引言
本文给大家讲述的是我们如何去构建一个日志系统,用到了那些技术,为什么用这些技术,并且讲述了遇到的问题及优化的过程,希望给大家在实践中能够提供一些参考。
最近在维护一个有关于日志的项目,这个项目是负责收集、处理、存储、查询京东卖家相关操作的日志,我们这里就叫它“卖家日志”。在日常的开发过程中,可能我们对日志这个词并不陌生,例如我们常接触到的log4j、slf4j等等,这些日志工具通常被我们用来记录代码运行的情况,当我们的系统出了问题时,我们可以通过查看日志及时的定位问题的所在,从而很快的解决问题,今天我所讲的卖家日志,又与这个有些许的不同,卖家日志是用来记录卖家对系统各个功能的操作情况,例如:张三这个商家对它的店铺的某款商品进行了价格的修改。这样在我们这就会记录下一条日志在我们的系统当中,在这个系统中的部分信息我们是可以提供给商家、运营人员看,从而让商家知道自己做了哪些操作,也让运营人员更好的对商家进行管理,除此之外,也可以帮忙查找从log中找不到的信息,从而帮助开发人员解决问题。其他的不多说,接下来就讲一下我们的业务场景。
业务场景
我们有许多的业务系统,如订单、商品,还要一些其他的系统,之前,大家都是各自记录各自的日志,而且记录的方式五花八门,格式也独具一格,而对于商家和运营人员来说这是非常头疼的一件事,没有给运营人员提供一个可以查询日志的平台,每次有问题的时候,只能耗费大半天的时间去找对应的开发团队,请他们配合找出问题所在,而且有的时候效果也不是很好。在这么一种情况下,卖家日志就诞生了,它给商家和运营以及开发提供了一个统一的日志平台,所有团队的日志都可以接入这个平台,通过申请权限,并且运营和商家有问题可以第一时间自己去查找日志解决问题,而不是盲目的找人解决。
日志总体设计
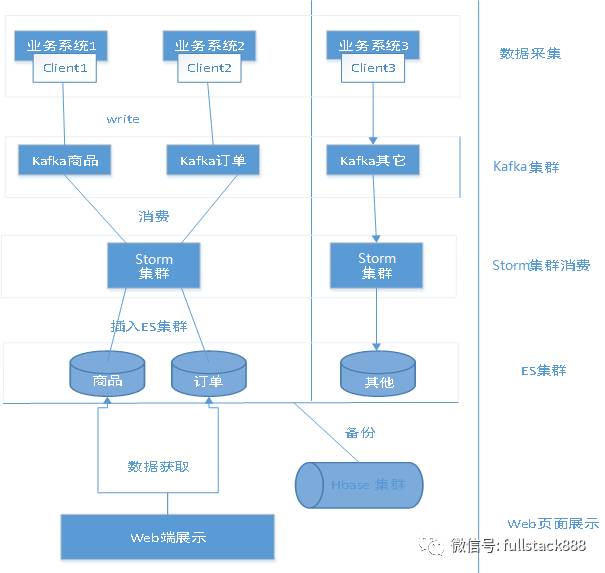
图是这个日志系统总体的整体流程图,在对于处理日志这一块业务上,我们写了一个日志客户端提供给各个组调用,还用到了kafka+Strom的流式计算,对于日志查询这一块,我们首先想到了ES,因为ES是一个分布式的文件检索系统,它可以根据日志的内容提供丰富的检索功能,而对于冷日志的存储,我们用到了一个能够存更大量的工具—HBase,并且也可以根据一些基本的条件进行日志的搜索。
流程:日志客户端 - Kafka集群 - Strom消费 - ES -HBase - ...
技术点
-
Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,说浅显易懂一点,我们可以将Kafka理解成为一个消息队列。
-
Storm:Storm是开源的分布式实时大数据处理框架,它是实时的,我们可以将它理解为一个专门用来处理流式实时数据的东西。
-
ElasticSearch:ES是一个基于Lucene的搜索服务器,它是一个分布式的文件检索系统,它给我们提供了高效的检索,以及支持多种检索条件,用起来也十分方便。
-
HBase:HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,适用于结构化的存储,底层依赖于Hadoop的HDFS,利用HBase技术可在廉价PCServer上搭建起大规模结构化存储集群。
日志客户端
日志客户端给各个系统提供了一个统一的Api,就类似于Log4j这些日志工具一样,这样使得接入变得方便简洁,就和平常写日志没什么区别。这里需要提到的一个点是客户端对于日志的处理过程,下面我用图来给大家进行说明,如下图:
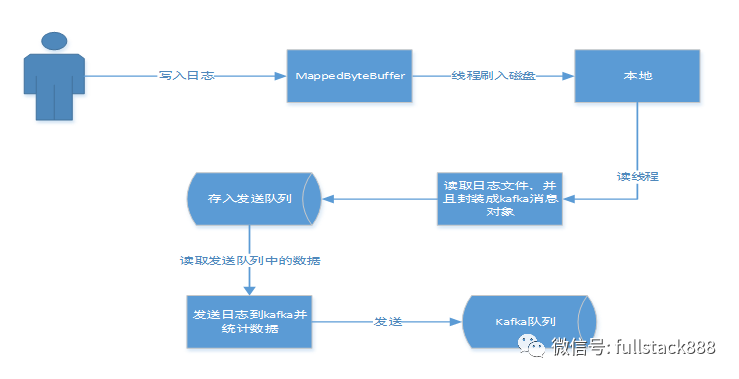
大家可能会疑惑,为什么不直接写Kafka呢?那么接下来我给大家做个比较,直接写入本地快,还是写Kafka快呢?很明显,写入本地快。因为写日志,我们想达到的效果是尽量不要影响业务,能够以更快的方式处理的就用更快的方式处理,而对于日志后期的处理,我们只需要在后台开启固定的几个线程就可以了,这样既使的业务对此无感知,又不浪费资源,除此之外,落盘的方式还为日志数据不丢提供了保障。
此外,这里本地数据的落盘和读取都用到了Nio的内存映射,写入和读取的数据又有了进一步的提升,使得我们的业务日志快速落盘,并且能够快速的读取出来发送到Kafka。这也是这一块的优势。
为什么要用Kafka
首先给大家介绍一下Kafka,其实网上也有很多的例子,接下来我说一下我对Kafka的理解吧,有不对的地方还请大家及时指正。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,说浅显易懂一点,我们可以将Kafka理解成为一个消息队列。具体的一些细节,大家可以上网搜索。
Kafka主要应用场景中:
-
持续的消息:为了从大数据中派生出有用的数据,任何数据的丢失都会影响生成的结果,Kafka提供了一个复杂度为O(1)的磁盘结构存储数据,即使是对于TB级别的数据都是提供了一个常量时间性能。
-
高吞吐量:keep big data in mind,Kafka采用普通的硬件支持每秒百万级别的吞吐量
-
分布式:明确支持消息的分区,通过Kafka服务器和消费者机器的集群分布式消费,维持每一个分区是有序的。
-
支持多种语言:Java、.net、PHP、ruby、Python。
-
实时性:消息被生成者线程生产就能马上被消费者线程消费,这种特性和事件驱动的系统是相似的。
Kafka的优势:
通过上面对Kafka的应用场景和优势的描述,我们再去理解我们的日志的业务场景,就能理解我们为什么采用的技术是Kafka了。因为Kafka快,并且适用于流式处理,它可以将突发的量转换成为平稳的流,以便于我们Strom的处理。至于为什么快,我在这就不给大家详解了。因为日志是不定时的,就像水流一样,一直是不断的,并且不一定是平稳的。而Kafka的一些特性,非常符合我们日志的业务,除此之外,Kafka作为一个高吞吐量的分布式发布订阅消息系统,可以有多个生产者和消费者,这也为我们的日志统一接入和后期的多元化处理提供了强有力的保障。如下图:
Storm的应用
前面也介绍了,日志是一个流式的数据,它是不定时的,而且是不平稳的,我们需要将这些不定时且不平稳的数据进行处理,用什么方式更好呢?我们在这一块进行了一场讨论,而最终我们采用了Kafka+Storm的方式来处理这些日志数据。Kafka我就不过多介绍了,前面讲了。为什么要用Storm呢?对于Storm,我想大家应该有所了解,Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,我们看重的就是它的流式计算的能力。Kafka可以将突发的数据转换成平稳的流,源源不断的推向Storm,Storm进行消费,处理,最终落库。下面我简单的画一下Storm处理这一块的流程,如下图所示:
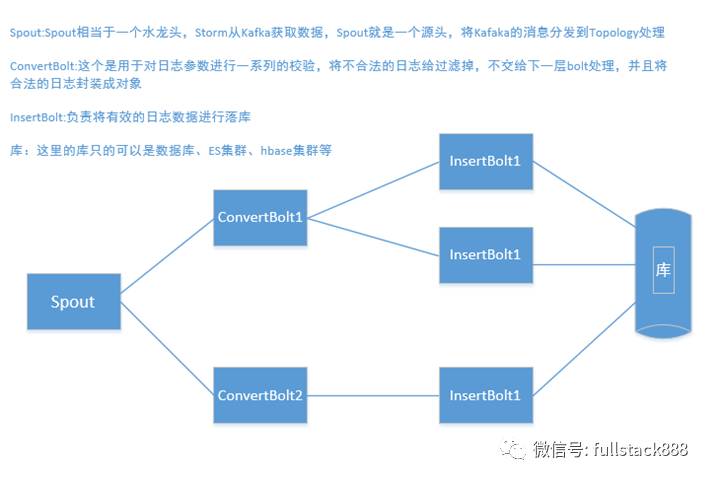
从上图我们可以看到Storm整个一个处理的流程,其中我们对日志进行了两次的处理,一次是校验是否有效,并且封装成对象交给下一个bolt,insertBolt负责将数据落库,这么一个流程看起来比较清晰明了。
关于数据存储的处理
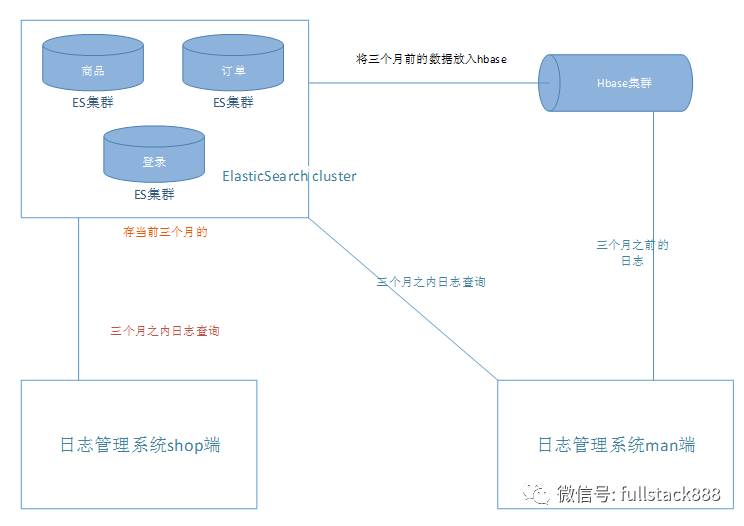
对于数据的存储,从上面我们可以知道我们用的ES来对热数据进行存储,而对于冷数据,也就是很久之前的数据,我们采用HBase来进行存储备份。为什么要这样做呢,下面我给大家说一下这样做的原因。
日志数据使用什么样东西做存储,直接影响这我们的查询,前期我们的想法是直接把数据存到能够抗量HBase上,但是对于多种条件的查询,HBase显然不符合我们的要求,所以经过评审,决定用一个分布式检索的系统来进行存储,那就是ElasticSearch。那大家可能会问到:为什么还要用HBase呢?因为ES作为一个检索的系统,它并不适用于大量的数据的存储,随着数据量的增大,ES的查询性能会慢慢的降低,而我们的日志需要保存的时间是一年,每天的量都是6、7亿的数据,所以对于ES来说,很难抗住,不断的加机器并不是很好的解决办法。经过讨论,我们想用一个更能够存数据的东西来存很久不用的日志数据,并且能够提供简单的检索,我们想到了HBase,将最近两个月的数据放在es中,给用户提供多条件的检索,两个月之前的数据我们存放在HBase中,提供简单的检索功能,因为两个多月前的日志也没有太大的量去查看了。具体的数据流转如下图:
遇到的问题
随着数据量的增多,对我们服务的要求要来越高了,我们发现,即使是将存储的数据做了冷热分离,查询也非常的忙,并且随着数据量的增多,插入的性能也越来越慢了。而且,对于我们所申请的Kafka集群,明显也扛不住这么多客户端每天输入这么大的量,因为这些问题,我们放慢了脚步,对日志这一块的业务流程进行了仔细的梳理。
解决方案
经过不断的讨论和架构的评审,我们想到了一个比较好的解决办法,那就是对日志数据进行业务分离。我们抽出了几个日志量比较大的业务,比如订单和商品,我们新申请了订单和商品的Kafka集群和ES集群,其他一些业务还是不变,订单和商品的日志和其他日志都单独开来,使用不同的Kafka和ES、HBase集群。我们通过对业务的抽离,性能得到了很明显的提升,并且对数据进行业务的分类,也方便了我们对日志数据的管理,达到互不影响的状态。今后对于HBase的数据,我们也打算将它推入到大数据集市中,提供不同的部门做数据分析。
结语
上面我们将日志的一整套流程都给大家描述了一遍,有一些细节方面的东西没有详细的去讲解,就比如说日志发送的监控,日志的鉴权,日志的权限管理等等,主要的是讲述了整体的架构。也许这个架构不是最优的,但是对于一个系统而言,一开始系统的强大一定不是一蹴而就的,而是经过不断的壮大,发现问题,解决问题,不断的完善,从而达到一个最优的状态





