1.Imagination发布首款PowerVR Series8XT IP内核;
2.可用于自动驾驶的神经网络及深度学习;
3.Cadence发布业界首款面向汽车 监控 无人机等的神经网络DSP IP;
4.华虹宏力与华大九天再联手 国产EDA工具助力IP设计;
5.ARM 发表 Mali-C71 影像讯号处理器
集微网推出集成电路微信公共号:“天天IC”,重大新闻即时发布,天天IC、天天集微网,积微成著!点击文章末端“
阅读原文
”或长按 laoyaoic 复制微信公共号搜索添加关注。
1.Imagination发布首款PowerVR Series8XT IP内核;
可为智能手机、AR/VR头戴设备及汽车融合产品带来功能强大、令人惊艳的SoC性能

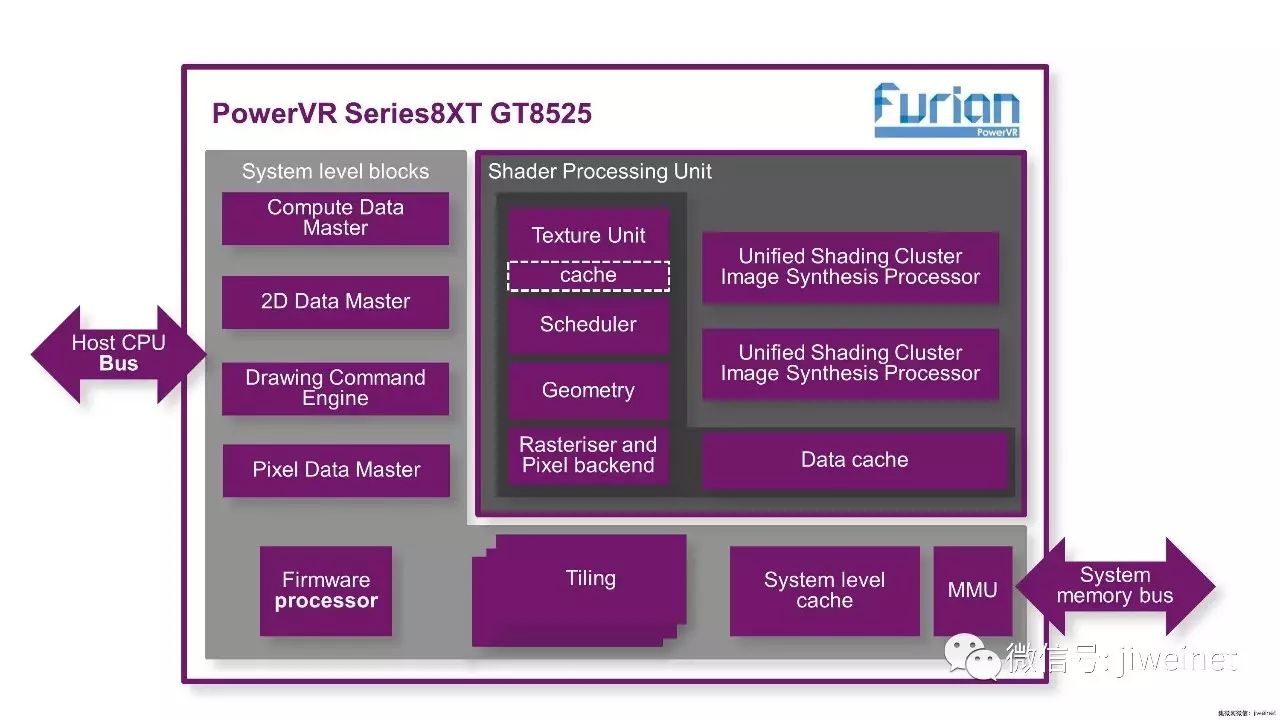
集微网消息,2017年5月11日 ─Imagination Technologies 发布第一款以其最新的PowerVR Furian架构为基础的GPU IP内核 ─ Series8XT GT8525。Furian专为推动新一代的消费性设备所设计,能以移动功耗的预算提供长时间的高解析度、沉浸式图形内容以及数据运算功能。双集簇(two-cluster)GT8525可提供同类领先的性能、功耗与面积,以及独特的特性,以协助客户设计出适用于高端智能手机与平板电脑、中端专用型VR与AR设备、以及中级到高级的车用信息娱乐与ADAS系统等产品的SoC。
Imagination公司PowerVR产品及技术营销高级总监Chris Longstaff表示: “新款GT8525是Series8XT GPU系列产品的首个成员,采用我们具备优异效率与扩展性的Furian架构。此IP内核是为满足多种大量应用的市场需求而推出的。它持续并强化了PowerVR XT系列产品的每微瓦性能(performance/mW)领先地位,并且能支持非常丰富的特性组合。”
JPR Research总经理Jon Peddie表示:“Imagination在高端移动市场拥有强有力的业界实绩,Furian架构将能进一步强化其技术领导地位。凭借GT8525的推出,Imagination可为标准型移动GPU树立新的性能指标,并通过分块延迟渲染(TBDR)技术持续提供优异的功耗效率。”
ELVEES研发中心首席技术官Tatiana Solokhina表示:“做为多样化全球视频分析应用的SoC供应商,我们需要GPU能以有限的功耗提供最佳的运算性能。Imagination推出的新款PowerVR Furian 8XT产品可为我们提供业界领先的GPU,并具备新的ALU可实现更高的性能密度与效率。此外,它能支持OpenVX这类标准运算API,能够轻松创建真实世界的视觉处理应用。”
满足下一代的应用需求
Furian架构是专为满足下一代消费性设备不断演进的图形与运算需求所设计:
•
智能手机:GT8525可满足游戏应用所需的以有限的功耗预算持续提升稳定性能的要求,包括移动VR应用。它还能开启需要更多运算可用性(compute availability)的新型移动使用案例,例如利用神经网络(包括CNN)进行物体辨认。
•
汽车:GT8525大幅提升了运算效率并内置硬件虚拟化功能,可应对在同一SoC上将信息娱乐、电子仪表盘以及部分ADAS功能结合在一起的趋势。OEM厂商能将同步的功能与服务予以隔离,以确保更高的安全性,并节省宝贵的芯片面积。
•
AR/VR:GT8525可提供高解析度与稳定的高频率图形功能,以符合独立式AR/VR头戴设备所需的绝佳用户体验。GT8525包括特别设计的硬件与软件,可将关键的移动时间延迟(motion-to-photon latency)降至最低。通过采用内置GT8525的芯片,OEM厂商能以更小的面积提供更高性能的图形与运算功能。开发人员能发挥OpenVX* API在PowerVR上执行的强大功能,实现快速的应用程序开发。
PowerVR Series8XT GT8525的性能数据
Furian架构是专为增强性能与功耗效率所设计,每微瓦性能远优于竞争的解决方案。与Series7XT GT7200 GPU相比,GT8525可达到:
•
针对Manhattan基准测试,这是移动与其他应用的业界标准测试,可提升超过50%的fps,以及提升80%的TRex
•
针对Antutu基准测试,这是另一项重要的基准测试,可提升超过50%的fps
•
2倍的PPC数据处理能力(每周期像素为8,GT7200为4),可实现更高的解析度与额外的性能,以支持先前受限于填充率不够的使用案例
•
提升超过50%的GFLOP,以及更多的可用GFLOP,能够更轻松地充分发挥内核的图形与运算功能
Furian架构的差异性优势
GT8525是以Furian架构为基础,此架构提升了性能、GPU效率与系统效率,能满足下一代应用所需的较低功耗与更佳的使用者体验。它采用了多项使PowerVR得以建立技术领先地位的优异特性,包括Imagination的分块延迟渲染(TBDR)技术,它已在PowerVR GPU几代产品上获得证明,可提供最高效率的嵌入式图形功能。
Furian还采用新的32宽(32-wide)ALU集簇设计,以提升性能与效率。在主要与次要的ALU管线中使用的新增指令集架构(ISA)可实现更佳的资源利用率与效率,而多线程的最佳化设计能使内嵌于芯片上的局部运算内存读取更具效率与灵活度。Furian是专为满足多种应用与市场日益提升的运算需求所设计,能够高效率地使用多种运算API,包括OpenCL® 2.0、Vulkan® 1.0和OpenVX 1.1*等。
供应情况
GT8525已提供给早期客户使用;即日起开始提供授权。更多信息,请联系[email protected]。
关于 PowerVR GPU
PowerVR 图形处理器 (GPU) 产品在技术性能、产品路径以及生态系统方面均是市场的领导者,已为移动与嵌入式GPU树立了业界标准。凭借先进且独特的架构,PowerVR 成为领先的图形技术。运用块状延迟渲染 (TBDR) 技术,PowerVR 的效率可确保最低的带宽使用以及单位任务的最低处理周期,因而可实现优异的性能效率以及单位架构的最低功耗,表现优于其他的解决方案。通过采用内置PowerVR 技术的芯片,OEM 厂商可将此优势带到其产品中,以提供最杰出的视觉体验以及最长的电池寿命。
2.可用于自动驾驶的神经网络及深度学习;
来源:集微网 作者:CEVA 汽车市场营销主管 Jeff VanWashenova
高级辅助驾驶系统 (ADAS) 可提供解决方案,用以满足驾乘人员对道路安全及出行体验的更高要求。诸如车道偏离警告、自动刹车及泊车辅助等系统广泛应用于当前的车型,甚至是功能更为强大的车道保持、塞车辅助及自适应巡航控制等系统的配套使用也让未来的全自动驾驶车辆成为现实。
如今,车辆的很多系统使用的都是机器视觉。机器视觉采用传统信号处理技术来检测识别物体。对于正热衷于进一步提高拓展 ADAS 功能的汽车制造业而言,深度学习神经网络开辟了令人兴奋的研究途径。为了实现从诸如高速公路全程自动驾驶仪的短时辅助模式到专职无人驾驶旅行的自动驾驶,汽车制造业一直在寻求让响应速度更快、识别准确度更高的方法,而深度学习技术无疑为其指明了道路。
以知名品牌为首的汽车制造业正在深度学习神经网络技术上进行投资,并向先进的计算企业、硅谷等技术引擎及学术界看齐。在中国,百度一直在此技术上保持领先。百度计划在 2019 年将全自动汽车投入商用,并加大全自动汽车的批量生产力度,使其在 2021 年可广泛投入使用。汽车制造业及技术领军者之间的密切合作是嵌入式系统神经网络发展的催化剂。这类神经网络需要满足汽车应用环境对系统大小、成本及功耗的要求。
轻型嵌入式神经网络
卷积式神经网络 (CNN) 的应用可分为三个阶段:训练、转化及 CNN 在生产就绪解决方案中的执行。要想获得一个高性价比、针对大规模车辆应用的高效结果,必须在每阶段使用最为有利的系统。
训练往往在线下通过基于 CPU 的系统、图形处理器 (GPU) 或现场可编程门阵列 (FPGA) 来完成。由于计算功能强大且设计人员对其很熟悉,这些是用于神经网络训练的最为理想的系统。
在训练阶段,开发商利用诸如 Caffe 等的框架对 CNN 进行训练及优化。参考图像数据库用于确定网络中神经元的最佳权重参数。训练结束即可采用传统方法在 CPU、GPU 或 FPGA 上生成网络及原型,尤其是执行浮点运算以确保最高的精确度。
作为一种车载使用解决方案,这种方法有一些明显的缺点。运算效率低及成本高使其无法在大批量量产系统中使用。
CEVA 已经推出了另一种解决方案。这种解决方案可降低浮点运算的工作负荷,并在汽车应用可接受的功耗水平上获得实时的处理性能表现。随着全自动驾驶所需的计算技术的进一步发展,对关键功能进行加速的策略才能保证这些系统得到广泛应用。
利用被称为 CDNN 的框架对网络生成策略进行改进。经过改进的策略采用在高功耗浮点计算平台上(利用诸如 Caffe 的传统网络生成器)开发的受训网络结构和权重,并将其转化为基于定点运算,结构紧凑的轻型的定制网络模型。接下来,此模型会在一个基于专门优化的成像和视觉 DSP 芯片的低功耗嵌入式平台上运行。图 1 显示了轻型嵌入式神经网络的生成过程。与原始网络相比,这种技术可在当今量产型车辆的有限功率预算下带来高性能的神经处理表现,而图像识别精确度降低不到 1%。
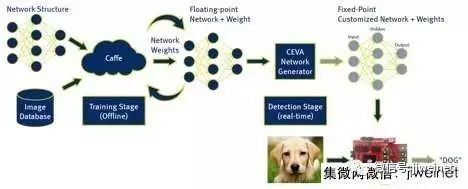
图 1. CDNN 将通过传统方法生成的网络权重转化为一个定点网络
一个由低功耗嵌入式平台托管的输入大小为 224x224、卷积过滤器分别为 11x11、5x5 及 3x3 的 24 层卷积神经网络, 其性能表现几乎是一个在典型的 GPU/CPU 综合处理引擎上运行的类似 CNN 的三倍,尽管其所需的内存带宽只是后者的五分之一且功耗大幅降低。
下一代深度学习神经网络
汽车制造业进入神经网络领域所习得的经验不断推动技术的发展,并因此开发出了更先进的网络架构及更复杂的拓扑,如每级多层拓扑、多入/多出及全卷积网络。新推出的重要网络类型不仅可用来识别物体,也可用来识别场景,从而提供用以解决汽车领域应用程序(如自动驾驶功能)所需的图像分割。当然,中国 40 家左右的汽车制造商并不会在此道路上踽踽独行。他们会与百度等技术公司进行密切合作。技术公司是这些网络和架构发展的核心。CNN 网络生成器功能的完善也为新的网络架构和拓扑提供了支持,如 SegNet 及 GoogLeNet 与 ResNet 等其它网络结构以及高级网络层(图 2)。此外,一键启用也让预训网络转换成优化的实时网络执行更为便捷。为确保给常用的网络生成器提供支持,CDNN 框架与 Caffe 和 TensorFlow (谷歌的机器学习软件库)都有合作。
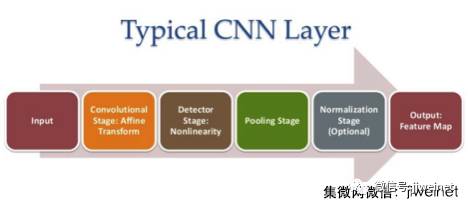
图 2网络生成器的发展为新网络层及更深的架构提供了支持
由于最新推出的嵌入式处理平台在可扩展性及灵活性上都有了很大改进,因此嵌入式部署也可以利用这些改进来完善自身。由于深度学习领域的发展越来越多样化,因此拥有一个不仅能满足当今处理需求,也具有适应未来的技术创新的灵活架构非常重要。
铺好路
第一批神经网络应用程序将专注于视觉处理,以支持诸如自动行人、交通信号或道路特征识别等功能。由于这些系统的性能不断改进,例如处理越来越大的来自高分辨率相机的数据集,因此神经网络也有望在未来的汽车中发挥更大的作用。这些作用将包括承担系统中其它复杂的信号处理任务,例如雷达模块及语音识别系统。
随着神经网络首次应用于车载自动驾驶系统,(据报道,某些国家将在 2019-2020 年型的新车辆中使用神经网络,)对同时兼具安全性及可靠性的系统的需求会越来越大。中国政府计划在 2021 至 2025 年推出自动驾驶车辆。要让此类系统具备可让客户使用的条件,汽车制造商必须同时确保其符合相关的安全标准,如 ISO 26262 功能安全性。这需要硬件、软件及系统的综合发展。
由于这些系统变得越来越复杂,因此确保系统可靠安全且能满足处理需求也成为汽车制造商所面临的越来越大的挑战。
结论
机器学习神经网络将沿着一条挑战高效处理性能的发展道路继续阔步前进。先进的神经网络架构已经显现出优于人类的识别精确性。用于生成网络的最新框架,如 CDNN2,正在推动轻型、低功耗嵌入式神经网络的发展。这种神经网络将使目前的高级辅助驾驶系统具有较高的精确性及实时处理能力。
深度学习神经网络在量产型车辆上的首次使用将限于基本的视觉识别系统,但最终会在未来为自动化程度越来越高的车辆提供支持,帮助其应对众多的复杂信号处理的挑战。
3.Cadence发布业界首款面向汽车 监控 无人机等的神经网络DSP IP;
内容提要:
•
完整独立的DSP核心,全面支持各级神经网络层
•










