来源:uee.me/cFyW6
问题:
通常我会这么定义列表:
List names = new ArrayList<>();
names类型使用List接口,那么具体实现该如何选择。
什么时候应该用LinkedList替代ArrayList,反之亦然?
总结:
大多数情况下,相比LinkedList更推荐使用ArrayList或ArrayDeque。
如果不确定,可以直接选用ArrayList。
LinkedList和ArrayList是List接口的两种不同实现。
LinkedList采用双向链表实现。
ArrayList通过动态调整数组大小实现。
与标准链表和数组操作一样,不同的实现方法算法运行时也不同。
对于LinkedList
-
get(int index)复杂度为O(n)(平均步长n/4)
-
add(E element)复杂度为O(1)
-
add(int index, E element)复杂度为O(n)(平均步长n/4)。
但是当index = 0时复杂度为O(1)的主要优点。
-
remove(int index)复杂度为O(n)(平均步长n/4)
-
Iterator.remove()复杂度为O(1)。
的主要优点
-
ListIterator.add(E element)复杂度为O(1)。
这是LinkedList
的一个主要优点。
注意:
许多操作平均需要n/4步长,最好的情况下(例如index= 0)步长为常数,最坏的情况下需要n/2步(列表中间)。
对于ArrayList
-
get(int index)复杂度为O(1)的主要优点
-
add(E element)分摊后的复杂度为O(1),但最坏的情况是O(n),因为需要调整数组大小并进行拷贝
-
add(int index,E element)复杂度为O(n)(平均步长n/2)
-
remove(int index)复杂度为O(n)(平均步长n/2)
-
Iterator.remove()复杂度为O(n)(平均步长n/2)
-
ListIterator.add(E element)复杂度为O(n)(平均步长n/2)
注意:
许多操作要求平均步长为n/2,最好情况下(列表末尾)步长为常数,最坏情况下(列表开始)需要n步
LinkedList
可以使用iterator实现固定时间插入或删除,但只能顺序访问元素。
换句话说,可以向前或向后遍历列表,但是在列表中查找固定位置元素花费的时间与列表大小成正比。
Javadoc中这么写道:
“在列表中建立索引,会从列头或列尾开始遍历,从更靠近的位置开始”,这些方法平均复杂度为O(n)(平均步长n/4),尽管index = 0时复杂度为O(1)。
另一方面,ArrayList
支持快速随机读取访问,因此获取任何元素都能在恒定时间内完成。
但是,除了列尾在其它任何位置添加或删除元素,都需要把后面的所有元素移位。
同样,如果添加的元素多于底层数组的容量,则会分配一个新数组(大小是之前的1.5倍),并把旧数组复制到新数组中。
因此在ArrayList中添加元素时间复杂度最差为O(n),平均情况下为常数。
因此,根据您打算执行的操作选择对应的实现。
遍历这两种List开销都很小。
(从技术上看ArrayList更快,但除非确实对性能要求十分敏感,否则不必担心。
遍历的复杂度都是常量)
使用LinkedList其中一个好处可以重用已有iterator插入和删除元素。
然后修改本地列表即可,操作的时间复杂度为O(1)。
在ArrayList中,数组余下的部分需要移动(即拷贝)。
而在LinkedList中执行seek操作遍历,最坏时间复杂度为O(n)(平均步长n/2),而ArrayList中,可以直接计算位置进行访问,复杂度为O(1)。
在LinkedList列头增加或删除操作时间复杂度为O(1),而ArrayList需要O(n)。
请注意:
ArrayDeque可以用来替代LinkedList,适合在列头添加和删除元素,但它不是List。
另外,如果列表很大,请记住,内存使用情况也有所不同。
每个LinkedList元素都有额外开销,因为里面还存储了指向下一个和上一个元素的指针。
ArrayLists没有这种开销。
但是,无论是否实际添加了元素,ArrayList都会分配初始容量大小的内存。
ArrayList默认初始容量很小(Java 1.4-1.8中设为10)。
但是由于底层实现是数组,因此如果添加很多元素,则必须调整数组大小。
如果提前知道需要添加很多元素,为避免调整数组大小带来的开销,在创建ArrayList时需要设置更大的初始容量。
答案2(案例分析):
现代计算机体系结构中,ArrayList性能几乎在所有情况下都得到大大提升。
因此,除非一些非常独特和极端的情况,应避免使用LinkedList。
从理论上讲,LinkedList的add(E element)时间复杂度为O(1)。
同样,在列表中间添加元素应该非常有效。
实际并非如此,因为LinkedList是一种对缓存不友好的数据结构。
从性能的角度看,只有在极少数情况下,LinkedList的性能会优于缓存友好的ArrayList。
下面是在随机位置插入元素的基准测试结果。
就像你看到的那样:
ArrayList的效率要高得多。
尽管从理论上讲,每次向列表中插入元素都需要“移动”数组中后续n个后元素(个数越少越好):
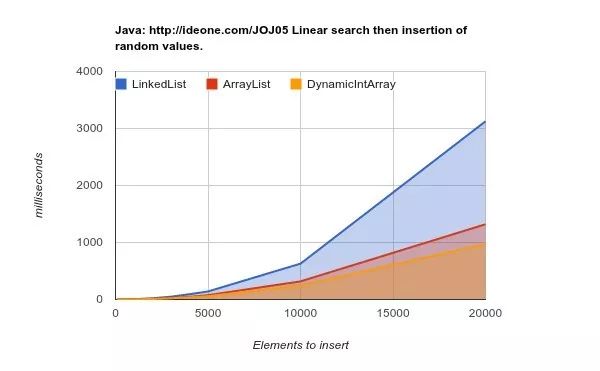
在缓存更大、速度更快的下一代硬件上运行,得出的结论更明确:
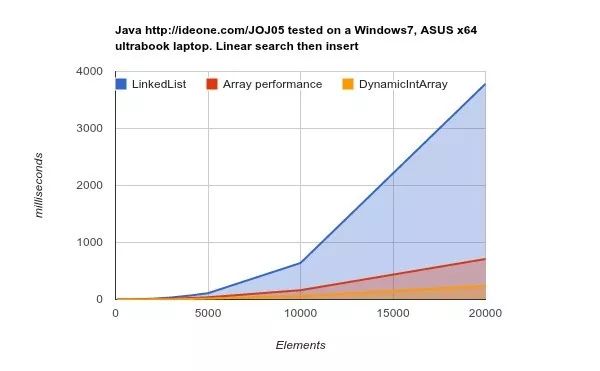
LinkedList完成相同工作所需的时间更长。
有两个主要原因:
-
主要原因
:
LinkedList
节点随机分布在整个内存中。
RAM(“随机访问存储器”)并不是真正随机,需要获取内存块进行缓存。
这个操作非常耗时,并且当这种操作频繁发生时,需要一直替换缓存中的内存页 -> 缓存未命中 -> 缓存效率低下。
ArrayList元素存储在连续内存中,这正是现代CPU架构优化的内容。
-
其次
,
LinkedList
需要保留指向前一个与后一个元素的指针,这意味着每个元素的内存消耗是ArrayList的3倍。
DynamicIntArray是一个自定义ArrayList实现,元素类型为Int(原始类型)而非Object。
因此所有数据实际上都是相邻存储,因此效率更高。
记住一个关键因素,获取存储块比访问单个存储单元的开销更大。
这就是为什么读取器1MB顺序内存要比从不同内存块中读取同样的数据量快400倍的原因:
延迟数据比较(〜2012)
----------------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 3,000 ns 3 us
Send 1K bytes over 1 Gbps network 10,000 ns 10 us
Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1









