本文转载自一位朋友的博客《世民谈云计算》,原文地址:http://www.cnblogs.com/sammyliu/p/8902556.html
本文分两部分:部分1 和 部分2。部分1 介绍 AWS,部分2 介绍阿里云和OpenStack云。
1. AWS
1.1 AWS 地理组件概况
AWS 提供三种地理性组件:
-
Regions:区域,即AWS提供云服务的一个区域,其目的是为了用户能就近接入,降低网络延迟。通常是一个城市的若干个AZ组成一个region。2016年,AWS 宣布在其全球region之间建设了100GbE 私有环网。
-
Availability Zones:一个 region
内至少两个通常三个可用区,其用途是为了搭建高可用架构。一个比较常见的看法是一个AZ是一个数据中心。其实这不尽然,有时候靠得非常近的几个数据中心也可以组成一个AZ。最多一个AZ有8个数据中心。部分AZ
超过30万台服务器。AZ拥有独立的包括电力和网络在内的基础设施等。AZ 之间利用低延迟光纤网络互联。
-
Edge Locations:指往往部署在大城市,以及主要人口汇聚区域的AWS
站点。它的主要作用是缓存数据,降低延迟。它们独立于region 和 AZ,数量比AZ多很多。它被多个AWS服务利用,比如AWS
CloudFront 和 AWS Lambda@Edge。CloudFront 利用它来作为提供给用户分布在全球的接入点,通常称为Edge
POP 点。
AWS 基础组件:
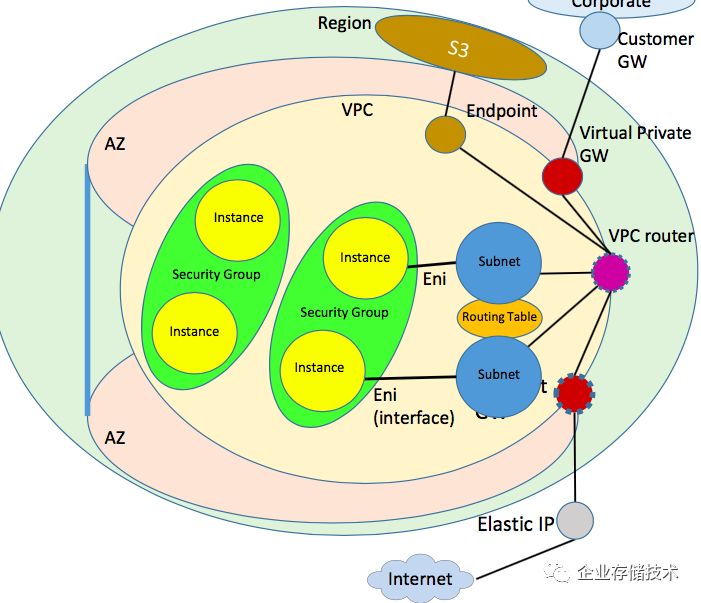
图示:AWS 全球regions 采用100GbE 环网互联(除中国region外)
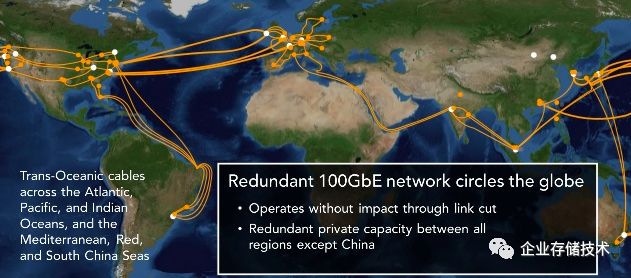
图示:AZ 与AZ之间使用低延迟光纤网络互联
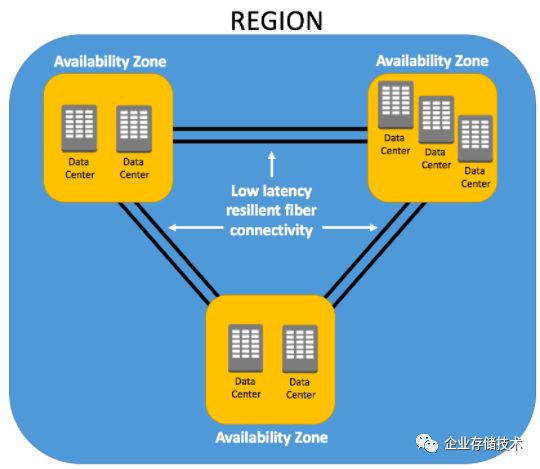
图:AWS 区域与可用区之间的关系(所有region 都有 2+ AZ,新建region 有 3+ AZ,最多一个region有5个AZ)
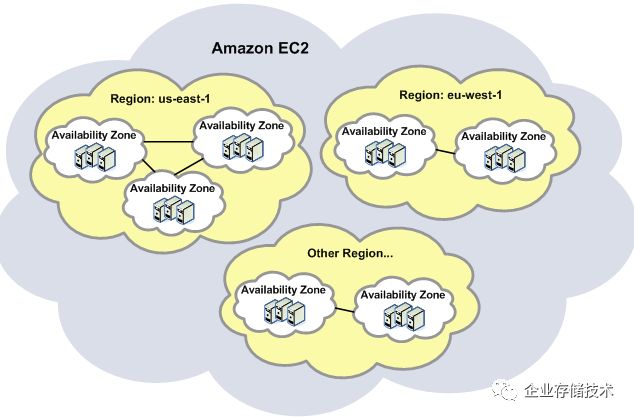
图:AWS region 与 Edge POP(截至2017.06,全球77个PoP点,11个 区域性 Edge Cache 点)
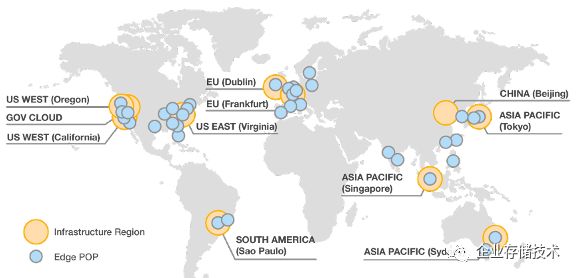
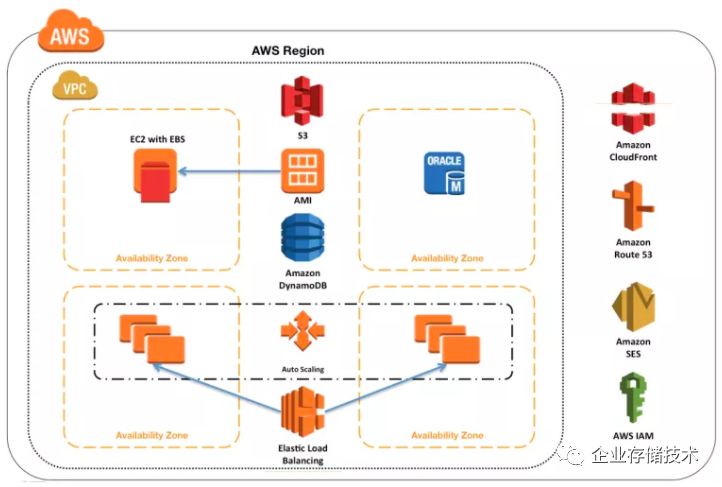
1.2 AWS 各服务与地理性组件的关系
AWS 中有大量的服务,每种服务有不同的特性:
-
AWS 少量服务是全局性的,也就是不限于特定region,比如下图中的 IAM、SES、S3 和 CloudFront
-
部分服务是区域性的,也就是其作用范围在某个特定区域内,比如下图中的S3、AMI
-
部分服务是可用区性的,也就是其作用范围在某可用区内,比如下图中的 EC2和EBS
1.3 区域性和可用区性的实例的跨区域复制
AWS S3 的数据位于某个区域内,但是可以进行跨任意区域迁移。因此,很多区域性和可用区性的数据都利用S3该功能做跨区域数据迁移。
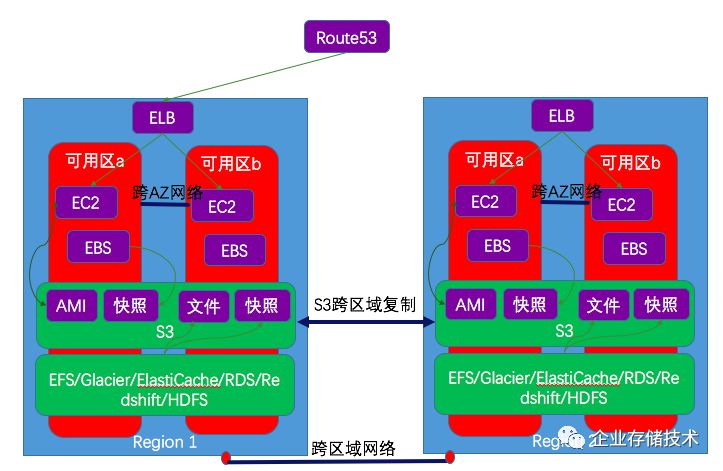
1.3.1 S3 跨区域复制
当数据发送到S3
以后,数据会以对象形式在区域内的多个可用区内保存。但是,每个区域的S3依然有单点故障风险。当一个region故障后,该区域的S3服务将变得不可用。要避免该问题,AWS提供了
Amazon S3 Cross-Region replication (CRR) 功能。它能够在不同的可用区之间异步地同步S3 bucket
中的数据。
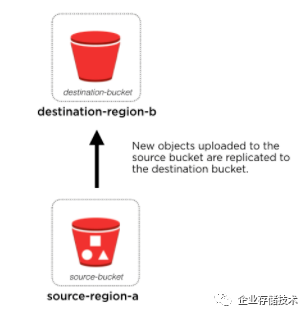
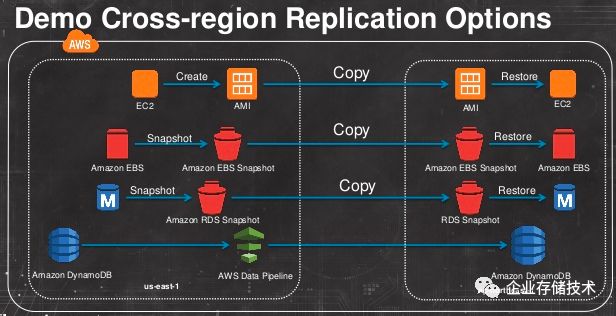
1.3.2 区域之间的数据复制
下图中的 AMI、EBS snapshot 和 RDS snapshot 都是保存在 S3 之中,因此都能够利用 S3 的跨区域复制能力复制到其它区域。
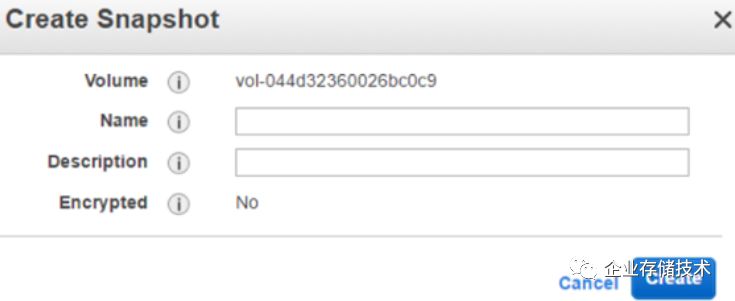
1.3.2.1 EBS 的跨区域迁移
EBS 是可用区性的。要将某个 EBS 实例拷贝到另一个region,需要利用 S3 的跨区域复制能力。
(1)为 EBS 创建 snapshot,它会被保存在 S3 内。
(2)利用 EBS snapshot copy 功能将 EBS 快照拷贝到另一个region中
![]()
(3)在新的region 中从该snapshot 上创建一个新的 EBS 实例
1.3.2.2 EC2 实例的跨可用区迁移
(1)为 ECS 实例创建 AMI。AMI 在整个区域内可见,因此肯定可以在另一个可用区内使用
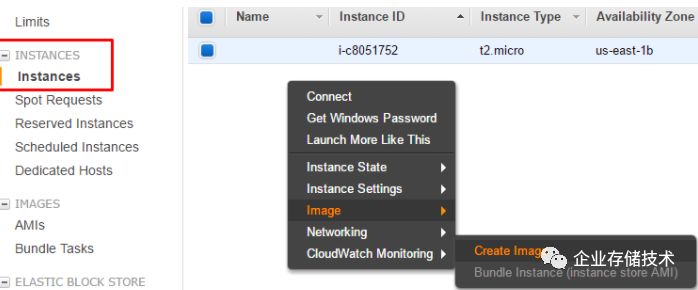
(2)在另一个可用区内,利用该 AMI 创建一个新的实例。
1.3.4 AWS RDS复制
(1)AWS Multi-AZ RDS (AZ 之间数据同步复制)
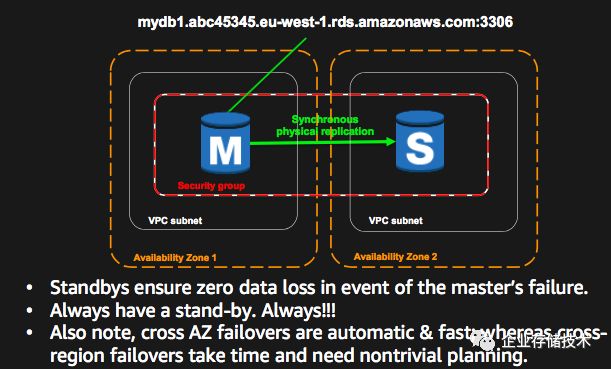
AWS 的 Multi-AZ RDS 功能就是利用AZ 之间的低延迟网络的一个例子。它的主要特性如下:
-
支持 MySQL, MariaDB, PostgreSQL, Oracle, 和 SQL Server database (DB) RDS 实例
-
包括一主一备两个数据库进程,分别位于同一个region内的两个可用区内
-
主备之间数据同步复制
-
只有主提供读写服务,备不对外提供服务
-
DB 应用通过 DNS 来访问主节点
-
主备自动切换,通常切换时间为 60~120 秒,自动切换时会更新DSN 记录,对数据库应用透明
-
与单AZ RDS 相比,延迟大概会增加 2~5 ms
-
该方案提供 99.95% 的 SLA
-
该方案只能用于HA和DR,不能用于提高性能和扩容
(2)AWS RDS Read Replica (region 之间异步数据复制)
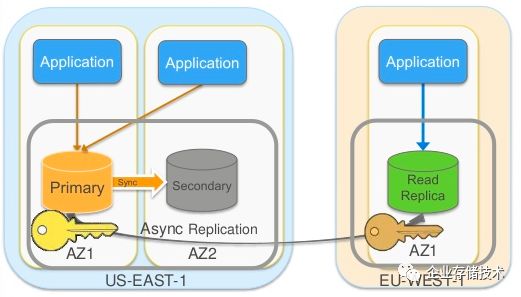
AWS RDS Read Replica 是在区域之间做数据复制的一个例子。它的主要特性如下:
-
Read Replica 可以在一个region 内,也可以在另一个region内(当前只支持MySQL 和 MariaDB)。
-
Primary 和 Read Replica 之间采用异步数据复制,跨区域时会加密
-
Read Replica 只能用于读,所有的写都到Primary。
-
每个Read Replica 都有各自的 DSN endpoint,每个Primary 最多5个 Read Replica
-
Read Replica 的主要用途包括:分流Primary 上的大量读工作负载,不能用于HA;在Primary 发生故障时可将Read
Replica提升为Master 来提供服务;在靠近用户的region内部署Read Replica 来降低用户访问延迟。
-
当Primary 有 Standy 节点时,在发生自动切换之后,Read Replica 的soure 会自动切换到原来的 Standy(也就是现在的Primary)
两者对比:

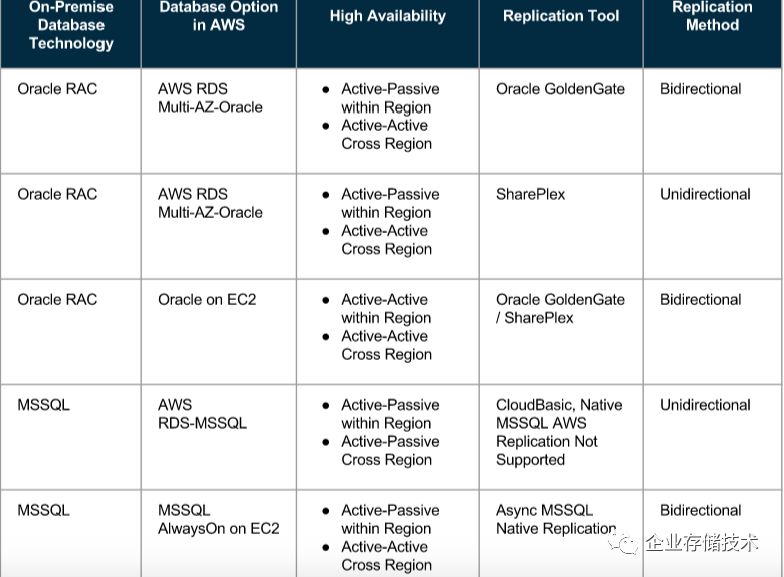
(3)AWS Oracle 和 MSSQL 服务的数据复制能力
1.4 灾备
灾备(Disaster
Recovery)包括灾备方案和环境准备,以及从灾难中恢复两部分。任何对企业的业务持续性或财务有负面影响的事件都可成为灾难。灾难包括硬件或软件故障、断网、断电、火灾、水灾、人为错误等等。为了减少灾难带来的损失,企业往往会投入时间和金钱来计划和准备、训练员工、定义和更新流程。为DR
计划而做的投资往往有很大不同。灾难恢复往往有两个指标:
AWS 把灾备分为四种场景:

1.4.1 Backup & Restore 备份和恢复
传统备份往往利用磁盘,并定期将磁盘运到别处。
将数据备份到AWS上:
1. 利用 S3 和 Glacier 组成多级别的备份环境
2. AWS Storage Gateway 能够将本地环境中的数据备份到 S3 中。
3. AWS Import/Export 能将大量数据运到AWS中。
4. 将AWS EBS 卷、RDS 实例、Redshift 的快照(snapshot)保存到 S3 中。
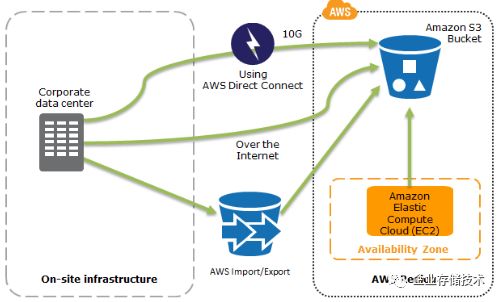

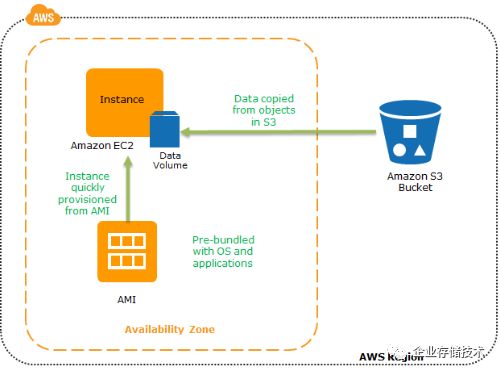
恢复时,利用从 AMI 创建EC2 实例,从S3中恢复数据来快速恢复运行环境。
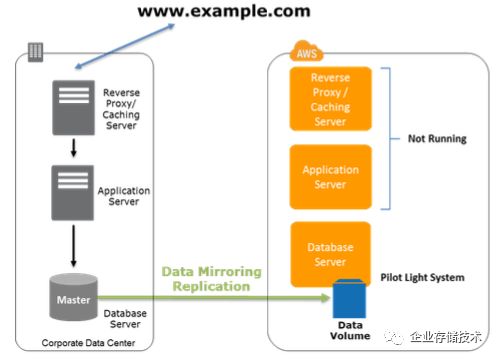
1.4.2 Pilot Light 最小环境(通常也称为 Cold Standy)
上述的备份和恢复方案往往会花费较长时间。Pilot Light
则在AWS上创建最小运行环境,它包含业务系统中最核心部分,比如数据库。这会节省恢复时间,因为系统中最核心部分已经在运行,而且数据是最新的了。而不经常更新部分,比如操作系统和应用,则可以定期打包到AMI中。
恢复时,可以从AMI 中创建EC2实例、切换DNS、安装没有准备AMI的环境,并可以按需对最核心部分进行扩容以支撑生产环境。

1.4.3 Warm Standby Solution in AWS 小规模热备环境(通常也称为 Warm Standy)
该场景中,一个小规模的完整业务环境会运行在AWS中。这环境虽然规模不够大,但功能全面。与 Pilot Light 相比,除了最核心部分,其它部分也在运行了,因此在恢复时能进一步减少时间。
准备阶段,可以选择使用最低配置的服务器,因为DR site 的目标不是承担生产环境的压力,而是为了保持一个运行环境。它还能用于非生产环境,比如测试和内部使用等。
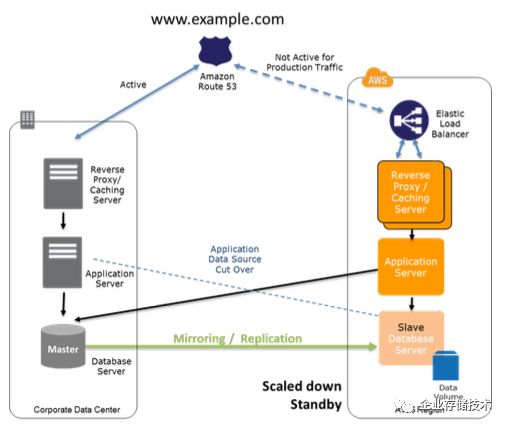
而在恢复阶段,只需要对灾备环境扩容(包括水平扩容和垂直扩容)和切换DNS(手工的或者利用智能DNS自动的)即可:

1.4.4 Multi-Site Solution Deployed on AWS and On-Site 本地和AWS上active-active部署 (通常也称为 Hot Standy)
准备阶段:
-
做法是在AWS上建立一套环境复制你的本地环境
-
考虑数据同步方式,是异步的还是同步的
-
考虑 RTO 和 RPO 的要求
-
DNS 可以两边不同比率分配流量
-
成本取决于在AWS上环境的配置
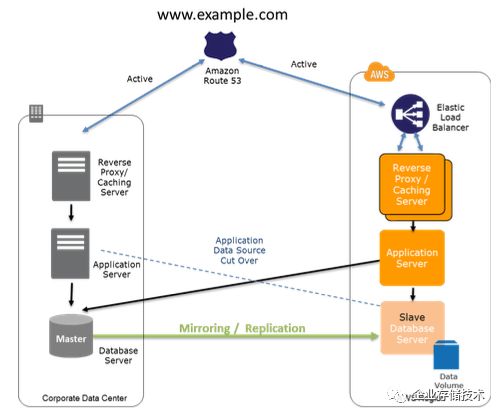
恢复阶段:
1.4.5 多站点部署需要考虑的因素
1. 数据同步:当向远端同步数据时,需要考虑到:
-
站点间的距离 - 距离越远,往往延迟越高
-
可用的带宽
-
应用所需的数据同步速率 - 这速度需要低于可用带宽
-
同步技术 - 同步需要是并行的,以提高效率
-
同步方式 - 同步的和异步的。AWS RDS 在可用区之间是同步的;
-
同步目标 - 是往一个目标站点同步,还是往多个目标站点同步
2. Failing Back from a Disaster 从灾备站点回到主站点
当主站点恢复以后,你往往需要将运行环境从灾备环境切换到原来的主环境,此成为 fail-back。对于不同的灾备场景,有不同的做法。
备份和恢复:
-
冻结向 DR site 的数据更新
-
做备份
-
将备份 restore 到主 site
-
将用户引流到主site
-
解冻数据更新
Pilot light, warm standby, and multi-site:
-
从 DR site 往主site 做数据同步,直到主site数据一致
-
冻结向 DR site 的数据更新
-
将用户引流到主site
-
解冻数据更新
1.4.6 灾备计划
需要有完整的灾备计划。除了实现上述某种灾备方案外,还需要考虑到以下几点:
-
测试:一旦DR site 准备就绪,需要有完整的测试来验证
-
持续的监控和告警:对 DR site 做持续监控,并及时处理问题
-
备份:即使切换到DR site,还是要做常规备份
-
用户访问:要保证用户访问 DR site 的安全性
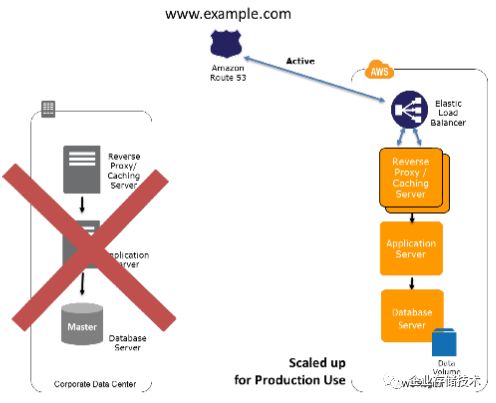
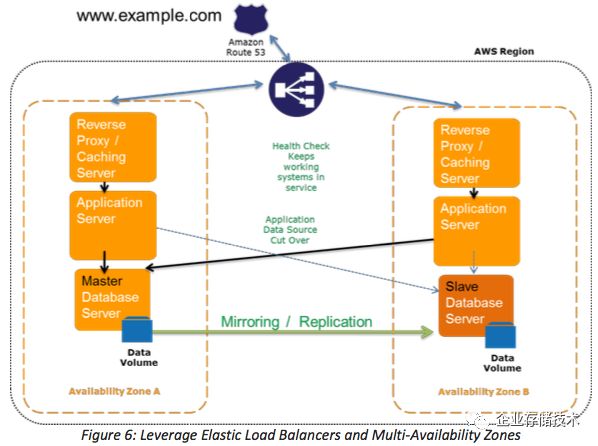
1.5 高可用HA/FT(Fault Tolerant) 方案
1.4 部分中的DR 方案,其实都有故障切换时间,只是时间长短问题。而HA/FT 方案,则没有停机时间。
下面是 AWS 中典型的 HA/FT 方案。但是因为 AWS 的 ELB 只在多可用区之间可用,因此无法跨区域利用。
参考资料:
-
《Using Amazon Web Services for Disaster Recovery》,October 2014
-
《Migrating AWS Resources to a New AWS Region》,July 2017
-
《Building Fault-Tolerant Application on AWS》,October 2011
-
https://blog.csdn.net/awschina/article/details/47086851
-
https://asardana.com/2017/04/30/aws-relational-database-service/
注
:本文只代表作者个人观点,与任何组织机构无关。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
感谢您的阅读和支持!《企业存储技术》微信公众号:HL
_Storage

长按二维码可直接识别关注





