一年前,一只阿尔法狗横空出世,它在学习了几百万册人类棋谱后,以4-1打败了人类世界的围棋冠军李世石,震惊世界,由此引发了一系列对于人工智能的讨论。
最近,它的弟弟阿尔法元再一次刷新人们的认知,没看过一本棋谱,自学成才,3天时间,它就以100:0的成绩战胜了哥哥,刷新围棋领域的排名!
伦敦时间10月18日18:00,研究团队
DeepMind再次在
《自然》(Nature)杂志上发表了一篇关于AlphaGo的文章,称新一代AI程序AlphaGo Zero(阿尔法元)在没有任何人类输入的情况下,可以自学成才。

旧版AlphaGo在今年5月战胜柯洁后宣布退役,但DeepMind公司仍在继续研究AlphaGo系列产品,此次发表的论文就是为了推出迄今为止的最强版AlphaGo,代号AlphaGo Zero。
这只新的阿尔法狗不简单,它在完全没有人类帮助的情况下,自学成才。而且,从“一张白纸”到“顶级高手”,它只需要短短3天时间!
在某种意义上可以说,
人类把阿尔法狗教坏了!
它再也不需要人类的“教育和帮助”了。
戳视频,看看Zero到底厉害在哪里。
不使用人类的围棋数据,AlphaGo Zero是如何实现自学的呢?
那就要先说说Zero与“旧狗”有哪些不同。
旧版Alpha Go需要先学习数百万份人类棋谱,还要经过几个月的密集训练,从而进行自我训练,实现超越。
新版Zero却能够“无师自通”
,完全不需要任何历史棋谱的指引,也不需要人类的任何先验知识,完全靠自己的强化学习(reinforcement learning)
。

研究团队事先没有给Zero学习任何人类棋谱,只告诉它围棋的规则,就让它自己
在棋盘上下棋,与自己进行对弈,从一次次试验和失败中吸取经验教训,摸索规律,在实战中提高棋艺。
另外,
Zero使用了单一的神经网络
。
此前版本的AlphaGo都是用了两种神经网络,一种用来预测下一步棋最好的走法,另一种用来计算,根据这些走法,谁更有可能获胜。
而Zero把这两种网络合二为一,只让神经网络预测获胜者,
从而能够得到更高效的训练和评估,就好像让一个围棋高手来预测比赛结果一样。
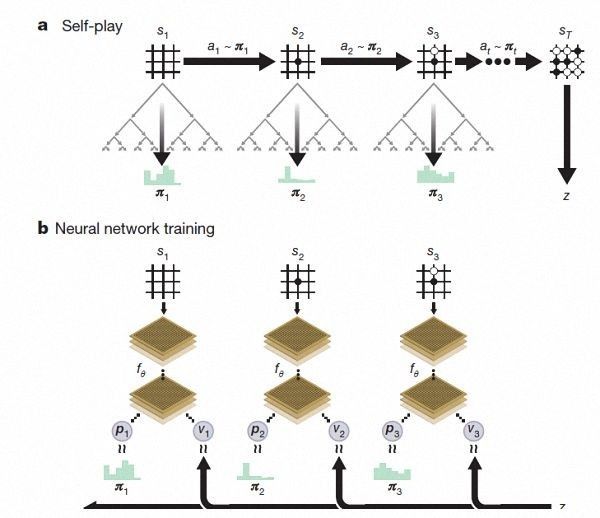
(Zero强化学习下的自我对弈)
此外,
Zero也不再使用快速而随机的走子方法。
打个比方“旧狗”像是
走一步看三步、
步步为营的棋手,而Zero更像是纵观全局、成竹在胸的围棋大师。
DeepMind团队称,Zero用更新后的神经网络和搜索算法重组,随着训练加深,系统的表现不断进步。自我博弈的成绩也越来越好。同时,神经网络也变得更准确。
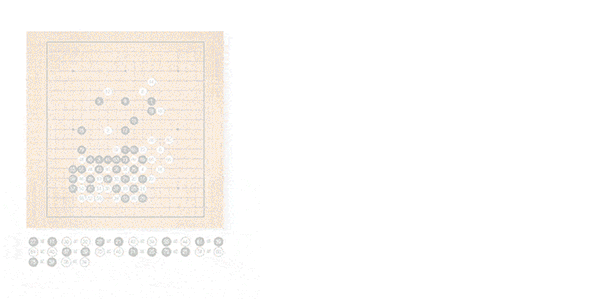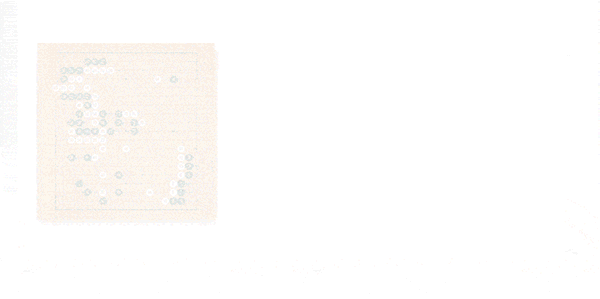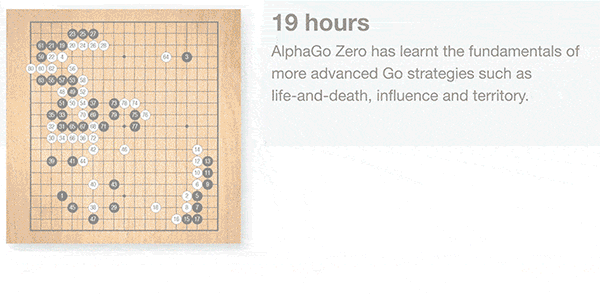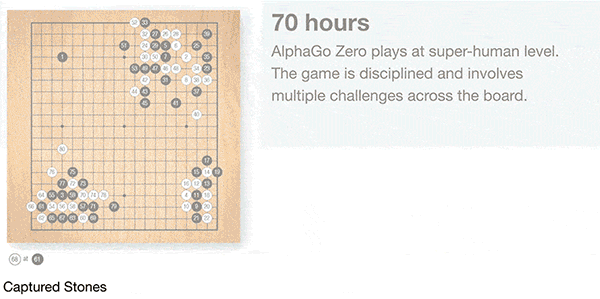
Zero的学习很好地反映了人类棋手学习的过程。像初学者一样,开始只是贪婪地想要吃掉对方的棋子。但是经过3天训练,它就能掌握人类围棋高手所使用的复杂的技巧,“它重新发现了人类几千年的知识”,哈萨比斯说。
从下图可以看出,Zero的胜率一直在提升。3天后能战胜李世石,21天后能战胜AlphaGo Master,而40天后,就能超过AlphaGo此前的所有版本。





