公众号ID
|
计算机视觉研究院
学习群
|
扫码在主页获取加入方式
论文下载 |
回复“
DSGN
”获取源码
论文:https://arxiv.org/pdf/2001.03398.pdf
Column of Computer Vision Institute
目前自动驾驶愈演愈烈,技术也越来越成熟,从不可能上路到现在大家抢着去感受该新技术,未来电车是趋势,该领域的技术会是研究者关注的热点的话题。
今日,我们“计算机视觉研究院”来跟大家分享一个高精度的目标检测框架!
大多数最先进的3D目标探测器严重依赖LiDAR传感器,因为在基于图像和基于LiDAR的方法之间有很大的性能差距。它是由在3D场景中形成预测表示的方式引起的。

研究者提出新的方法,被称为深度立体几何网络(
DSGN
),通过检测可微体积表示-3D几何体积上检测3D目标,显著缩小了这一差距,有效地编码了3D正则空间的3D几何结构。通过这种表示,同时学习深度信息和语义线索。提供了一个简单而有效的基于单阶段立体的3D检测 pipeline,它以端到端学习的方式联合估计深度和检测3D目标。
研究者提出了一种基于立体的端到端3D目标检测
pipeline
(如下图图1)——Deep
Stereo Geometry Network (
DSGN
),它依赖于空间转换从二维特征到有效的三维结构,称为三维几何体积(3DGV)。
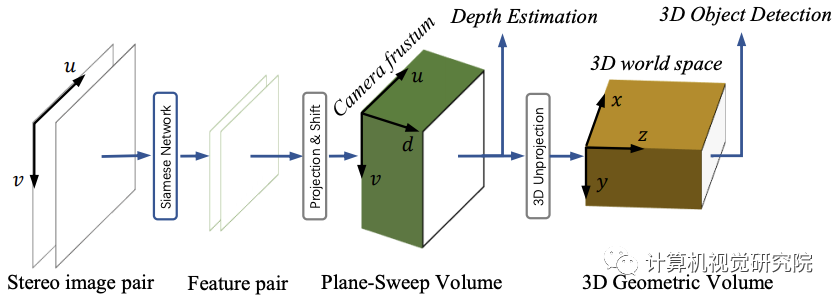
3DGV背后的见解在于构建编码
3D
几何图形的
3D
体积的方法。3D几何体积定义在3D world space中,由 camera frustum中构造的平面扫描体积(PSV)转换。像素对应约束可以在PSV中很好地学习,而现实世界目标的三维特征可以在3DGV中学习。
体积结构是完全可微的,因此可以联合优化来学习立体匹配和目标检测。这种体积表示有两个关键的优势。首先,可以很容易地施加像素对应约束,并将全深度信息编码到o 3D real-world的体积中。其次,它提供了具有几何信息的三维表示,使学习真实目标的三维几何特征成为可能。据我所知,目前还没有任何研究要明确地研究将三维几何编码到基于图像的检测网络中的方法。
Deep Stereo Geometry Network
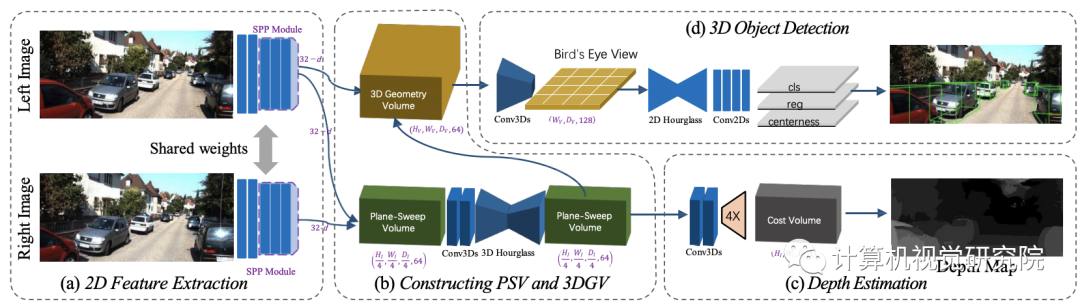
接下来我来分析,整个pipeline——DSGN,如上图所示。利用双目图像对的输入,通过 Siamese网络提取特征,并构造了一个平面扫描体积(PSV)。像素的对应关系是在这个体积上学习的。通过可微,将PSV转换为三维几何体积(3DGV),以在
3D world space
中建立三维几何。然后通过三维体积上的3D神经网络学习3D目标检测的必要结构。
Stereo matching和目标识别的网络对各自的任务有不同的体系结构设计。为了保证
stereo matching
的合理准确性,研究者采用了PSMNet的主要设计。由于检测网络需要一个基于高级语义特征和较大的上下文信息的判别特征,因此研究者对网络进行了修改,以获取更多的高级信息。
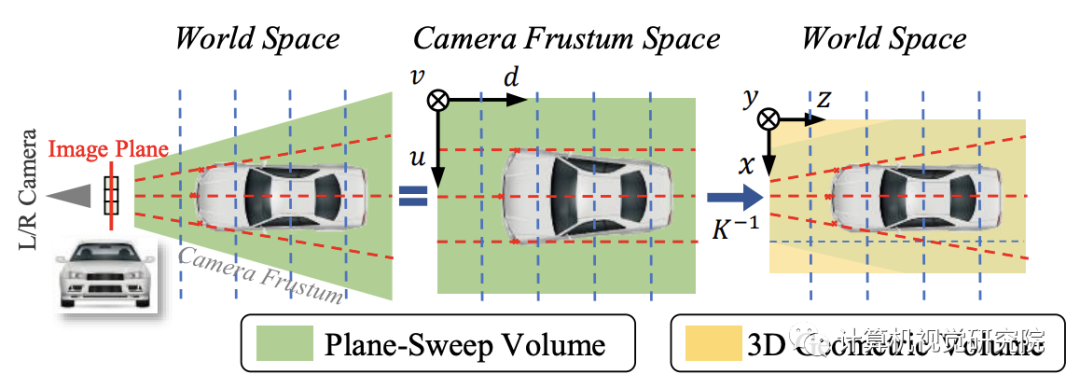
上图说明了转换过程。在camera frustum中施加常见的像素对应约束(红线),而在regular 3D world space (欧几
里得空间)中学习目标识别。这两种表示显然是有区别的。在平面扫描体积的最后一个特征图中,lowcost voxel(u、v、d)是指沿射线通过焦点和图像点(u、v)存在的物体的高概率。
随着向
r
eg
u
lar 3D wo
rld space
的转换,低成本的特征表明该三位像素占据在场景的前面,可以作为三维几何结构的特征。因此,以下3D网络可以学习此体积卷上的3D目标特性。该操作与unprojection有根本的不同,后者通过双线性插值直接将图像特征从二维图像帧提升到三维空间。
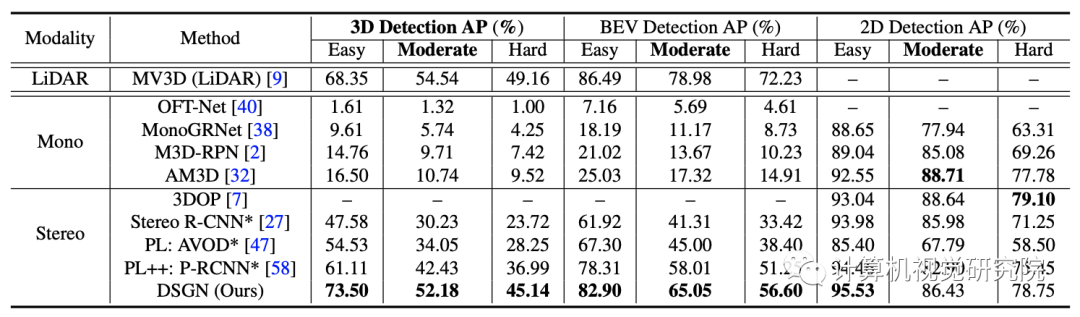
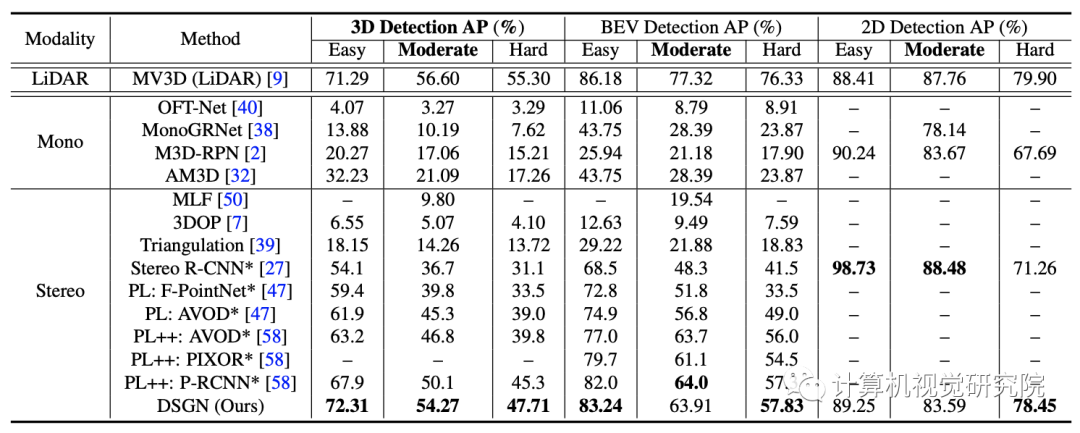
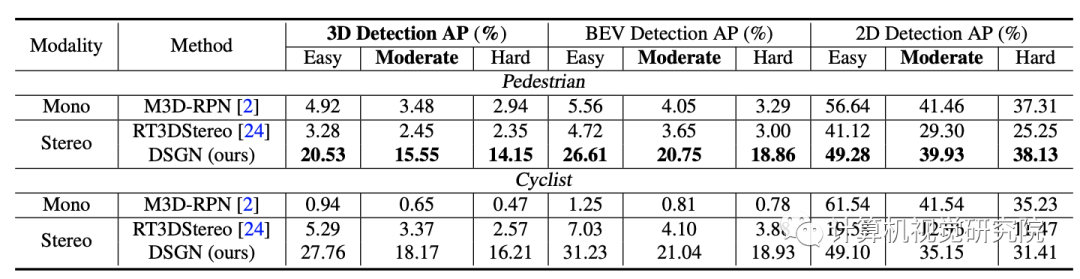
DSGN甚至在BEV检测上取得了类似的性能,在MV3D上实现了更好的3D检测性能,这是一种经典的基于LiDAR的3D目标检测器。
这一结果表明,在低速自动驾驶的情况下,至少有一个很有前途的未来应用前景。
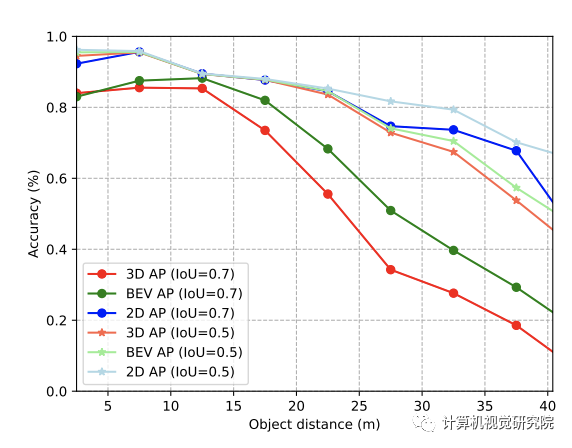
检测精度与距离相比。研究者将范围[0,40](米)分为8个间隔,每个间隔5米。所有的评估均在每个时间间隔内进行。
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!











