
©作者 |
唐晨夏
单位 |
中国科学技术大学
研究方向 |
大模型推理

我们是否完全激发了大模型的所有性能?极简采样算法
让大模型推理性能再创新高,而其核心代码仅仅两行:
threshold = logits.max(dim=-1, keepdim=True).values - n*logits.std(dim=-1, keepdim=True)
logits[logits'-inf')
论文题目:
Top-nσ: Not All Logits Are You Need
Chenxia Tang, Jianchun Liu, Hongli Xu, Liusheng Huang
University of Science and Technology of China
https://arxiv.org/abs/2411.07641

在大语言模型(LLM)应用中,解码策略直接决定了模型输出的质量。形式地说, 大模型接收一个字符串
,输出一个 logits 向量
,然后经过 softmax 得到概率分布
,再从中采样。
然而,从这个原始概率分布中直接采样往往会产生不连贯、质量欠佳的输出。另一种直观的做法是始终选择概率最高的 token(贪心解码),但这种策略会为了 51% 的概率而放弃 49% 的可能性,这违背了语言模型作为概率模型的本质。
OpenAI,Claude 等公司提供了许多流行的采样方法,例如 Top-k,Top-p,Min-p。这些方法经验地选择一个可行 token 集合(通常很小),而将其他 token 对应的概率设置为零。然而,这相当于直接修改了 LLM 的分布,开源项目 DRµGS(https://github.com/EGjoni/DRUGS)关于此有一个辛辣的评论:

问题在于:从更高层次来说,生成式建模的格局是这样的:首先花费数百万美元预训练一个庞大的模型,让它预测人类的所有作品集,然后将这些预测结果交给一个智商堪比石头的随机数生成器,让它作为最终仲裁者“好心地”考虑这些预测(而这个价值数百万美元的模型在下一轮预测时必须遵从这个结果)。
我们不禁想问:
LLM 的原始分布究竟差在哪里了?

通常来说,大模型采样上的问题都可以归结为噪声:一些很小但不可忽略的概率值干扰了采样过程:
▲ https://medium.com/@aalokpatwa/llm-decoding-balancing-quality-and-latency-23632cc0277e
这些噪声看上去毫无规律,往常的工作如 eta-sampling 因此假设它们服从均匀分布:

然而,本文作者通过检查 pre-softmax logits,发现 logits 被划分为两个区域,对应着噪声的左侧区域实际上是一个正态分布,因此混合的分布实际上是一个对数正态分布:
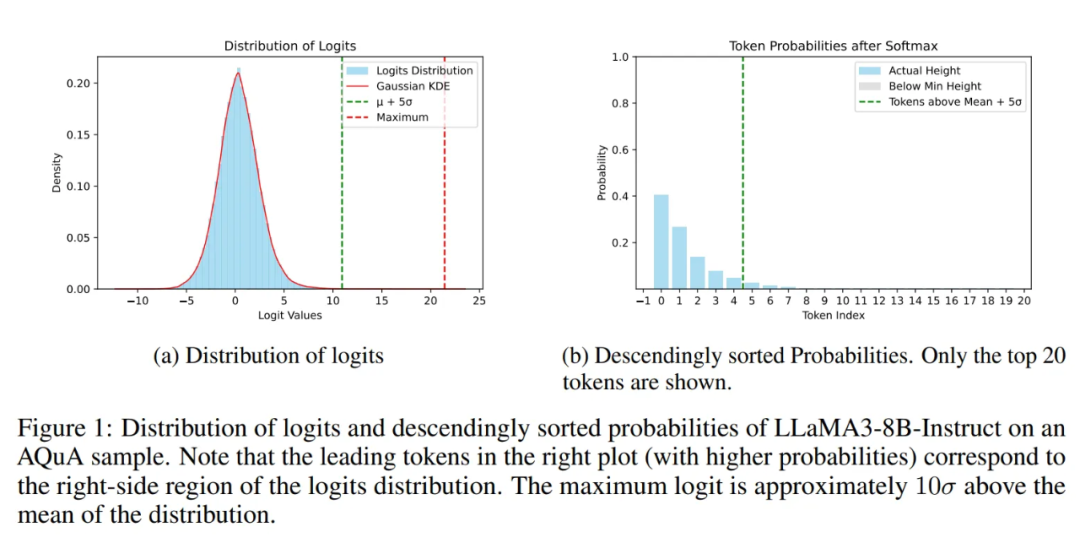
通常,由于大数定理,正态分布的出现都暗示某种纯粹的随机噪声。作者在文中指出该正态分布的出现并非偶然,它大致可以由三个因素导致:
-
-
-
模型必须为每个 token 赋予一个有限值,无法输出负无穷。
作者指出,如果我们能将这个正态分布去除,那么余下的正是我们想要的真实分布。

本文提出的 Top-
方法巧妙地化解了这一矛盾。基于以上发现,Top-
通过设定 n 个标准差 (
) 作为阈值,高效过滤噪声:


突出优势
-
稳定性:
即使在高温度下保持稳定的采样空间,不会引入额外噪声
-
性能:
在多个推理任务数据集上超越现有采样方法,甚至优于贪婪解码
-
简洁:
无需复杂概率计算和参数调优,实现极其优雅

在 AI 领域,富有洞见的简单方法往往比复杂的算法更有生命力。对于工程实践者而言,Top-
正是一个几乎零成本就能带来显著提升的优化方案。
如果您正在处理 LLM 的解码问题,不妨尝试这个仅需两行代码的创新方法,也许会有意想不到的惊喜。

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?
答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是
最新论文解读
,也可以是
学术热点剖析
、
科研心得
或
竞赛经验讲解
等。我们的目的只有一个,让知识真正流动起来。
📝
稿件基本要求:
• 文章确系个人
原创作品
,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以
markdown
格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供
业内具有竞争力稿酬
,具体依据文章阅读量和文章质量阶梯制结算
📬
投稿通道:
• 投稿邮箱:
[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(
pwbot02
)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在
「知乎」
也能找到我们了
进入知乎首页搜索
「PaperWeekly」






