背景
阿里巴巴经过多年的技术演进,系统工具和架构已经高度垂直化,服务器规模也达到了比较大的体量。当服务规模大于10000台时,小概率的硬件故障每天都会发生。这时如果需要人的干预,系统就无法可靠的伸缩。为此每一层的系统都会面向失败做设计,对下游组件零信任,确保在故障发生时可以快速地发现和处理。
不过这些措施在故障发生时是否真的有效?恢复故障的工具是否实现了容灾?处理问题的人是否熟练?沟通机制是否有疏漏?容灾措施的影响是否会辐射到上一层?这些问题,平时没有太多的机会验证,只能在真实故障中暴露。
故障演练就在这个背景下诞生,沉淀通用的故障场景,以可控成本在线上将故障重现,以持续性的演练和回归方式的运营来暴露问题,不断验证和推动系统、工具、流程、人员能力的提升,从而提前发现并修复可避免的重大问题,同时通过演练的不断打磨达到缩短故障修复时长的目的。
一次生产环境故障复现的案例
2016年某日,某业务开始出现大量异常告警,影响持续若干分钟。原因是该业务依赖的一个持久化服务因为机器磁盘有问题(是一个驱动的bug),工作线程卡住了,但机器心跳线程正常,导致负载中心无法摘除异常机器,使得业务请求到这台机器的所有请求发生超时,从而造成业务下跌。
对于该问题的改进方案是,让持久化服务的工作线程来发送心跳,当工作线程异常的时候,不再发送心跳包,负载中心就可以把问题机器摘掉。此外,该持久化服务也重新梳理了相关的出错处理逻辑,以应对网络抖动的问题。
在B完成改进方案后,6月份技术人员在线上进行了第一次故障重现,模拟的故障场景就是磁盘无法读写。演练过程持续了62s,业务的RT稍有波动,不过业务没有下跌服务成功完成容灾。
虽然这次故障演练的场景非常简单,不过在故障治理的历史上将具有非常重要的意义,因为第一次在真实环境下实现了故障修复和验证的闭环。
故障画像分析和演练模型设计
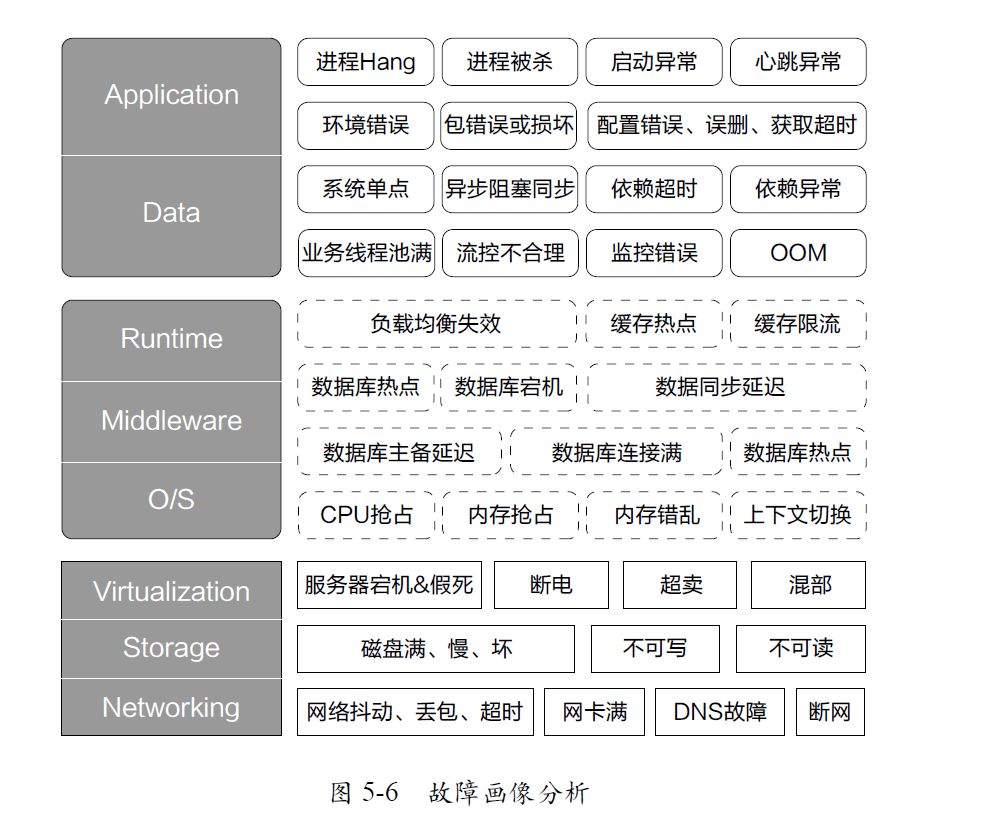
阿里巴巴因为其多元化的业务场景和日益复杂的技术架构,会遇到各式各样的故障,如果对故障整体做初步画像,故障整体可以分为IaaS层、PaaS层、SaaS层的故障(如图5-6所示)。
在真实的故障复现和演练中,我们需要一个高度抽象的模型。所以我们把故障模型又做了一次升级,并得到一些推论(如图5-7所示)如下。
(1)任何故障,一定是硬件如IaaS层,软件如PaaS或SaaS的故障。并且有个规律,硬件故障的现象,一定可以在软件故障现象上有所体现。
(2)故障一定隶属于单机或是分布式系统之一,分布式故障包含单机故障。对于单机或同机型的故障,以系统为视角,故障可能是当前进程内的故障,比如FullGC,CPU飙高;也可能是进程外的故障,比如其他进程突然抢占了内存,导致当前系统异常等。大多数时候,我们只关注故障对当前系统的影响,而不是真的需要外部产生故障。
同时,还可能有一类故障,可能是人为失误,或流程不适当导致,这部分不做重点讨论。

图5-7 故障演练模型
有了上面的推论,阿里巴巴内部设计了一套故障演练系统,把历史发生过的故障沉淀成通用化的模型记录到系统中,既可以对历史问题进行回放,也会对一些新应用进行定向化的演练,提前发现问题,推动问题修复和架构改造。
故障演练的一些实践
在2016年双11中,线上故障演练第一次成规模、有组织地开展起来。演练平台和演练经验在多个阿里子公司中复制和传播,故障工具也大幅度缩减了业务方演练的成本。有近十个BU参与,数百个演练场景设计,数十次大大小小的演习,发现并解决了大量的问题。故障演练主要应用在下面几个场景。
预案有效性:过去的预案测试的时候,线上没有问题,所以就算测试结果符合预期,也有可能是有意外但是现象被掩藏了。
监控报警:报警的有无、提示消息是否准确、报警实效是5分钟还是半小时、收报警的人是否转岗、手机是否欠费等,都是可以check的点。
故障复现:故障的后续Action是否真的有效,完成质量如何,只有真实重现和验证,才能完成闭环。发生过的故障也应该时常拉出来练练,看是否有劣化趋势。
架构容灾测试:主备切换、负载均衡,流量调度等为了容灾而存在的手段的时效和效果,容灾手段本身健壮性如何。
参数调优:限流的策略调优、报警的阈值、超时值设置等。
故障模型训练:有针对性的制造一些故障,给做故障定位的系统制造数据。
故障突袭、联合演练:通过蓝军、红军的方式锻炼队伍,以战养兵,提升DevOps能力。





