
图源:
unsplash
原文来源
:stanford
作者:Cody Coleman、Deepak Narayanan、Daniel Kang、Tian Zhao、Jian Zhang、Luigi Nardi、Peter Bailis、Kunle Olukotun、Chris Ré、Matei Zaharia
「雷克世界」编译:嗯~是阿童木呀、KABUDA、EVA
导语:一直以来,计算时间和成本是构建深度模型的关键资源,但现有的许多基准只关注模型的精确度。最近,斯坦福大学提出了Dawnbench,它是一种用于端到端深度学习训练和推理的基准套件,它提供了一组常见的深度学习工作负载,用于在不同的优化策略、模型架构、软件框架、云和硬件上量化训练时间、训练成本、推理延迟和推理成本。
在人工智能技术领域的研究中,尽管研究人员对系统、算法和硬件进行了大量的研究,以加速深度学习的工作负载,但是却没有标准的方法以评估端到端深度学习(end-to-end deep learning)性能。现有的基准对代理服务器度量指标进行测量,比如处理一个小批量数据的时间,但这些指标无法表明该系统作为一个整体是否会产生高质量的结果。在本研究中,我们引入了DAWNBench,这是一种基准和竞争套件,聚焦于测试为了达到最先进的精确度所需的端到端训练时间,以及达到该精确度所需的推理时间。以达到一定精确度所需的时间作为目标度量指标,我们探索了不同的优化,包括优化器的选择、随机深度和多GPU训练,是如何影响端到端训练性能的。我们的结果表明,优化可以在联合使用时以非凡的方式进行交互,从而产生更低的加速和更不精确的模型。我们认为,DAWNBench 将为评估深度学习系统中的许多折衷权衡提供一种有用的、可重现的方法。
深度学习方法是有效的,但计算成本很高,这导致需要大量的工作来优化其计算性能。研究人员提出了新的软件系统、训练算法、通信方法和硬件以降低该成本。然而,尽管取得了这些显著的进展,但由于缺乏标准的评估标准,难以衡量或比较这些结果的效用。大多数现有的深度学习性能基准仅仅测量代理服务器度量指标,例如处理一个小批量数据的时间。实际上,深度学习性能要复杂得多。在一些设置中,诸如使用更大的批量大小、降低精度和异步更新等技术会使算法无法收敛到一个好的结果,或者需要增加时间来完成。此外,这些方法以非凡的方式进行交互,可能需要更新基础优化算法,从而进一步影响端到端性能。
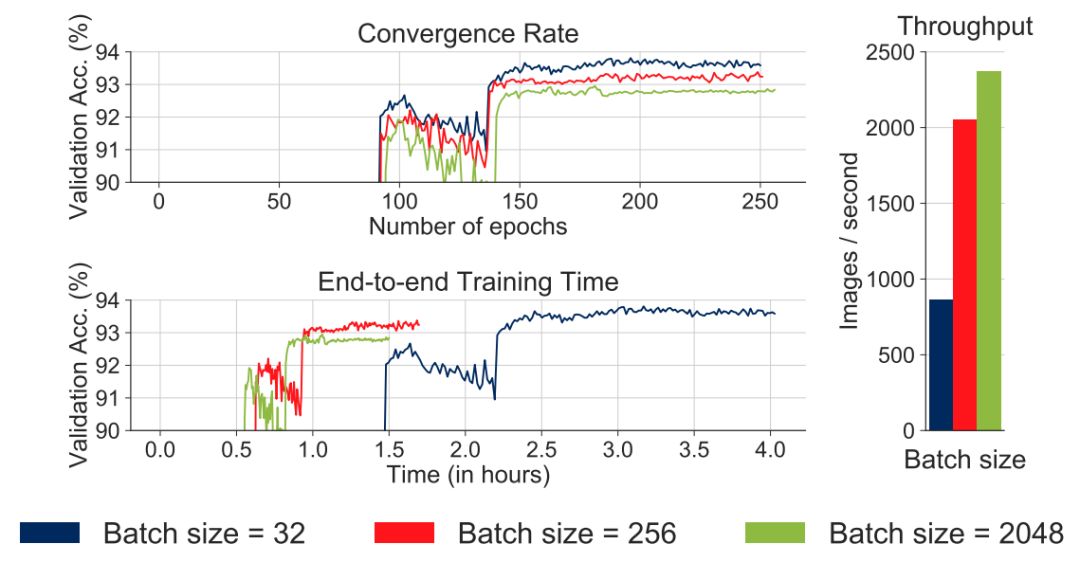
图1:小批量(Minibatch)大小对P100上ResNet56 CIFAR10模型的收敛速度、吞吐量和端到端训练时间的所带来的影响。学习率按照每次实验进行调整
缺乏标准的评估标准会导致一系列不太容易理解的折折衷权衡。例如,最小努力反向传播(Minimal effort back propagation)比MNIST上的反向传播速度提高了3.1倍。而使用8位精度使MNIST上的速度提高了3倍。那么将最小努力反向传播与8位精度相结合,能否达到一个9.3倍的速度提升?为了在7分钟内训练一个ImageNet模型,这种速度是否会转化为像ImageNet这种数据集上的更大的模型,与精确的、大型的小批量SGD相结合呢?目前,这些问题只能通过繁琐而耗时的实验来回答。此外,在评估新优化方法的效率时,应该依靠哪些先前的技术?
为了提供一种量化端到端深度学习性能的客观方法,我们引入了DAWNBench,这是一个开放的用于端到端深度学习训练和推理的基准测试和竞争套件。DAWNBench不是简单地测量每次迭代或吞吐量的时间,而是在指定的精度级别上测量了训练(例如,时间、成本)和推理(例如,延迟、成本)的端到端性能表现。这为计算框架、硬件、优化算法、超参数设置,以及其他影响实际性能的因素之间差异的归一化提供了客观方法。我们最初发布的DAWNBench提供了端到端的学习和推理任务,包括CIFAR10和ImageNet中的图像分类,SQUAD中的问题回答以及每个任务中的推理实现。
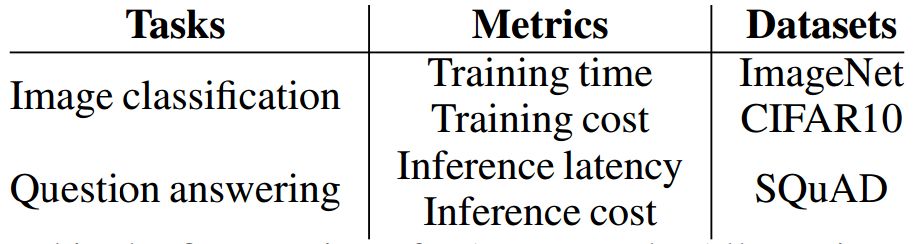
表1:在第一版DAWNBench中度评估得到的维度。所有指标都接近于最先进的精确度
在本文中,我们将介绍DAWNBench的基准规范和目标,并说明我们该如何使用DAWNBench来执行简单的性能研究,以评估优化器选择、批量大小、多GPU训练和随机深度所带来的影响。随着时间的推移以及社区的投入,我们计划扩大DAWNBench的范畴,使其能够包含附加的基准任务(例如分割、机器翻译、视频分类)和度量(例如能量,样本复杂度)。
基准概述和目标
DAWNBench使用多个数据集,基于多个指标在不同任务上对深度学习系统进行评估。基准测试使得系统能够在软件、算法、通信方法等方面进行创新。仅通过指定任务,DAWNBench还允许对新的模型架构和硬件进行试验。在最初的版本中,我们为两项任务提供了种子条目:CIFAR10和ImageNet上的图像分类以及SQUAD上的问题回答,并评估了四个度量指标:达到特定验证准确度的训练时间、使用公共云实例达到特定验证准确度的训练成本(以美元为单位)、对单个项目(图像或问题)执行推理时的平均延迟时间,以及10,000个项目中的平均推理成本(见表1)。我们还提供参考实现和种子条目,这是在两个通用的深度学习框架——PyTorch和TensorFlow中实施的。这些参考实现是从Github的官方存储中进行收集和改编的,并且与原始研究论文中所提供的精确度数据相一致,同时也符合这些框架中所发布的各种性能建议。
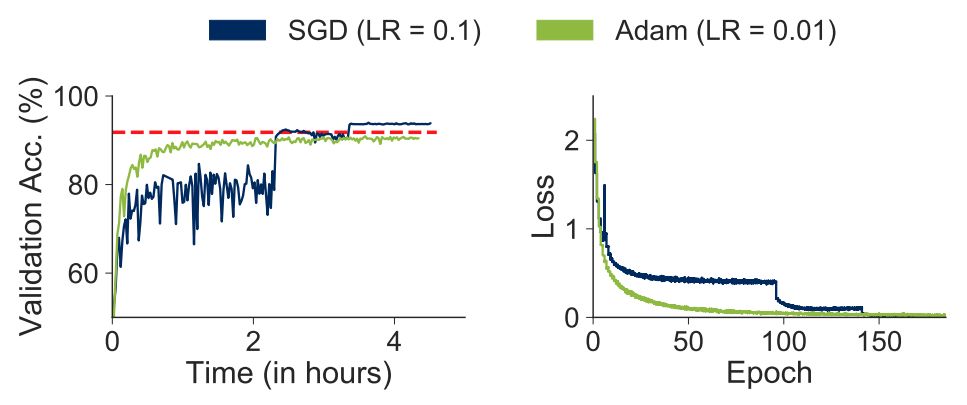
图2:当在CIFAR10上训练ResNet56模型时,不同优化器所带来的影响
在标准任务上,DAWNBench不是第一个比较和评估深度学习系统的基准,在此之前还有百度DeepBench、Fathom和TensorFlow Benchmark等。但我们的基准在两个关键方面与之有所不同。首先,DAWNBench关注端到端性能。以往的很多基准大都采集将在单个小批量数据上进行训练所需的时间作为关键指标,而忽视了经过训练后模型结果的精准度。另一些基准的侧重点则在于,对深度学习计算中使用到的单个低级操作(例如:卷积、矩阵乘法)进行计时。与这些基准不同,DAWNBench在确保测量达到预期精准度所需时间的同时,兼顾了硬件和统计性能。
其次,我们认为DAWNBench是开放和不断发展的。以往的基准通常是使用固定的模型架构和任务,在时间的快照上进行定义的。然而,深度学习的不断发展使得这种体系架构很快失效。例如,在近期,使用循环层进行的机器翻译方法,很快就被使用卷积层和注意力层的机器翻译方法所取代。机器学习是一个快速发展的领域,因此基准需要不断完善,以与之相适应。我们希望能够不断发展和完善DAWNBench,并围绕这一领域的进展进行探索(包括新任务),搭建沟通和交流的社区。
DAWNBench是一种衡量基准,可用于测量训练一个具有最高精确度的模型所需的端到端时间。通过聚焦于达到特定精准度的时间,我们展示了不同优化方式之间的相互作用,通过将不同的优化方式结合使用,可以有效防止模型收敛或训练时间的延长。用这一方式对深度学习系统进行推理,能够揭示出训练时间、训练成本、推算时间有价值的折衷权衡。我们希望能够让DAWNBench同新任务和新目标保持同步,以促进围绕深度学习系统的进展展开沟通与交流。
原文链接:
http://dawn.cs.stanford.edu/benchmark/papers/nips17-dawnbench.pdf
欢迎个人分享,媒体转载请后台回复「转载」获得授权,微信搜索「raicworld」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超260家成员共推AI发展,相关动态:
中新网:
中国人工智能产业创新联盟成立
ChinaDaily:
China forms 1st AI alliance





