加入雷锋网,分享AI时代的信息红利,与智能未来同行。听说牛人都点了这里。
 雷锋网按:本文作者陈孝良,工学博士,声智科技创始人。雷锋网独家文章。
雷锋网按:本文作者陈孝良,工学博士,声智科技创始人。雷锋网独家文章。
11月30号,亚马逊的AWS发布了三项人工智能技术服务:Amazon Rekognition,Amazon Polly和Amazon Lex。其中,除了Amazon Rekognition属于图像识别技术,其他两项服务都是语音交互的链条。Amazon Polly 利用机器学习技术,能够快速实现从文本到语音的转换。Amazon Lex 就是亚马逊的人工智能助手 Alexa 的内核,而 Alexa 已经被应用于亚马逊的 Echo 系列智能音箱。
根据AWS服务网页的示例展示和实际调用,Polly 的发音与人声已经非常相像,很多时候已经很难分辨机器与人声的界限。不仅如此,Polly 还能够按照语境对同形异义词的发音进行区分,比如说,在 “I live in Seattle” 和 “Live from New York” 这两个不同的语境下,单词 “Live” 的发音是不同的,而 Polly 在发音过程中就能够很好把握它们之间的区别。Amazon Polly 共拥有 47 种男性或女性的发音,支持 24 种语言,遗憾的是目前还不支持汉语。

相对Amazon的节奏,Google似乎慢了许多,早在9月初,Google的DeepMind实验室公布了其在语音合成领域的最新成果WaveNet,一种原始音频波形深度生成模型,能够模仿人类的声音,生成的原始音频质量优于目前常用的语音合成方法,包括参数化合成(Parameric TTS)与拼接式合成(Concatenative TTS)。
参数化语音合成是最常用也是历史最悠久的方法,就是利用数学模型对已知的声音进行排列、组装成词语或句子来重新创造声音数据。当前机器人的发音主要就是采用的这种方法,不过参数化合成的语音听起来总是不自然,真的就像机器发出的声音。
另外一种就是拼接式语音合成,先录制单一说话者的大量语音片段,建立一个大型语料库,然后简单地从中进行选择并合成完整的大段音频、词语和句子。我们有时会听到机器模仿某些明星的声音,其背后技术就是这种方法。但是这种方法要求语料库非常大,而且处理不好就经常产生语音毛刺和语调的诡异变化,并且无法调整语音的抑扬顿挫。
WaveNet则引入了一种全新的思路,区别于上面两种方法,这是一种从零开始创造整个音频波形输出的技术。WaveNet利用真实的人类声音剪辑和相应的语言、语音特征来训练其卷积神经网络,让其能够辨别语音和语言的模式。WaveNet的效果是惊人的,其输出的音频明显更接近自然人声。
WaveNet技术无疑是计算机语音合成领域的一大突破,在业界也引起了广泛讨论。但是其最大缺点就是计算量太大,而且还存在很多工程化问题。但是短短3个多月,亚马逊就已经凭借Echo的数据和技术的快速迭代,抢先将类似的技术应用到产品之中,而且正式开放给AWS用户进行使用和测试。
更为重要的是,亚马逊同步正式开放了Amazon Lex的服务,Lex 能够帮助用户建立可以进行多重步骤的会话应用,开发者可以通过它来打造自己的聊天机器人,并将其集成到自己开发的 Web 网页应用或适用于移动端的 App 中去。它也可以被应用于提供信息、增强程序功能,甚至用来控制无人机、机器人或玩具等。
这就很有意思了,从下面一张语音交互的技术链条来梳理一下亚马逊的策略。亚马逊首先从语音识别公司 Nuance 挖了一批人才,2011年又收购了两家语音技术创业公司 Yap 和 Evi,实现了语音识别的技术布局。随后启动了适应远场语音交互Echo产品的研发工作,并在2015年和2016年成为了最成功的智能硬件产品。Echo产品帮助亚马逊实现了以麦克风阵列为核心技术的硬件终端技术的布局。这两项技术的布局积累,帮助亚马逊快速发展,其语音助手团队快速拓展到千人规模,凭借庞大的数据和深厚的人才积累,亚马逊在智能交互领域持续发力,拥有更好体验的TTS和NLP也实现了快速迭代,奠定了亚马逊在智能语音交互应用领域的领先地位。
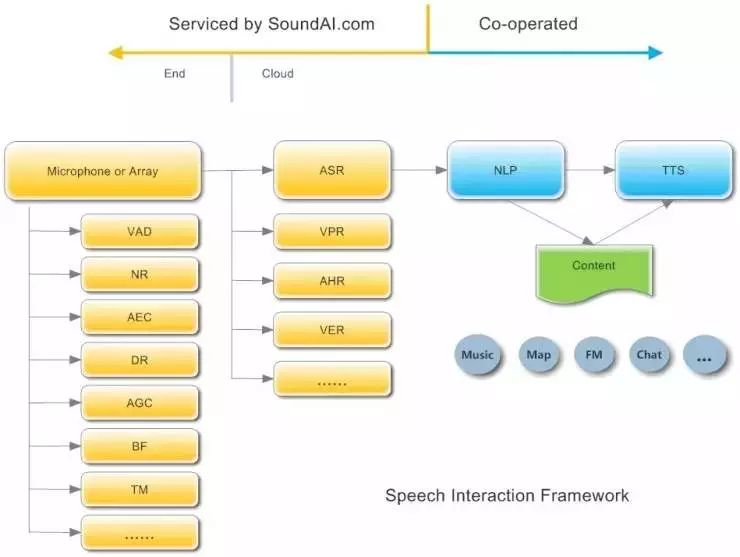
事实上,从今年下半年语音交互市场的突然爆发,几乎每隔一个多月,语音交互的效果都会出现较大的提升。那么为何语音交互技术的迭代会如此迅速?可以从下面几点来窥得一斑:
1、语音交互技术链条的成熟
深度学习带给了语音识别巨大的进步,但是以Siri为代表的手机语音交互一直不温不火,直到Echo和车载这类智能设备的出现,语音识别才突破手机的限制,真正落地到真实的垂直场景。这个转变不仅仅是场景的转变如此简单,实际上这从认知和技术上都是一个巨大的变化。真实场景的语音识别面向的是真正用户,因此能否满足用户需求就是一个关键问题。
当前的用户对于人工智能的要求其实并不高,而是希望确实能够解决一些具体问题,但是显然通用的语音交互总是伴随着智慧的概念,根本就无法做到令用户满意。因此语音交互的落地首先就要考虑是否能够先服务好用户,这是一个关键的认知变化,而且基于这种认知,语音交互的免费策略似乎就不重要了,用户更为关注的是性能而非低价。另外一点就是技术链条的成熟,语音识别从手机转向垂直场景,需要解决远场语音识别和场景语言理解的问题,亚马逊率先解决了这些问题,国内科大讯飞和声智科技也随后补齐了这个链条。目前来看,智能语音交互的技术链条趋于成熟,已经不存在较大的障碍。
2、真实场景数据规模的扩大
随着Echo的热卖,对于场景交互尤为重要的真实数据急剧增加,原先训练可能只有几千或者几万个小时,但是亚马逊已经从已售设备中获取了几千万的数据,而当前的训练已经是十万级数据的规模,将来百万级的数据训练也会出现。事实上,这些庞大的数据中囊括了用户时间长度和空间维度的信息,这是手机时代绝对做不到的,从这些丰富信息之中,即便简单搜索提升的效果都是惊人的。
3、云端计算能力的不断提高
拥有了庞大的数据量,自然就急需要计算能力的不断提升,前几天Intel召开发布会,雷锋网(公众号:雷锋网)现场也做了直播,CPU和GPU的综合计算能力再次提升了20多倍,这相当于原先需要训练20天的数据,现在可能不到1天就能完成,这是语音交互产业链条的根本性保证。
4、 深度学习人才聚集的效应
技术、数据、计算链条的相对完善,核心还需要人才的驱动,而随着人工智能的热潮,不断有更多相关人才从科院机构和院校走出来加入这个行业。创业公司的竞争是可怕的,这群大牛才华横溢,却没日没夜的拼搏,其效率提升到其他任何时代可能都难以匹及的程度。
总之,智能语音交互这个链条已经具备了大规模普及的基础,等待的只是用户习惯的改变,而这种改变正在逐步发生。可预见的几年,语音交互应该相对于其他人工智能技术,应该是最先落地的一种技术,而且其迭代的速度可能会超过我们的预期。但是语音交互仍然还有很多问题需要解决,包括终端技术的低功耗和集成化、语音识别的场景化和一体化,以及语言理解的准确性和引导性。
未来几年,智能语音交互的迭代至少还要解决如下几个问题:
一是如何基于用户提出的多种多样的、基于情感的、语意模糊的需求进行深刻分析,精确理解用户的实际需求;
二是如何将各种结构化、非结构化、半结构化的知识进行组织与梳理,最终以结构化、清晰化的知识形式完整地呈现给用户;
三是如何猜测用户可能会有什么未想到、未提出的需求,从而先人一步为用户提供相关的扩展信息;
四是如何将信息进行有效地组织与整理,以条理化、简洁化、直接化的形式呈现给用户。
谈及最后一个问题,又不得不说下亚马逊Echo为何要考虑加个7寸屏了,这虽然会使Echo的品类属性减弱,但是在AR还没有发展起来之前,确实也没有更好的办法。毕竟Echo缺少一个使得人机交互更完整的重要的组件——视觉交互,没有用户界面或上下文元素的基于语音交互的系统是不完整。用户可以通过聊天的方式来播放音乐、定时、控制灯光,获得新闻头条,然而当用户在线订单想比较一下两种产品的价格,各种性能参数,或者想看一下未来一周天气预报的温度趋势,用户目前来说还是需要一块屏。正是基于这种考虑,声智科技提供的智能音箱解决方案中,恰好有一个型号也是搭配了7寸显示屏。











