数据挖掘入门与实战 公众号: datadw
Twitter是一个流行的社交网络,这里有大量的数据等着我们分析。Twitter R包是对twitter数据进行文本挖掘的好工具。 本文是关于如何使用Twitter R包获取twitter数据并将其导入R,然后对它进行一些有趣的数据分析。
第一步是注册一个你的应用程序。
为了能够访问Twitter数据编程,我们需要创建一个与Twitter的API交互的应用程序。
注册后你将收到一个密钥和密码:
获取密钥和密码后便可以在R里面授权我们的应用程序以代表我们访问Twitter:

根据不同的搜索词,我们可以在几分钟之内收集到成千上万的tweet。 这里我们测试一个关键词littlecaesars的twitter结果:
抓取最新的1000条相关twitter
由于默认的抓取结果是json格式,因此使用twlisttodf函数将其转换成数据框
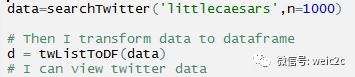
然后我们做一些简单的文本清理

从得到的数据里,我们可以看到有twitter发表时间,内容,经纬度等信息
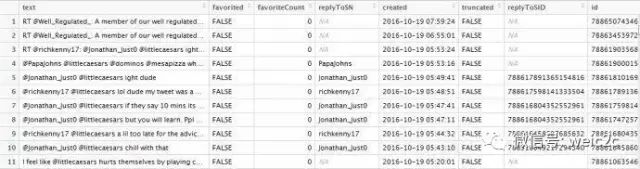
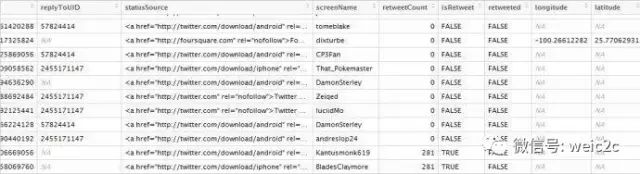
在清理数据之后,我们对twitter内容进行分词,以便进行数据可视化

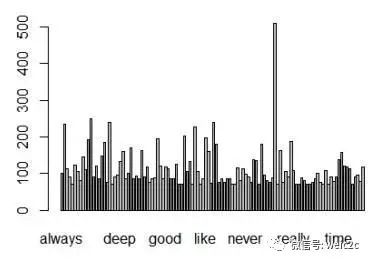
分词之后可以得到相关twitter的高频词汇,然后将其可视化

除此之外,还可以结合数据中的时间戳数据和地理数据进行可视化分析
推特和FB其实也是科研讨论的重镇。但是要怎么来分析推特上都讨论啥呢?光用Mendeley的话,只能有只言片语,这次又要带你打开新世界的大门了。
首先推荐用一款推特分析工具网站,叫做推特分析家,功能是实时分析推特上的动态。这是一款基于R语言Shiny的网页,由于这个是德国人做的,所以,会分析德语和英语两种语言。
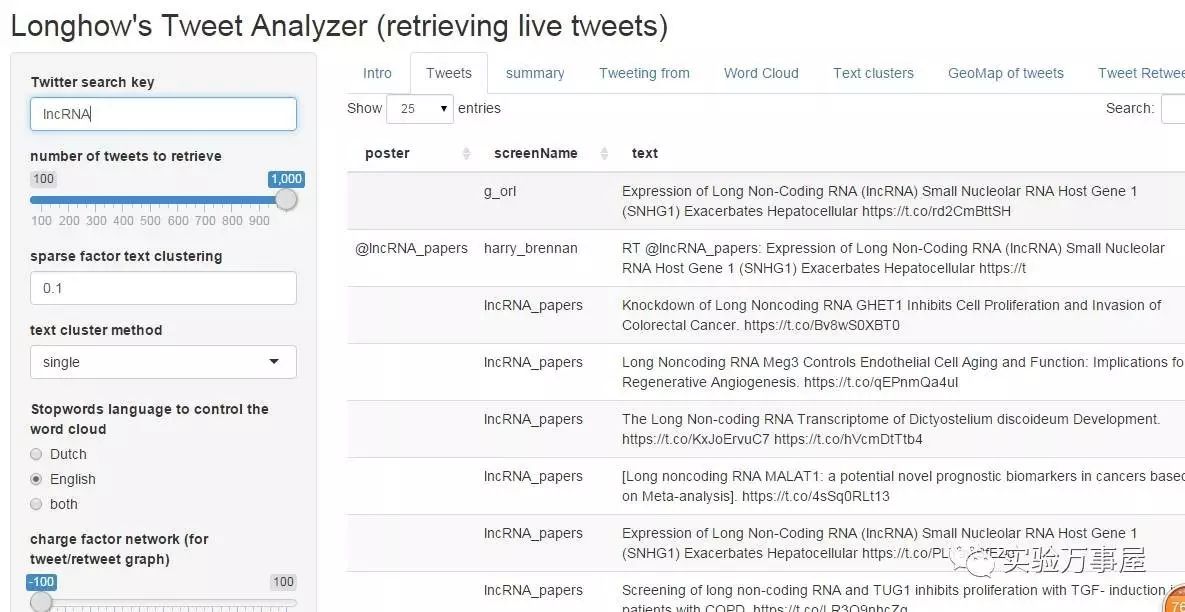
所用到的数据分析的资源,其实就是推特上的人家的东西。会对这些文字,进行文本挖掘,然后来分析你要的东西。比如,我分析一下LncRNA哈。
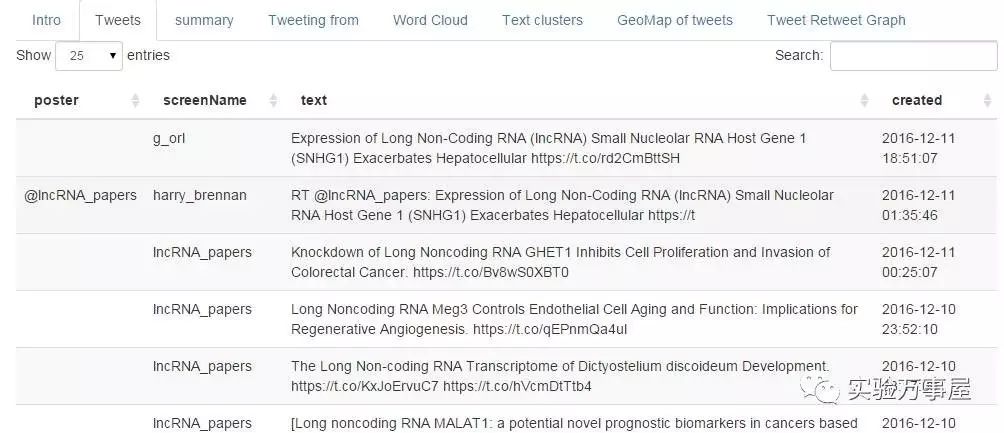
左侧的是文本数据的来源,可以发现,这最近的推特还是前几天刚发的。也就是说这个网站分析的数据都是实时数据。
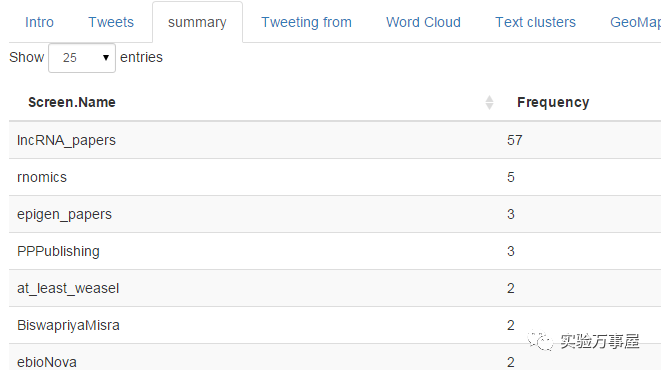
那这些推特具体讲的内容有些啥呢?主要是来自于LncRNA的论文和一些杂志的推送。反正推特就好比国外科研狗的票圈,转一下杂志上的牛逼文章的话,可能会显得更上等次,也是在跟老板说:看我很勤奋,有在看文献哦!
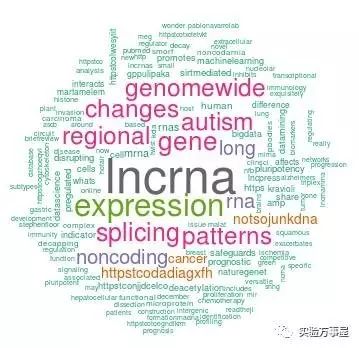
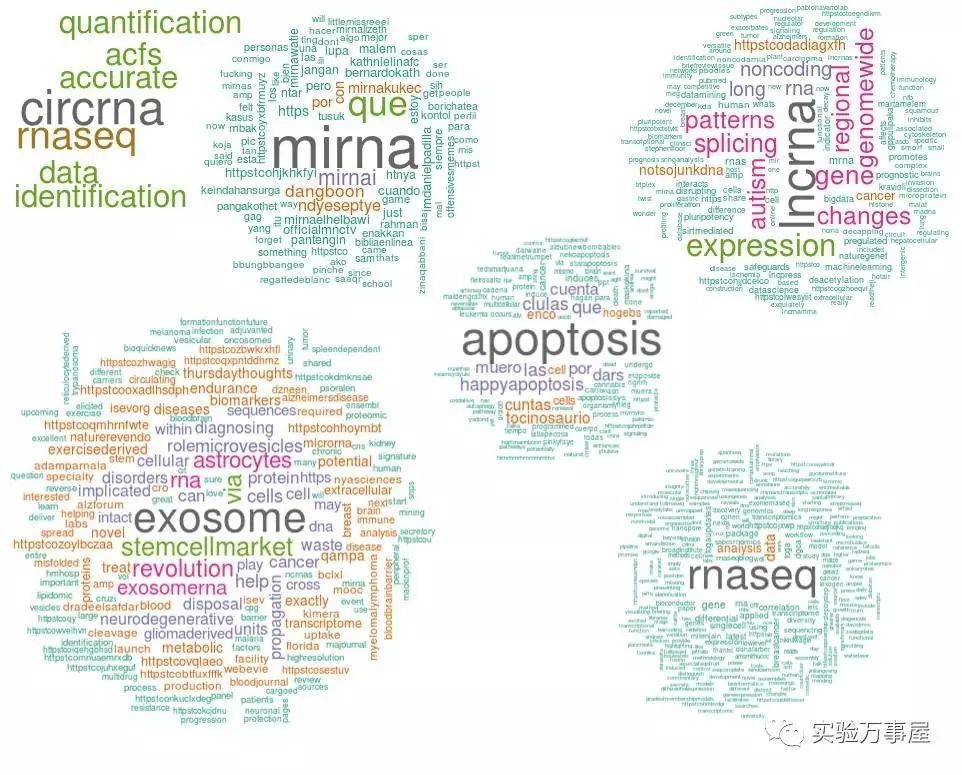
在WordCloud里,就会显示在推特上,讨论的最多的和lncRNA有关的词汇。比如:表达,变化,剪切,模式,肿瘤等等,说实话是没有什么特别大的用处哈。
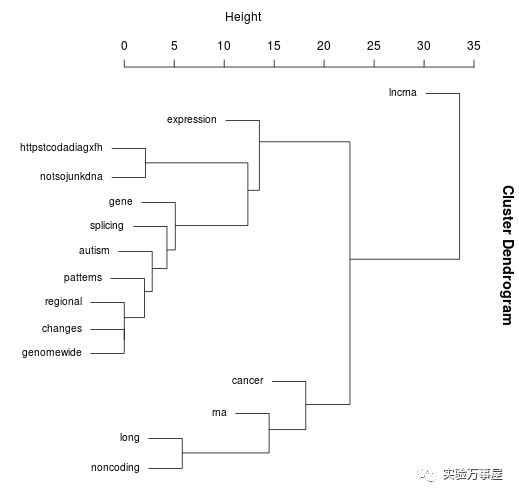
接着是词频的分簇,可以看得到大概这个词在所有的句子中出现频率的分簇分析。但我不懂“httpstcodadiagxfh”有啥关系“not so junk dna”,要么是个网站啥的……好吧,不管怎么样,好像推特上热议的应该是lncRNA的剪切。
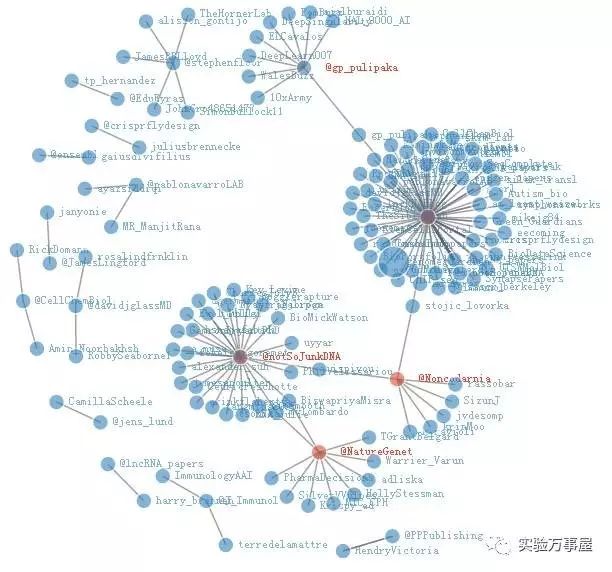
接下去看一下network,这个是推送这些推特的账号之间的联系,可以看得,有蛮多是杂志,还有一些是谁?有可能就是痴迷于lncRNA研究的那些人了,有机会的话,可以考虑关注一下。
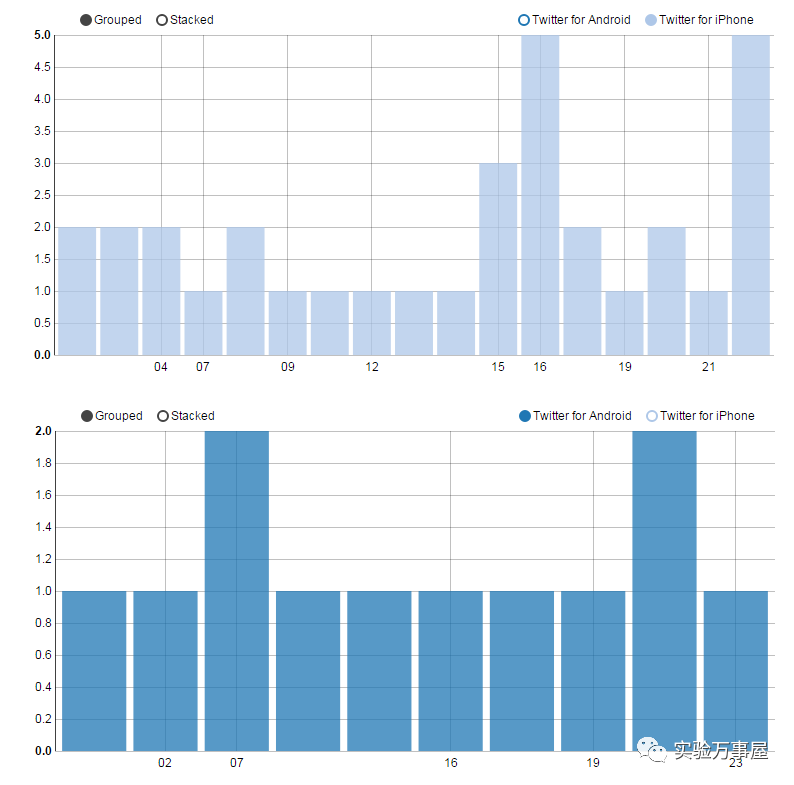
此外还有些付带功能,比如,我们会巧妙地发现,在国外研究lncRNA的安卓狗主要是上班前和下班后会推送lncRNA的内容。而苹果狗则集中在下午和午夜……
网址:https://longhowlam.shinyapps.io/TweetAnalyzer/
还顺便分析了一下别的关键词,比如:机器学习、深度学习。
这种网站基本都是要翻墙才能进去的呢,毕竟要调用推特的数据。不过作为爱国少年的我,也想看看推特上都在讨论中国什么,于是我搜了一下“China”调整到推特内容1000,结果:
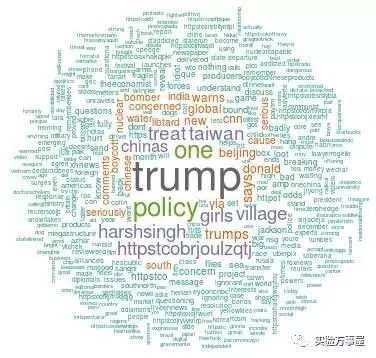
好吧,最近川普大爷赢了……
近日,一直以“
推特治国
”闻名的川普正式宣誓就任了美国第 45 任总统。
川普这次在美国大选中胜出,他的推特也发挥了巨大的作用。相比大多数总统竞选人来说,他们都没时间自己发推。但推特玩的风生水起的川普却表示,他的推特都是自己发的……
那么事实真的是这样吗?
有个美国网友发现
川普发推特有两个客户端
。一个安卓,另一个是 iPhone 。
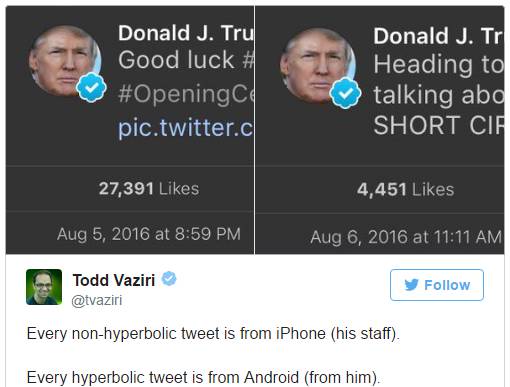
而且这位细心的网友还发现,一些
言辞激烈
的推都
来自安卓
;而
画风
比较
正常
的推都
来自 iPhone
。
这一发现,也引起了数据分析师 David Robinson 的注意。David 注意到当川普发祝贺内容时,是通过 iPhone ;而当他抨击竞选对手时而是通过安卓。而且两个不同客户端通常发推的时间也不太相同。
本着科学严谨的态度,程序员小哥决定让数据说话,于是做了程序,抓取分析了川普发过的推,终于发现了一些模式。并且通过统计,图表,最终他基本确定,川普的推特并不是他一个人写的。

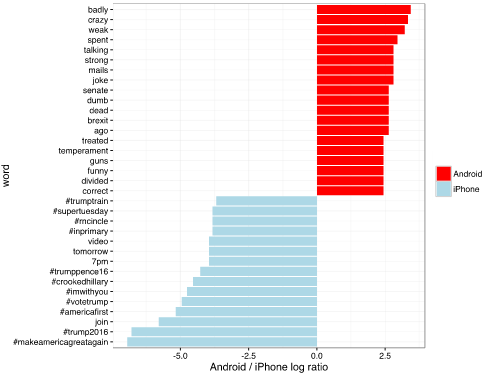
数据证明,安卓端和iPhone发的推分别是两个人所写的。而且发推时间,使用标签,加链接,转发的方式也截然不同。同时,安卓端发的内容更加激烈和消极。
如果就像川普采访中所说他使用的手机是三星 Galaxy ,我们可以确信用安卓发推的是川普本人,用 iPhone 发的大概是他的团队助理。
首先用
twitteR
包中的 userTimeline 函数导入川普发推的时间数据:
♦ library ( dplyr )
♦ library ( purrr )
♦ library ( twitteR )
# You'd need to set global options with an authenticated app
setup_twitter_oauth(getOption(
"twitter_consumer_key"
),
getOption(
"twitter_consumer_secret"
),
getOption(
"twitter_access_token"
),
getOption(
"twitter_access_token_secret"
))
# We can request only 3200 tweets at a time; it will return fewer
# depending on the API
trump_tweets
userTimeline(
"realDonaldTrump"
,
n
=
3200
)trump_tweets_df
tbl_df(map_df(trump_tweets,
as.data.frame))
# if you want to follow along without setting up Twitter authentication,
# just use my dataset:
load(url(
"http://varianceexplained.org/files/trump_tweets_df.rda"
))
稍微清理下数据,提取源文件。(在此只分析来自 iPhone 和 Android tweet 的数据,除去很少一部分发自网页客户端和 iPad 的推文)。
library(tidyr)
tweets
trump_tweets_df
%>%
select(id,
statusSource,
text,
created)
%>%
extract(statusSource,
"source"
,
"Twitter for (.*?)
)
%>%
filter(source
%in%
c
(
"iPhone"
,
"Android"
))
分析的数据包括
来自 iPhone 的 628 条推文
,来
自 Android 的 762 条推文
。
主要考虑推文是在一天内什么时间发布的,在此我们可以发现区别:
♦ library(lubridate)
♦
library(scales)
tweets
%>%
count(source,
hour
=
hour(with_tz(created,
"EST"
)))
%>%
mutate(percent
=
n
/
sum
(n))
%>%
ggplot(aes(hour,
percent,
color
=
source))
+
geom_line()
+
scale_y_continuous(labels
=
percent_format())
+
labs(x
=
"Hour of day (EST)"
,
y
=
"% of tweets"
,
color
=
""
)
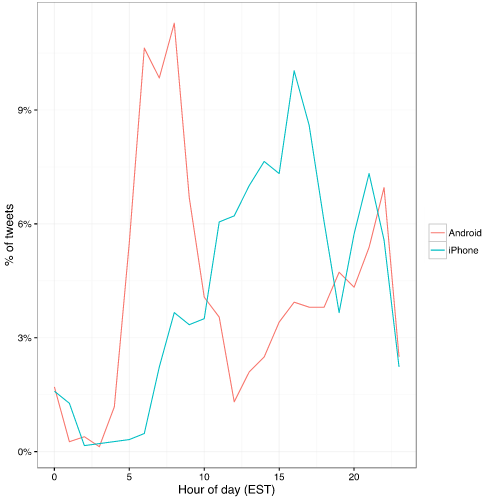
川普一般习惯早上发推,而他的助理会集中在下午或晚上发推。
当川普的安卓手机转推时,习惯用双引号引用这整句话。
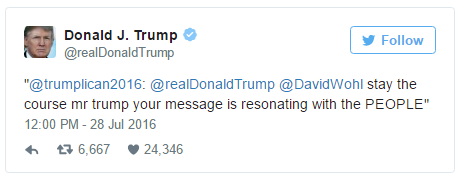
而 iPhone 转推时,一般不使用
双引号
。
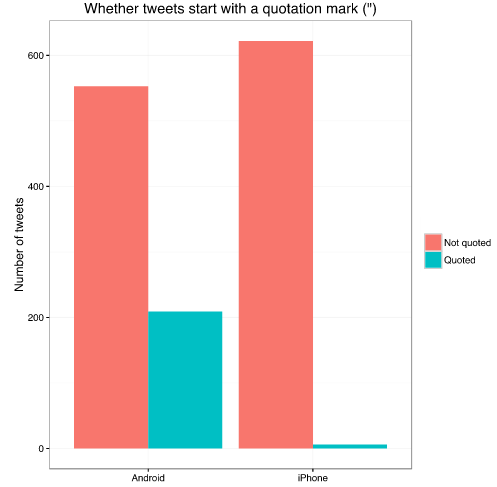
安卓手机: 500 多条推文没有双引号,200 多条有双引号
iPhone:几乎没有双引号
与此同时,在分享
链接和图片
时,安卓和 iPhone 也大不相同。
tweet_picture_counts
tweets
%>%
filter(
!
str_detect(text,
'^"'
))
%>%
count(source,
picture
=
ifelse(str_detect(text,
"t.co"
),
"Picture/link"
,
"No picture/link"
))
ggplot(tweet_picture_counts,
aes(source,
n,
fill
=
picture))
+
geom_bar(stat
=
"identity"
,
position
=
"dodge"
)
+
labs(x
=
""
,
y
=
"Number of tweets"
,
fill
=
""
)
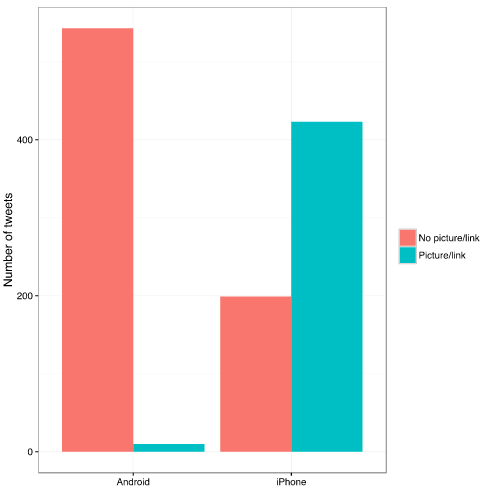
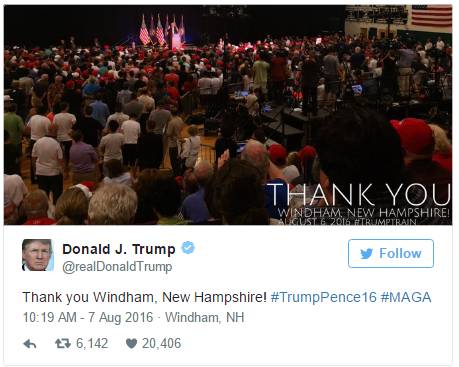
数据证明 iPhone 端 发的推文很多会附上图片,链接。内容也以宣传为主。
比如下面这条:
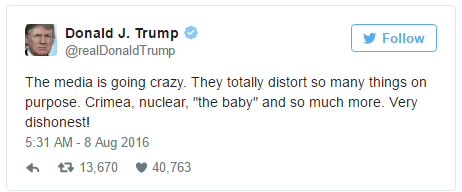
而川普安卓端发的推文没有图片、链接,更多是直接的文字,比如:
在对比安卓和 iPhone 用词区别时,David 用到了他和
Julia Silge
一起编写的
tidytext
包。
用 unnest_tokensfunction 把句子分解为单独的词:
library(tidytext)
reg
"([^A-Za-z\\d#@']|'(?![A-Za-z\\d#@]))"
tweet_words
tweets
%>%
filter(
!
str_detect(text,
'^"'
))
%>%
mutate(text
=
str_replace_all(text,
"https://t.co/[A-Za-z\\d]+|&"
,
""
))
%>%
unnest_tokens(word,
text,
token
=
"regex"
,
pattern
=
reg)
%>%
filter(
!
word
%in%
stop_words
$
word,
str_detect(word,
"[a-z]"
))
tweet_words
## # A tibble: 8,753 x 4
## id source created word
##
## 1 676494179216805888 iPhone 2015-12-14 20:09:15 record
## 2 676494179216805888 iPhone 2015-12-14 20:09:15 health
## 3 676494179216805888 iPhone 2015-12-14 20:09:15 #makeamericagreatagain
## 4 676494179216805888 iPhone 2015-12-14 20:09:15 #trump2016
## 5 676509769562251264 iPhone 2015-12-14 21:11:12 accolade
## 6 676509769562251264 iPhone 2015-12-14 21:11:12 @trumpgolf
## 7 676509769562251264 iPhone 2015-12-14 21:11:12 highly
## 8 676509769562251264 iPhone 2015-12-14 21:11:12 respected
## 9 676509769562251264 iPhone 2015-12-14 21:11:12 golf
## 10 676509769562251264 iPhone 2015-12-14 21:11:12 odyssey
## # ... with 8,743 more rows
总体来说川普推文中有哪些常用词呢?
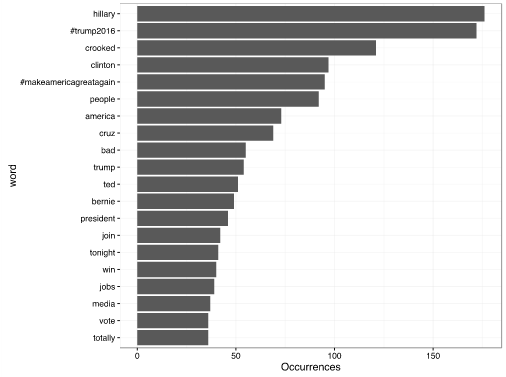
在此基础上我们再来分别看安卓和 iPhone 常用词的区别。

android_iphone_ratios
tweet_words
%>%
count(word,
source)
%>%
filter(
sum
(n)
>=
5
)
%>%
spread(source,
n,
fill
=
0
)
%>%
ungroup()
%>%
mutate_each(funs((.
+
1
)
/
sum
(.
+
1
)),
-
word)
%>%
mutate(logratio
=
log2(Android
/
iPhone))
%>%
arrange(desc(logratio))