倍,远远超过摩尔定理的预测,在此背景下许多开发者也充满了各种疑问:例如如何搭建自己的深度学习平台,要不要升级自己的 GPU,深度学习系统,该如何选择和适合自己的 GPU 与 SDK,哪些方法或技巧能够帮助自己进行更好的升级?
英伟达机器学习解决方案架构师路川,从两个方面进行了介绍:
-
GPU 的硬件方面
-
GPU 的软件和开发平台方面
wifi 用户和流量土豪请看课程视频:
不方便看视频的同学可以先看文字版课程内容精炼,有 wifi 之后再去看视频,学习效果会更好哟~
从 06 年开始,就有人拿 GPU 做计算使用,从 06 年到 12 年,大部分的 GPU 的应用场景都是在传统的 HPC 领域去应用的,比如用作动力学,还有计算物理、计算化学等方面。
2012 年开始,就有人采用 GPU 来去构建深度神经网络,用 GPU 来加速深度神经网络计算,使用 GPU 来加速,在图像分类上面取得了非常好的成果。从 2012 年开始 GPU 在人工智能领域的开始应用的很广,2012 年到 2016 年各个互联网公司,各个行业都在应用 GPU。应用 AI 的技术去服务于客户的公司是越来越多,应用也是越来越多。

目前主流的 AI 研究里,用的主流的或者是性价比最高的 GPU 平台是 Pascal 架构的平台。Pascal 架构是目前主要针对于深度学习,针对于 GPU 计算的一个平台,它主要有以下 5 个特征:
-
Pascal 架构支持 GPU 计算,让 GPU 计算更加高效快速;
-
Pascal 的架构设计可以更好的让 GPU 充分发挥它的性能;
-
Pascal 采用 16 纳米的工艺,使它的 Memory 容量会更高、更快;
-
Pascal 架构开始采用的新的技术,取代了原来 PCIe 的技术,GPU 跟 GPU 之间的数据交换是通过 NVlink 相连,这样可以快速的达到 GPU 虚拟交换的目的;
-
针对于深度学习的一些 SDK 库,在 Pascal 下会针对架构做很多的优化;另外就是 GDSY,针对于深度学习的领域,英伟达公司推出了一个硬件加软件整体的智能解决方案,GDSY,它内部采用了最新的 Pascal 架构的 GPU。
英伟达公司内部也是对各个深度学习的 framework 做了一些优化,整合在 GPU 内部,这样客户可以不用关心底下是怎么去实现的,只用 GDSY 作为一个工具来去做深度学习训练就 OK 了。之后通过 GDSY 可以构建一个集群,来做一些深度学习分布式应用之类的计算任务,最后就是这三年内 GPU 的计算量增加到 60 倍,针对于 AI 技术,GPU 带来了非常大的计算性能的提升。
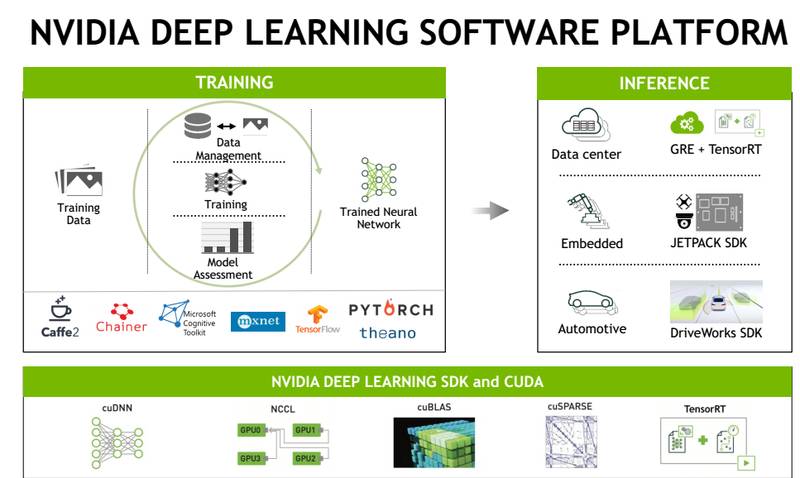
在深度学习里面用的比较多的是 SDK,像 cuDNN 网络,都可以去构建深度学习的网络。另外,就是 NCCL,指的是快速的去加速 CPU 跟 GPU 之间的数据交换,通过优化来提升 GPU 之间交换性能的一个 SDK 工具,还有 cuBLAS 函数,线性库,跟其他的一些 Blas 库是一样的,都是基于 CUDA 平台,基于 GPU 的库;还有 cuSPARSE 库、TensorRT,可以做一些线上的优化;通过调用 cuDNN 等等可以构建一个训练平台,用来加速训练,基于 Caffe、TensorFlow,训练完成以后,再布到线上去,在云端,或者嵌入式设备端,通过进一步的优化,可以快速的给客户去提供 AI 线上的 inference 服务。
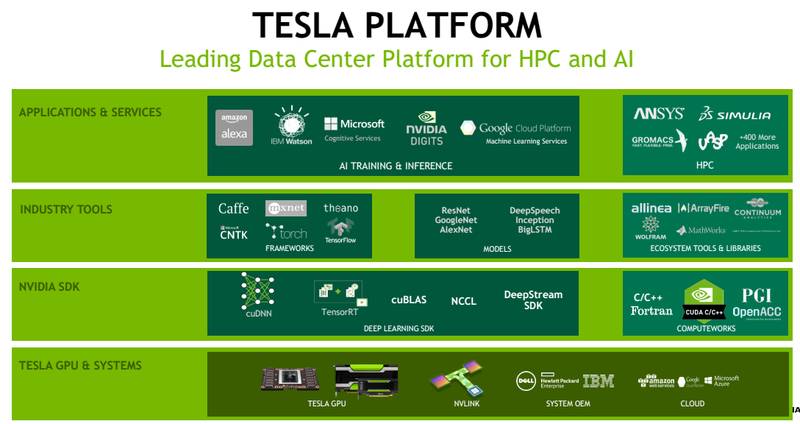
英伟达有很多的 SDK 供大家使用,SDK 对于客户来说是非常重要的一个工具。举个小例子:一些视频处理的客户,在视频处理的过程中,需要用到视频的编解码,同时要用到深度学习的这些工具,来加速相关的一些视频分析。编解码的方案有非常多种,但是经过对比,客户采用了英伟达的 Video SDK 里面的硬编程解码方式,效率会更高。如果要更高效的使用 GPU,当然是利用现有的英伟达 SDK 做加速。
在做一些 inference 应用场景下,可能要用到 CUDA 平台,英伟达提供了基于 GPU 的编程平台,供大家使用、编写自己的 GPU 应用程序,整个应用程序的计算部分占的很少,但是计算时间可能占了程序的 95%,只需要把这部分放到 GPU 端去处理,这样整个编程模式,蓝颜色的交给 CPU 去处理,到了绿颜色部分拷贝到 GPU 端,通过 GPU 来去做加速,加速完成,把相应的结果再拷贝到 CPU 端做处理。如果说你有一些算例,适合于刚才所说的计算模式,又想放到 GPU 上来去做,可以通过 CUDA 平台来去实现,如果没有现有的 SDK 的话,这种实现方式是个很高效的方式;如果是说你有一些像现有的这种 SDK,还是用 SDK 会更加方便一些。
训练端有一部分虚拟集,丢给一个 GPU 的集群去做训练,通过大量的虚拟集不断的迭代,让深度神经网络达到认知的职能,这是训练端的任务。
训练端有一些特性,比如说在训练的过程中,可以设置一个很大的一个 branch,一次可以丢给 GPU 很多的图片,或者是云的虚拟机,充分的把 GPU 内存占领;训练的任务可能是并行式的任务,每个进程之间会有一些频繁的虚拟交换,尽可能的把任务压缩在一个结点内部,或者说把通讯这种结点之间,或者 CPU 之间的通讯要尽可能的压缩在一个 GPU 内部来去做。如果是说任务非常大,我们可以采用 GPU 的集群方式来做,GPU 集群也需要一个高速的网络带宽,高速的链路来加速结点之间的数据交换。所以说在训练端,总体的任务比较繁重,同时算模式也比较密集。
训练好的模型,或者深度神经网络,可以传输到虚拟中心或者云端,或者到一些刚提到的智能的嵌入式设备上去做智能的设备识别,这部分叫做 inference,就是提供一些 AI 的服务,比如说提供一些图片分类的服务,客户上传一张图片,通过这个 AI 的服务,经过检验的处理,就可以去识别到这张图片的种类,在这样的应用场景下,我们要考虑到几个问题:第一要实时的反映客户的请求,要保证它的延迟;另外可以打包一个这个 branch,把很多的虚拟丢给 GPU 去做处理,在很多这种场景下需要保证客户的延迟,一般就是把一两张图片,或者是 16 张图片丢给 GPU 去处理,快速的给客户一个结果,这种场景相对来说是比较小的,在这种场景下,需要一个相对于训练端来说更小的 GPU 来去做这种 inference 计算模式,这样才能更好的去提线上集成的效率。
我们之所以选择 GPU 是因为它相比较于其他的计算平台有很强的优势。看 CPU 跟 GPU 的一个对比:深度学习应用方面,GPU 跟 CPU 无论在预算花费上、结点的数量上、功耗上,最关键的是在性能上面都有很强的优势,所以说客户选择 GPU 平台对客户带来的价值,是显而易见的,既能降低成本,又能提升效率,而且在目前,在一些大的数据中心内部,都可以看到 GPU 的存在,像亚马逊、谷歌,国内的阿里云、百度等等。一些互联网公司在虚拟中心内部都有 GPU 的集群,来提供训练跟线上的 inference 的服务。
再往上层就是应用的 SDK,如果想把 GPU 的硬件用的更好,SDK 肯定是非常重要的,SDK 都是由英伟达方面来提供。经过了性能优化,客户不用再关心底层的 GPU 算法的实现方式。
英伟达可以提供这种基于 GPU 的一整套的生态环境,这种平台可以帮助客户快速的去使用 GPU 的计算性能,从而加速深度学习的应用。
要挑选一款 GPU,首先应该了解 GPU 大概的性能,或者是说它的特点。目前主流的 GPU 架构是 Pascal,它也是目前在市场上最新的 GPU 架构。Pascal 架构的特点主要是针对深度学习,或者是针对 GPU 计算来使用。在 4 年的时间里,它有的性能有巨大的提高。
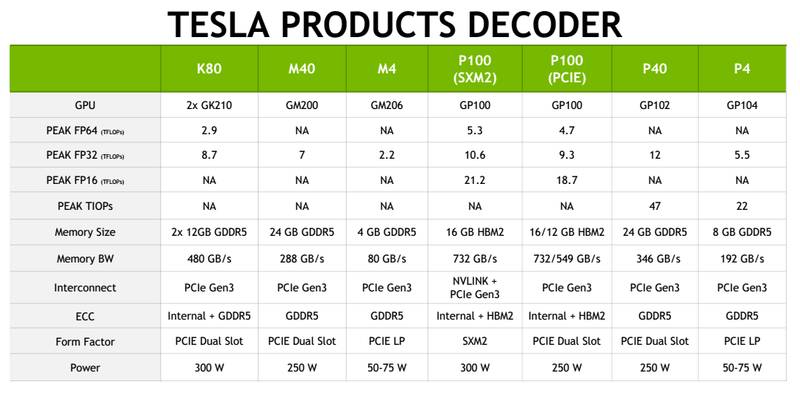
图为英伟达目前主要的 GPU 平台
选择 GPU 需要考虑到几个因素:
计算性能
计算性能又分为双精度计算性能和单精度的计算性能。双精度的是 FP64,单精度是 FP32,还有半精度的 FP16。这个主要是一个 Training 平台,主要会用到 FP32,跟 FP16。FP64 主要是在 HPC 的领域里用的比较多,如果精度不够,计算也许会出现一些状况。深度学习使用 FP32 或者 FP16 就已足够。
如果要做深度学习的训练,最主要关心的就是计算性能。P100,P40 有很大的性能优势,因为 K80 由两个 GPU 的芯片组成,它的单精度计算性能是两个芯片相交的一个结果,但是在做 GPU 计算过程中,两个芯片相当于使用两个 GPU,就势必会涉及到数据交换。
Memory(内存)
因为 Memory 如果很大的话,Bas 也相对要大一些,这样可以充分的去使用 GPU 的计算性能,减少 GPU 跟 CPU 之间的 I/O,可以优化 AI 的应用程序,所以 Memory 对也是非常重要的。
Memory 的带宽
计算性能可以非常快,但是如果 GPU 内部的 Memory 带宽不够的话会成为运行的一个瓶颈点。
CPU 与 GPU 的连接方式
PCIe,或者是 NVLink,现在 CPU 跟 GPU,如果 X86 的 GPU,大部分最主要还是基于 PCIe 来去连接 GPU 的,但是 GPU 跟 GPU 之间,可以通过 NVLink 进行快速的数据交换。
功耗
因为如果搭建了一个很大的计算平台,功耗对于机房环境的设置也是非常重要的点。现在做深度学习很多人希望在一个迭代内部,GPU 的数量越多越好。GPU 是一个局部发展量非常大的平台,所以说它的功耗对整个机房的功耗要求也是非常高的。要去综合考虑这几方面的因素来选择 GPU 平台。

视频最后的 Q&A 环节我们也做了文字版,方便有需要同学们查看~
1.GPU、CPU、TPU 三者之间的区别
CPU 主要做一些通用计算的应用。而 GPU 最早做计算的过程中,就是通用计算的 GPU 平台,我们想把 GPU 也像 CPU 一样做通用计算的平台,但是 GPU 它受限于架构和它的并行的方式,并不是所有的 CPU 的应用都适合于 GPU 做。在实际的应用过程中是 CPU 跟 GPU 搭配去做的,我们把适合 CPU 端的放在 CPU 端去做,而适合 GPU 做的复杂指令计算给 GPU 去做。
关于 TPU,是谷歌专门针对于他们的计算模式,或者是 AI 的模式设计的架构,然后专门去做这样的应用,相当于是一个专用的芯片。
现在也有很多的加速计算卡,之所以说 GPU 它的应用非常广,或者是说这么受大家欢迎,不仅仅因为 GPU 它有很大的计算性能,同时跟 GPU 构建的整个生态是有很强的关系,从 2006 年开始,我们就开始构建基于 GPU 的 CUDA 平台,包括现在基于深度学习,我们不仅仅提供了硬件,还提供了一整套的 SDK 库,供大家使用,这样可以让客户更加方便的去使用到 GPU 开发去做加速。
2. 是不是目前的显卡都能做深度学习呢?
A:现在的 GPU 它分为多种用途,比如说渲染、嵌入式等等。英伟达的 GPU 都是带有 CUDA 核心的,所以这些都可以去做,可以去跑 CUDA 的应用计算。但是在做深度学习的过程中,我们不仅仅要关注于这种 CUDA 核,同时也要去关注其他的功能:比如说 GPU 的 Memory,或者 GPU 卡之间的数据交换。所以现在所有的卡都可以跑 CUDA,而且所有的卡都可以去运行深度学习的训练,这个是没有问题的,如果运行的好的话,肯定是要选择更专业做深度学习训练的显卡,或者是专业做计算的显卡使用。
3. 有人问到过这样的问题:当这最新型号的 GPU 投放到市场之后,上一代,甚至更早一代会不会被过早的淘汰掉,现在再用之前的型号,会不会影响到自己进行深度学习训练?
A:因为现在市场上,不同架构的 GPU 卡同时存在,同时它的使用场景不同。用户既然原来购买了 GPU 显卡,也可以继续去用,因为我们去构建这种深度学习平台,可以通过调度的方式,把不同架构的 GPU 卡去充分的利用起来,并不是说新的 GPU 卡到了以后,原来的卡就不会去用了。构建不同的平台,或者不同的应用场景使用,可以充分发挥到 GPU 卡的优势。
4.GPU 在 Docker 下的使用状况?
A:很多的这种公司也基于 Docker 来去构建他们的平台,GPU 也是支持 Docker 的,而且在 GitHub 英伟达的站点上可以看到,我们有一个 NVIDIA Docker,这个是基于原来的 Docker 上,后来我们基于 GPU 做了很多的优化,这样让 GPU 对 Docker 会支持的更好,而且现在我所支持的客户里面有很大一部分人都是采用 NVIDIA Docker 来管理与使用 GPU 的。
5.Tesla P4 上有一个 Incoding 加速器,同时可以处理多少视频流?
A:因为做视频编码要有很多条件,比如说分辨率、码流,包括压缩的质量,差别都是比较大的。在 P4 上是有两个 Incoding,它是一个做这种视频编解码性价比非常高的一个产品。关于同时处理多少路视频,因为它的涉及的场景是比较多的,我们跟 CPU 做过对比,大概是 CPU 的 7 倍,所以说它相比一些 CPU 平台它是非常好的加速平台。
6.cuDNN 是简单升级软件就可以得到这么高的加速吗?
A:因为 cuDNN 要提升原有程序的性能,同时要对新的架构做支撑,另外一点,需要去支撑更多软件层的加速,综合这三个层面,软件加硬件,它会有一个比较高的性能提升。如果是简简单单的升级一个 cuDNN,知识对原有的层也会有加速,但是效果要根据具体的情况来去定。
7. 非公版的显卡 SDK 支持会不同吗?









