作者 | 毛丽 魏子敏
转自:大数据文摘 |bigdatadigest
星际探索中,一切成就变得格外伟大而浪漫。在无数太空任务中,一类任务特别激动人心——寻找外星生命。

封面图来自NASA
天文学家搜寻外星人的每一点进展都让全人类沸腾。而除了天文学知识和仪器的进展,鉴于天文研究涉及的数据量级异常巨大,数据处理的精进、机器学习、云计算等在数据科学领域的新成就也会为这项事业带来新的意义。
本月早些时间,在东伦敦举办的高性能计算年度研讨会中(Centre for High Performance Computing Workshop),IBM南非研究实验室的Francois Luus博士主持了一场长达三小时的研讨,探索关于深度学习计算环境和无监督学习的相关话题。
Francois Luus
博士介绍了一项由
IBM
和
SETI
研究院合作展开的有趣项目,希望利用
Spark
和机器学习技术找出数据异常,寻找太空中的外星文明信号。

IBM研究实验室的Francois Luus博士介绍相关项目(图片来自IBM博客)
如果假设我们的外星邻居们在试图与我们接触,我们也应该寻找他们。
目前我们已经启动了若干个计划,用来搜索在宇宙中的其他地方存在着生命的证据。
这些计划总称为“SETI(the Search for Extra-Terrestrial Intelligence)”。
SETI致力于用射电望远镜等先进设备接收从宇宙中传来的电磁波,从中分析有规律的信息数据,希望借此发现外星文明。
过去数十年,SETI为了收集外星生命存在的迹象,构建了“艾伦望远镜阵列”(Allen Telescope Array,www.seti.org/ata)。这项工程由微软联合创始人保罗艾伦资助,目标是通过构建一个小型望远镜阵列,在降低成本的同时,达到巨型天文望远镜的探测效果。艾伦望远镜阵列也被称为“世界上用于搜寻银河系中其他文明的最有力的工具”。
艾伦望远镜阵列每小时产生的数据量级高达4.5TB,探测数据中又夹杂大量由自然界和人类产生的干扰数据。
如何处理如此巨大的数据流量?如何通过机器学习算法排除其中的干扰数据,找出真正令人感兴趣的“外太空信号“?
这是SETI亟待解决的技术难题。
IBM目前正使用Spark技术和机器学习算法协助NASA下属的非盈利科研机构SETI (致力于研究人类起源和外星文明的科研机构)来搜寻外星文明。
本次研讨会上,Francois Luus博士向十几位与会者介绍了IBM Bluemix Spark这一技术,并汇报了最新进展。
艾伦望远镜阵列被用于以厘米波段寻找外星智慧存在的蛛丝马迹,至今已产生600万个信号样本。而IBM Bluemix Spark将用来分析取自这些样本的压缩数据集。
Francois Luus博士的团队目标是利用Spark和机器学习技术找出数据异常,进而发现外星生命。
Francois Luus博士表示,这些数据量级太大,SETI团队说不定会漏掉某些外星人的信号。
因此,团队公开了数据库,并提供了数据处理工具,还给出了一些入门的Ipython notebook格式的代码。
这些资源可以从
GitHub
上下载到。感兴趣的同学可以下载下来,说不定可以发现外星文明的信息!
GitHub相关数据集链接:https://github.com/ibm-cds-labs/seti_at_ibm
参与研讨会的学生会在导师指导下,从数据集中寻找与外星人相关的异常值(图片来自IBM博客)
关于
SETI
数据集和数据获取、处理流程
▼

图片来自NASA
SETI利用艾伦望远镜阵列(ATA)来收集太阳系外的辐射信号。几乎每个夜晚,ATA都会收集来自于天空中各个角落的、频率在1-10 GHz的辐射
信号。
信号观测的结果储存于下面的数据中:
- 两个原始数据文件,可能是两个CompAmp或两个archive-CompAmp文件,这取决于信号分类的结果。
- 实时信号分析结果,在SignalDB 中储存为一行数据。
对于每一个ATA望远镜,辐射信号的水平分量和垂直分量是分别测量的。对于每一个偏振方向,全体ATA阵列的原始时序信号会被数字化,并组合成一个数据文件。
另外,时序信号经过带通滤波,因此数据中信号的频率只有很小的范围,也就是带宽是比较小的。确切的频率范围可以从原始数据文件的开头获取信息,并解析出来。团队提供了一个python包,
ibmseti
,可以帮我们解析这个信息。它还可以读取数据文件,进行一些必要的信号处理。
获取数据的一个典型的流程如下:
- 找到天空中感兴趣的区域,并记录它的坐标。
- 确定这些点或者区域的数据是可以获取到的。
- 获取此区域的一行SignalDB 数据,和一个原始原始文件信息。
- 获取原始数据文件的一个临时URL。
- 下载和存储数据。
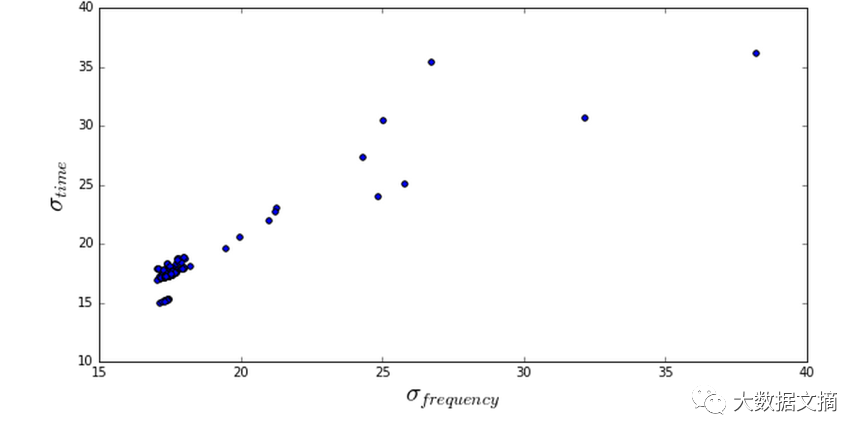
假如我们要使用的特征是“标准差”。可以计算每个轴的标准差,考虑N个频率段(通常为6144)和M个时间段(通常为129)的频谱图。
首先计算沿时间轴的标准差std_time,然后为每个时间段计算沿频率轴的标准差std_freq。如图所示: