按
:
Facebook的AML和FAIR团队合作进行自然语言处理对自然语言理解进行着合作研究。Facebook向公众介绍了他们的研究进展、自然语言理解在Facebook产品中的应用,并且介绍了平民化的自然语言理解平台CLUE,希望依靠大家的力量,继续丰富自然语言理解的应用。
演讲者:Facebook工程主管Benoit Dumoulin,技术项目主管Aparna Lakshmiratan。AI科技评论听译。
(首先上台的是Benoit)大家好,我是Benoit,我是Facebook自然语言理解团队的负责人。

我们团队隶属于AML(applied machine learning,机器学习应用小组)。今天我想给大家讲讲几个我们团队最近的工作成果,讲讲我们正在研究什么,同时也会讲到我们遇到、并且正在努力解决的问题和挑战。等一下我还会请一个同事上台来介绍一个有意思的产品,其中就用到了我们团队开发的技术。

Facebook为什么需要自然语言理解?
进入正题,当你打开Facebook之后,你肯定会用到文字。文字是重要的沟通方式,Facebook的每个产品里面都能看到文字,Instagram,Messenger,Whatsapp等等,文字真的到处都是。而你每天在Facebook看到的或者写下的文字,是没有任何要求,任何人都可以随意发挥的,不需要戏剧化或者怎样。所以如果我们能够理解这些文字,那我们就肯定可以让每个用户的使用感受都得到提升。
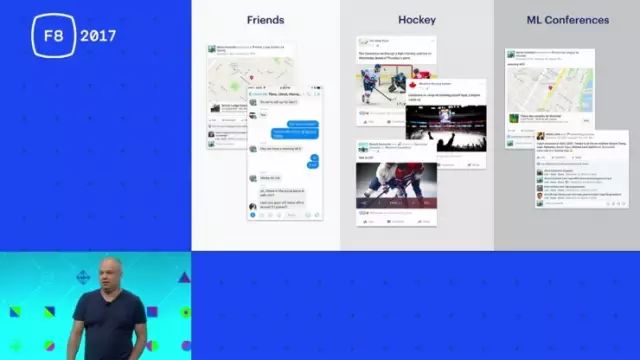
理由是这样的,拿我自己举例吧,其实我是法国裔加拿大人,在蒙特利尔长大的(观众喝彩),(笑)。那我呢,工作是科学家,业余时间喜欢冰球,所以当我每天打开Facebook的时候,我想看到我朋友们的新动向、想跟他们聊天;我也想知道最新的冰球比赛结果如何,你看现在就有一场,我挺关心我喜欢的俱乐部怎么样了——不告诉你们叫什么(笑)。同时呢,除了看这些新闻,我还需要关注机器学习方面的动向,我得知道下一场会议在什么时候、都有谁会去、我的朋友们去不去、是谁组织的、有没有什么优秀论文等等,各种各样的事情。为了达到这样的目的呢,我们就需要想办法理解这些文字内容,然后根据我的兴趣进行匹配。

我们经常提到“自然语言理解”和“内容识别”,要表达什么意思呢?简单说就是能给别人解释——一段文字经过算法处理以后,我们能够做出结论或者进行引申。在我们能做的事情里面,最基本的之一就是给文字分类。
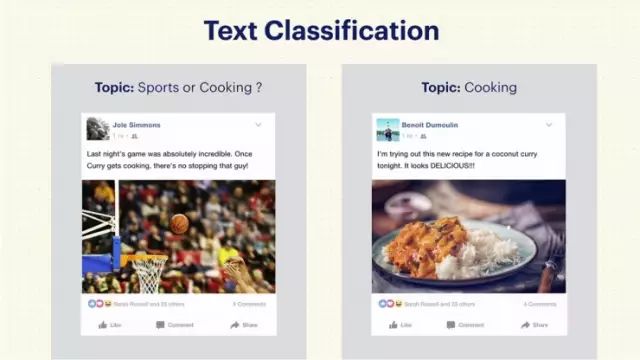
比如(右边)这段内容是我发的,把它输到机器里,就能训练它如何把内容分类成为话题,然后就能跟别人解释了,“哦,这段内容是关于厨艺的。” (左边)还有一段关于篮球的内容是我的朋友Jole发的,不过如果你仔细看一下文字的话,你就会发现它也是关于厨艺的,只是不那么明显。不过不用担心,我们训练的机器也可以处理这样的内容。

我们当然还能做更棒的,更深入地理解一段话,区分出其中的实体。这是另一个朋友的动态,要去看演出,这个乐队我没怎么听说过。当你仔细看一下文字部分就会发现,名字挺逗, 乐队名字是“Muckbucket Sunshine”,演出地点是“BOM BOM ROOM”。那如果这种时候我们能区分出实体,知道了是哪个乐队、在哪个场馆演出,然后就可以把它匹配给喜欢音乐的人;然后呢,我们不需要把所有音乐相关的信息都推荐给他们,只需要推荐跟这个乐队或者这个场馆相关的就可以了。我们所讲的“内容识别”大概就是这样。
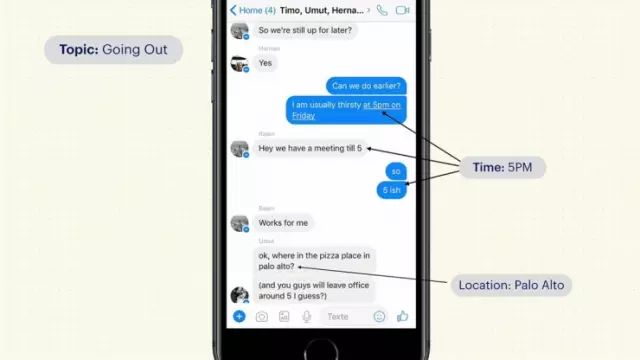
对于Messenger,你们在听过昨天的演讲、参加一些活动以后就会知道,一旦能够理解文字内容了,就可以做一些很有趣的事情。比如这段对话,我和我的两个朋友打算一起出去喝酒。区分一下实体的话,就是我们要去palo alto,时间也能看得出来。这里我想强调一下,人类可以很容易地理解这段对话,实际上我们3个人用了3种不同的方式来表达时间。
Facebook的目标和方法

所以我们的目标就是设计和训练人工智能,让它们对文字内容的理解准确度达到人类水平,确实是这样。这个目标其实挺难达到的,我试着跟你们解释一下,Facebook上面的文字完全是自由地书写的,没有任何限制,用户们想怎么写就怎么写,对不对。

我们打算怎样达到这个目标呢,不是什么秘密,我们用了深度学习的方法。我们最重要的方法之一是来自这篇论文的。它的名字叫《从零开始进行文本理解》(《Text understanding from scratch》),是几年前公开的,其中介绍了可以用深度学习,就是只需一个标准的网络模型就能进行语言识别,并且解决大多数在其中遇到的问题。我们跟Facebook的研究团队一起研究了这篇论文,然后我们就决定建立一个能够支持论文中这样的算法的平台。

这是我们在Facebook建的这个平台建好以后的样子,我们把它叫做Deep Text,是帮我们达成文本识别方面目标的秘密武器。我们把这个平台建立得可以灵活切换,还可以升级拓展。我们每天会拿很多文本给它训练或者处理。它需要支持多种语言,如果你参与了之前的演讲,你一定明白我们有很多用其它语言的用户,他们同样会用不同的语言创造很多内容,我们也需要理解。还有,这个方面有许许多多的问题需要解决,我们希望这个平台能够以无缝的方式解决许多种不同的问题。
我刚才解释过的内容分类、实体识别和区分只是众多待解决问题中的几个,我们还可以做很多别的事情。我等下还会说一个叫做“文本相似性”的,也是能够很自然地用这样的平台解决的。现在我们回过头来再讲一下Deep Text,看看它是怎么解决文本分类的问题的。

刚才说过Deep Text用到了深度学习,其中很有意思的一点就是单词是以向量的形式表示的。我们在向量空间里表示这些词,这样一来,语义学上相似的词也就会处在更接近的位置上;不怎么相似的词就会离得很远。这里是一张这种表示方法的示意图,里面的蓝色和粉色点就是单词。可以看到,几个球类运动的名称挨得比较近,其它概念性的词虽然也跟运动相关,但是离得就要远一些。

我们实际的措施,基本上是基于卷积网络的,这是一种很自然的吸收组合上下文的方法。这里的“上下文”是指,如果你单独拿一个词出来,它可能会有好多种含义,但是当这个词在句子中、有上下文的时候,那这个词的意思就会变得明确得多。这就是我们这种方法可以很自然地做到这件事的原因。基本上你也自己能做一个话题或者分类识别器,就用这样的网络。
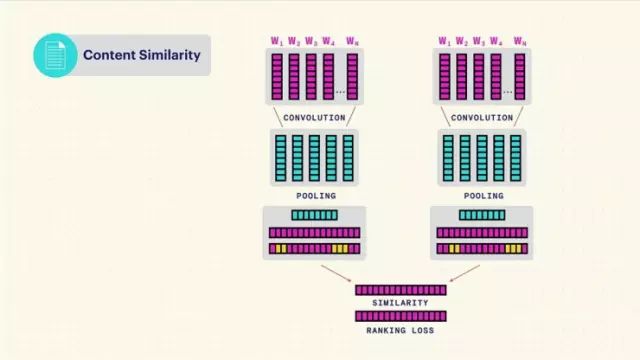
刚才我提到了文本相似性,它可以很好地说明我们这个平台的灵活性。关于文本相似性,我们就拿上一页的那种网络,然后把它拓展成了一个复杂得多的模型,像这样。在这里我们要做的是,用一侧的网络对一份文本内容进行分析建模,我们把这种模型叫做“双塔模型”,如果你是业内人士的话,你肯定明白我是什么意思。所以你用一侧的网络对一条文本进行建模,用另一侧的网络对另一条文本进行建模,然后再用一个函数对语义区别大的进行惩罚。
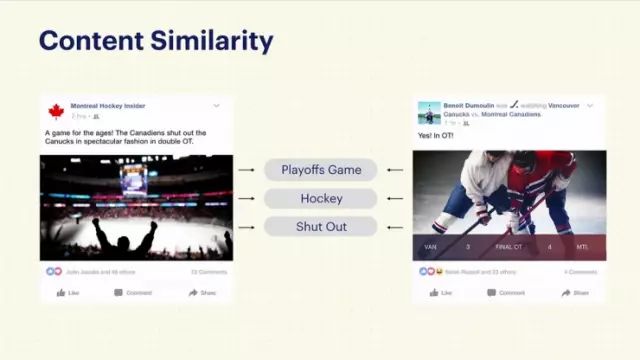
有了这样的方法,我们就可以做很厉害的事情了。比如这个,我不是喜欢冰球嘛,那么有了这样的模型,如果有一个我喜欢的动态,那这个模型就可以学会找到更多的语义类似的动态,然后我就可以看到更多自己喜欢的东西。这个模型挺厉害的,我们在很多Facebook的产品中都用到了这个模型。

这是我们当前所做的,对于未来,我们想要做得更好。这是我们在通往与人类类似的文本识别准确率路上的小目标之一,我们可以把文字和图片或者视频进行联合识别。还是回到我朋友Jole的这个动态,文字部分是很隐晦的,但是这张图片非常好理解。所以如果把两者加以结合,让图片和文字里面的信息都发挥作用,建立一个联合识别的模型,就肯定会对这份内容有很好的理解。

以上就是我们最近在做的事情,我们也一直努力做出更好的成果。那么我就讲到这里,下面我会邀请我的同事上台,她会继续给大家讲一些的实际产品,其中就用到了我们团队开发的技术。
(Benoit走下讲台,观众鼓掌,Aparna走上讲台)

谢谢Benoit,我是Aparna,我来跟大家讲讲目前Deep Text是如何运用在真实的Facebook产品中的。我不知道大家有没有想过,实际上人们会用Facebook的群组做各种各样的事情,尤其是用它来买卖东西。
自然语言理解已经在改善用户体验
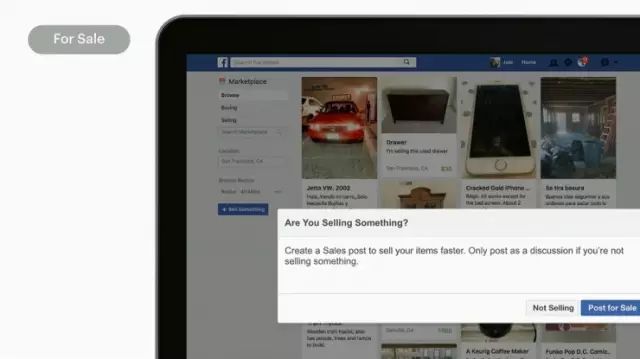
大概一年之前,群组的商务团队找到我们,让我们帮忙看看有没有办法知道一个动态是不是关于卖东西的;如果真的要卖东西,我们能不能帮用户更好地达成他的目标,来给用户更好的使用体验。这其中的难点是,当用户想要卖东西的时候,我们不想给用户发动态的方式加上任何束缚,我们还是希望用户用自然语言、自由地表达,但是我们还是要能够识别出用户想要卖东西的意愿。当我们有了Deep Text以后,我们就可以做一个高精确度的分类器,它可以阅读用户的动态,看看用户有没有卖东西的打算。而且它还可以识别得更深,就像刚才Benoit说的那样,识别文本中的实体,在这个场景下就可以是产品名称、价格、主要特性,然后我们就可以给用户提供很有吸引力的使用体验。
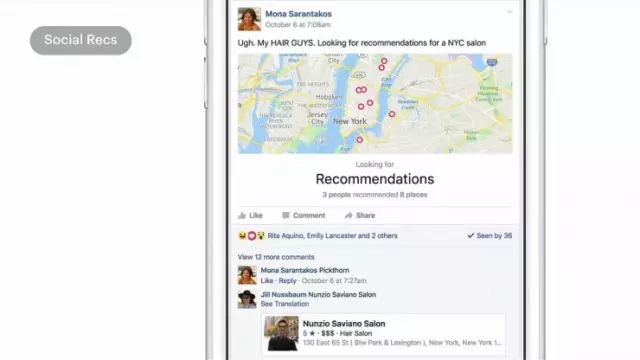
再举一个例子,社交推荐,我在自己的Facebook上都经常会使用这个功能。借助Deep Text,我们可以观察用户的动态,如果你在让你朋友帮忙推荐东西的,比如好吃的饭馆、好玩的活动,又比如这个例子里,想找一个靠谱的理发店。我们能做的就是,用Deep Text判断用户想要做什么样的事情,一旦判断出来,接下来的事情会给用户很棒的体验,当你的朋友给出建议以后,评论会分类,找出其中的实体,更重要的是把找到的实体链接到Facebook的地址簿里,然后展示成美观的地图,方便用户互动,最终达成自己的目标。
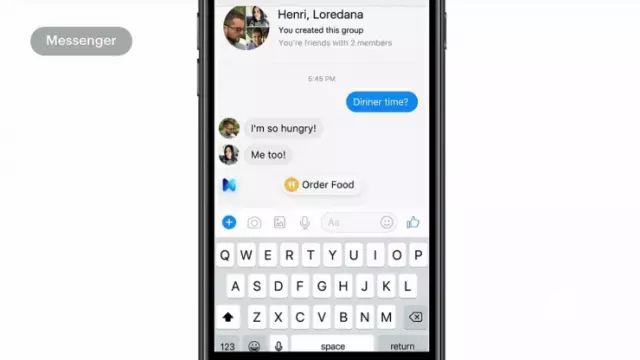 最后再说一个应用的话,你们可能在昨天的演讲里已经听过了,那就是Messenger中的M建议。当M觉得它能够帮助你做什么的时候,它就会自动在你的聊天中跳出来。它吸引人的地方,就是缩短了从“想做”到“做成”之间的距离。所以M可以帮忙做很多你想要做的事情。比如,当M发现你要去哪里的时候,它可以帮你叫一辆车,看你喜欢Uber还是lift,而且可以不用离开Messenger界面就叫到车。现在这段视频就演示了当M发现用户打算叫外卖,只要点一下,就可以用一种新的体验叫到外卖。
最后再说一个应用的话,你们可能在昨天的演讲里已经听过了,那就是Messenger中的M建议。当M觉得它能够帮助你做什么的时候,它就会自动在你的聊天中跳出来。它吸引人的地方,就是缩短了从“想做”到“做成”之间的距离。所以M可以帮忙做很多你想要做的事情。比如,当M发现你要去哪里的时候,它可以帮你叫一辆车,看你喜欢Uber还是lift,而且可以不用离开Messenger界面就叫到车。现在这段视频就演示了当M发现用户打算叫外卖,只要点一下,就可以用一种新的体验叫到外卖。
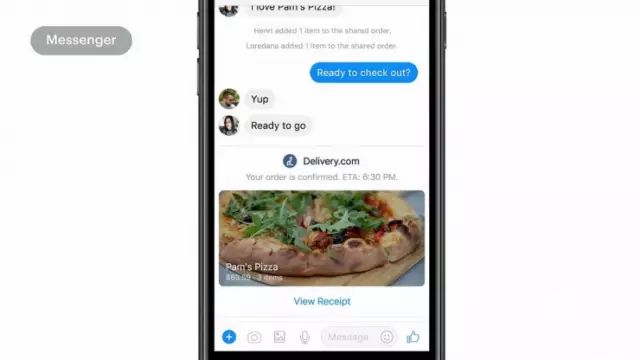
而且你还会发现这种体验是共享化的,对话里的每个人都可以参与这个点餐的过程。点好以后仍然通过M就可以完成付款。所以这些事情都可以不用离开Messenger界面就可以搞定,而随着M变得越来越智能,我们也希望有更多类似这样的建议可以给更多的用户意愿带来方便。
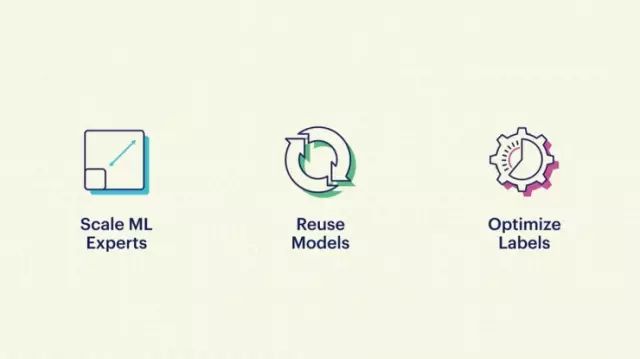
接下来我想讲讲,当我们在研发这些产品的时候都遇到了一些什么样的困难。
第一个困难是,很难批量复制机器学习所需要的专家。
大多数时候,我们团队的机器学习专家和产品团队的工程师一起合作,做出这些非常高准确度的分类器。但是你会注意到,在我提到的这些应用例子里,我们还想给很多很多别的用户意愿做出分类器,还有很多很多的实体我们想要识别提取,但是很明显,我们没办法像批量化建立功能一样地让机器专家们也批量化。
第二个问题是重复使用性,我们AML团队很看重这件事。
回想一下前面我举的两个例子,其中有一个提取地址的功能,我们会觉得这个功能既要用在Messenger的M建议功能里,也要用在社交推荐里是很自然的事情。所以我们也在想如何才能建立一个平台,让不同的程序都能共享和重复使用这个平台的模型、特性以及数据,这样它们就都可以找到突破口,避免开发的时候要每次重复做类似的工作。
第三个难点你们应该都理解,
机器学习的关键是数据,高质量的有标签数据;要获得这样的数据,大家可能都知道,不仅仅是难,而且还很费钱。所以我们也在想
如何优化标签,让我们在训练这些分类器和提取器的时候尽可能提高标签的使用效率。
介绍一个平台给你认识一下吧,它叫做CLUE

这几点就把我们引向了CLUE。CLUE是一个语言识别引擎,是一个自助式的平台。





