本文,将介绍数据库架构设计中的一些
基本概念
,
常见问题
以及对应
解决方案
,为了便于读者理解,将以“用户中心”数据库为例,讲解数据库架构设计的常见玩法。
一、用户中心
用户中心
是一个常见业务,主要提供用户注册、登录、信息查询与修改的服务,其核心元数据为:
User(uid, uname, passwd, sex, age,nickname, …)
其中:
-
uid
为用户
ID
,主键
-
uname, passwd, sex, age, nickname, …
等为用户的属性
数据库设计上,一般来说在业务初期,单库单表就能够搞定这个需求。
二、图示说明
为了方便大家理解,后文图片说明较多,其中:
-
“灰色”方框,表示
service
,服务
-
“紫色”圆框,标识
master
,主库
-
“粉色”圆框,表示
slave
,从库
三、单库架构
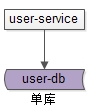
最常见的架构设计如上:
四、分组架构
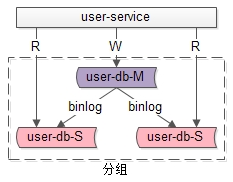
什么是分组?
答
:分组架构是最常见的
一主多从,主从同步,读写分离
数据库架构:
主和从构成的数据库集群称为“组”
。
分组有什么特点?
答
:同一个组里的数据库集群:
分组架构究竟解决什么问题?
答
:
大部分互联网业务读多写少
,
数据库的读往往最先成为性能瓶颈
,如果希望:
-
线性提升数据库读性能
-
通过消除读写锁冲突提升数据库写性能
-
通过冗余从库实现数据的“读高可用”
此时可以使用分组架构,需要注意的是,
分组架构中,数据库的主库依然是写单点
。
一句话总结,
分组解决的是“数据库读写高并发量高”问题
,所实施的架构设计。
五、分片架构
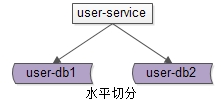
什么是分片?
答
:分片架构是大伙常说的
水平切分
(sharding)
数据库架构:
-
user-service
:依旧是用户中心服务
-
user-db1
:水平切分成
2
份中的第一份
-
user-db2
:水平切分成
2
份中的第二份
分片后,多个数据库实例也会构成一个数据库集群。
水平切分,到底是分库还是分表?
答
:
强烈建议分库
,而不是分表,因为:
水平切分,用什么算法?
答
:常见的水平切分算法有
“范围法”和“哈希法”
:
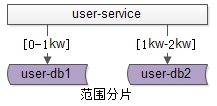
范围法
如上图:以用户中心的业务主键
uid
为划分依据,将数据水平切分到两个数据库实例上去:
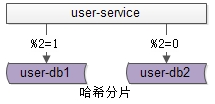
哈希法
如上图:也是以用户中心的业务主键
uid
为划分依据,将数据水平切分到两个数据库实例上去:





