好消息
:爬虫俱乐部即将推出研究助理供需平台,如果您需要招聘研究助理(Research Assistant or Research Associate),可以将您的需求通过我们的公众号发布;如果您想成为一个RA,可以将您的简历发给我们,进入我们的研究助理数据库。帮我们写优质的推文可以提升您被知名教授雇用的胜算呀!
前几天,在小女子公众号里发布了一篇《世界银行数据批量下载,暗含小心机呦!》意外引得关注,哈哈!看来在摸索如何快速下载世界银行数据的道路上,我并不孤单!但是,上次方法下载后的数据距离直接使用,还隔了一小步!今天就是为了跨越这一小步,实现从数据的下载到直接使用!
回顾一下世界银行数据下载的方法:
第一步:从世行网站下载中文or英文版的excel表格,获取国家或者指标的名称。我介绍的时候,推荐导入sheet2,当然导入sheet1也是可以的,只不过需要多几步清理数据,但是可以得到
countrycode
。
import excel using e:\世行数据\世界发展指标.xlsx, sheet("Definition and Source") first case(lower) clear
//
导入数据
第二步:使用一个小循环,让stata自行下载每个变量,并分别保存成一个.dta文件
levelsof code,clean local(var)
foreach x of local var {
wbopendata,indicator("`x'") clear long year(year1960-2016)
save wb`x'.dta,replace
}
第三步:openall后,借助excel批量添加标签和重命名。
保存数据后,开开心心的准备与其它数据合并,这时候问题来了!!!
使用openall后,你会发现数据真的是“拼接”起来,一个国家一个变量对应一个时间序列。这是由于下载的是每一个变量的数据,那么合并的时候,一行观测值只包含一个变量的一年的数据,所以合并后的数据,对于每个公司每个年份就有多个观测值。我们以1965年和1966年Austria的数据为例!如下图:
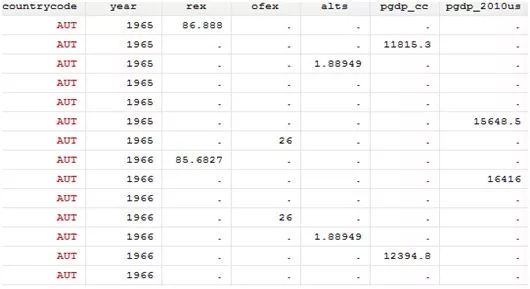
但是,我们需要的是让每一个变量的数据在同一行观测值中,并分别对应一个年份。
处理思路:按照
countrycode
和
year
进行分组,然后用
carryforward
进行填充缺失值,关于
carryforward
的用法在推文
carryforward——填充缺失值
有详细的介绍。填充之后,在每一组的最后一行,就对应了每一个变量的值,最后保留最后一行即可。
第四步:清理数据,分组填充再保留最后一行!
foreach var of varlist rex-gdp_cus{
bysort countrycode year: carryforward `var',replace
}
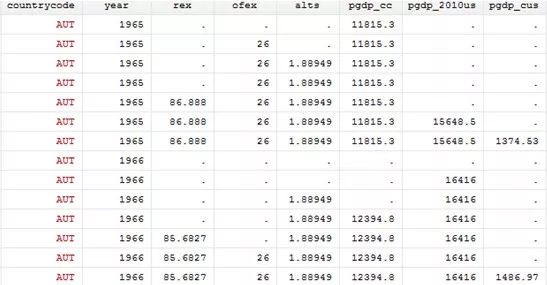
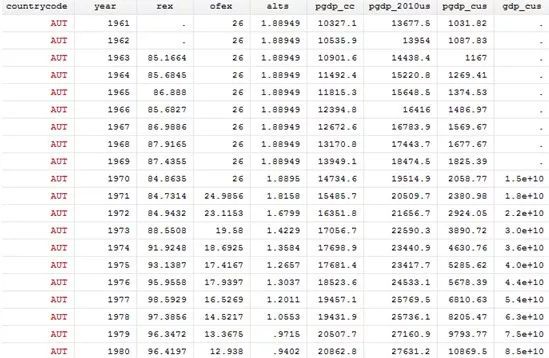
bysort countrycode year : keep if _n == _N
//按照国家和年份分组,保留最后一行数据,得到我们想要的面板数据!
sort countrycode year
save wdi.dta,replace
第五步:删除之前下载的一个一个变量的表
fs wb?*.dta
foreach f in `r(files)' {
rm `f'
}
划重点!!!
虽然只需要定义变量的范围,我们就可以批量处理数据。但是现实是,我们往往无法一次下载所有我们所需要的指标,需要多次下载数据时,我们要不断修改变量名。尽管只有两个,那也是体力活啊!!可否不需要输入变量名,直接使用一个可以得到所需变量名的返回值的神器。嗯,没有最懒,只有更懒!这个世界是由懒人推动的!
寻寻觅觅,终于找到了——
findname
!
findname
可以列出符合某个模式或者属性的变量的名称,并且这些变量名被放到返回值r(varlist)中,方便在后边的程序中调用。通过
Help findname
,我们可以找到findname的用法:
findname [varlist] [if] [in] [, options]
options:包括四大类
control,display,Selection by data types, values
and
formats
和
Selection by characteristics
举例:
findname, type(int/numeric/string)
整数型、数值型和字符型的变量
findname, varl(*weight* *Weight*)
数值标签中含有“weight或Weight”
findname, varl("*some phrase*")
数值标签中含有某些文本
findname, any(@ < 0)
含有负值的变量
篇幅有限,更多精彩内容请自行查阅,哈哈!
回到openall之后的第四步!
由于下载的数据中既有
countryname
,
region
等
string
变量,也有数值型变量。我们需要批量处理的都是数值型变量,因此,我们只选择
type
为
numeric
的变量,结果返回到
r(varlist)
中。然后借用前面的循环,也可得到干干净净、清清爽爽的世界银行数据!
具体如下:
findname,type(numeric)
//找到是数值型的变量名称
foreach v of varlist `r(varlist)'{
bysort countrycode year: carryforward `v',replace
}
不需要定义变量名,感觉又轻松了很多!哈哈!如有小伙伴有更简单的方法,欢迎分享!
总结一下三大法宝:
levelsof
---
findname
---
fs
,分别找到变量值
r(levels)
、变量名
r(varlist)
和文件名
r(files)
!! 用“最懒”的方法,得到最完美的数据!
最后,提前祝大家新年快乐!
喜欢不?喜欢请给压岁钱啦!O(∩_∩)O哈哈~
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~





