
文:Rick Radewagen
译:李萌
在银行欺诈检测,市场实时竞价或网络入侵检测等领域通常是什么样的数据集呢?
在这些领域使用的数据通常有不到
1
%少量但“有趣的”事件,例如欺诈者利用信用卡,用户点击广告或者损坏的服务器扫描网络。
然而,大多数机器学习算法对于不平衡数据集的处理不是很好。 以下七种技术可以帮你训练分类器来检测异常类。
1.使用正确的评估指标
对使用不平衡数据生成的模型应用不恰当的评估指标可能是危险的。
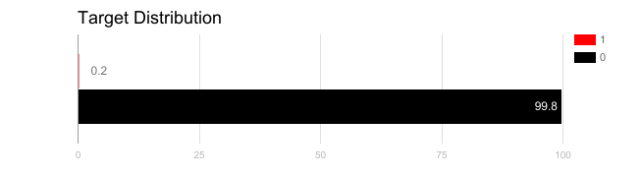
想象一下,我们的训练数据如上图所示。 如果使用精度来衡量模型的好坏,使用将所有测试样本分类为“0”的模型具有很好的准确性(99.8%),但显然这种模型不会为我们提供任何有价值的信息。
在这种情况下,可以应用其他替代评估指标,例如:
-
精度/特异性:有多少个选定的相关实例。
-
调用/灵敏度:选择了多少个相关实例。
-
F1得分:精度和召回的谐波平均值。
-
MCC:观察和预测的二进制分类之间的相关系数。
-
AUC:正确率与误报率之间的关系。
2.重新采样训练集
除了使用不同的评估标准外,还可以选择不同的数据集。使平衡数据集不平衡的两种方法:欠采样和过采样。
欠采样通过减少冗余类的大小来平衡数据集。当数据量足够时使用此方法。通过将所有样本保存在少数类中,并在多数类中随机选择相等数量的样本,可以检索平衡的新数据集以进一步建模。
相反,当数据量不足时会使用过采样,尝试通过增加稀有样本的数量来平衡数据集。不是去除样本的多样性,而是通过使用诸如重复,自举或SMOTE等方法生成新样本(合成少数过采样技术)
请注意,一种重采样方法与另一种相比没有绝对的优势。这两种方法的应用取决于它适用的用例和数据集本身。过度取样和欠采样不足结合使用也会有很好的效果。
3.以正确的方式使用K-fold交叉验证
值得注意的是,使用过采样方法来解决不平衡问题时,应适当地应用交叉验证。切记,过采样会观察到稀有的样本,并根据分布函数自举生成新的随机数据。如果在过采样之后应用交叉验证,那么我们所做的就是将模型过度适应于特定的人工引导结果。这就是为什么在过采样数据之前应该始终进行交叉验证,就像实现特征选择一样。只有对数据进行重复采样,可以将随机性引入到数据集中,以确保不会出现过拟合问题。
4.组合不同的重采样数据集





