大数据文摘作品,转载要求见文末
编译团队|李小帅,姚佳灵
有太多不如没有!如果一个数据集有太多变量,会怎么样?这里有些可能的情况你也许会碰上——
1.你发现大部分变量是相关的。
2.你失去耐心,决定在整个数据集上建模。这个模型返回很差的精度,于是你的感觉很糟糕。3.你变得优柔寡断,不知道该做什么。4.你开始思考一些策略方法来找出几个重要变量。
相信我,处理这样的情形不是像听上去那样难。统计技术,比如,因子分析,主成分分析有助于解决这样的困难。在本文中,我详细地解释了主成分分析的概念。我一直保持说明简要而详实。为了操作上的理解,我也演示了在R使用这个技术并带有解释。
注意:
要理解本文的内容,需要有统计学的知识。
什么是主成分分析?
▼
简而言之,主成分分析是一种从一个数据集的一大组可用变量中提取重要变量的方法。它从高维度数据集中提取出低维度特征变量集合,并尽可能多地捕捉到信息。变量越少,数据可视化也变得更有意义。处理3维或者更高维度的数据集时,主成分分析方法更有效。
它总是在一个对称相关或协方差矩阵上施行。这意味着矩阵应该是数值型的,并且有着标准化的数据。
让我们通过一个例子来理解:
假设我们有一个300(n) X 50(p)维度的数据集。n代表着样本集数量,p代表着预测值的数目。由于我们有个很大的p值,p = 50,因此,会有p(p-1)/2个散布图,也就是说,有可能超过1000个散布图需要分析变量间的关系。在这样的数据集中做探索分析是不是一件非常繁琐的事呀?
在这样的情况下,选取一个捕捉到尽可能多信息的预测值子集p(p
下图显示了利用主成分分析从高维度(三维)数据到低维度(二维)数据的转换。请别忘了,每一个所得到的维度都是特征p的线性组合。
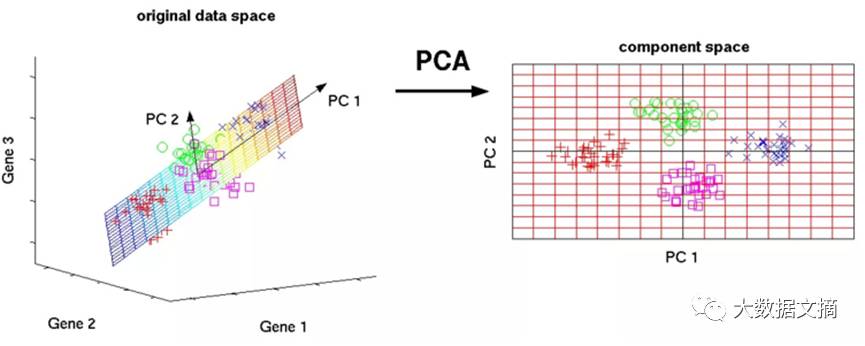
图片来源:nlpca
什么是主成分?
▼
主成分是数据集中的初始预测值规范化后的线性组合。在上图中,PC1和PC2便是主成分。假设我们有一个预测值集合:X¹,X²...,Xp
主成分可以写成:
Z¹ = Φ¹¹X¹ + Φ²¹X² + Φ³¹X³ + .... +Φp¹Xp
其中——
◇ Z¹是第一主成分
◇ Φp¹是构成第一主成分负载量(Φ¹, Φ²…)的加载向量 。该向量被限制成模长为1。这是因为加载向量的数值巨大的模也许会导致巨大的差异。它还定义了沿着数据变化最大的主成分(Z¹)的方向。这样一来,它使得在P维度空间中存在一条最接近n样本集的直线。拟合的程度由欧式距离平方均值来衡量。
◇ X¹..Xp 是规范化后的预测值。规范化后的预测值的均值为0、标准差为1。
因此,
第一主成分是在数据集中捕捉最大方差的初始预测变量的线性组合。它决定了数据中最高变异性的方向。在第一主成分中,捕捉到的变异性越大,成分捕捉到的信息就越多。没有比第一主成分有更高变异性的成分。
第一主成分形成一条最接近数据的直线,
也就是说,它把数据点和该直线之间的距离平方和最小化了。
类似地,我们也能够计算第二主成分。
第二主成分(Z²)也是捕捉到数据集中剩余方差的线性组合,和第一主成分(Z¹)不相关
。换句话说,第一主成分与第二主成分间的相关系数为0。它可以表示成:
Z² = Φ¹²X¹ + Φ²²X² + Φ³²X³ + .... + Φp2Xp
如果两个成分是不相关的,那么两者应该是正交的(见下图)。下图是在模拟数据上用两个预测值绘制的。需要注意的是,主成分的方向,正如预期的那样,是正交的。这表明在这两个主成分之间的相关系数为0。
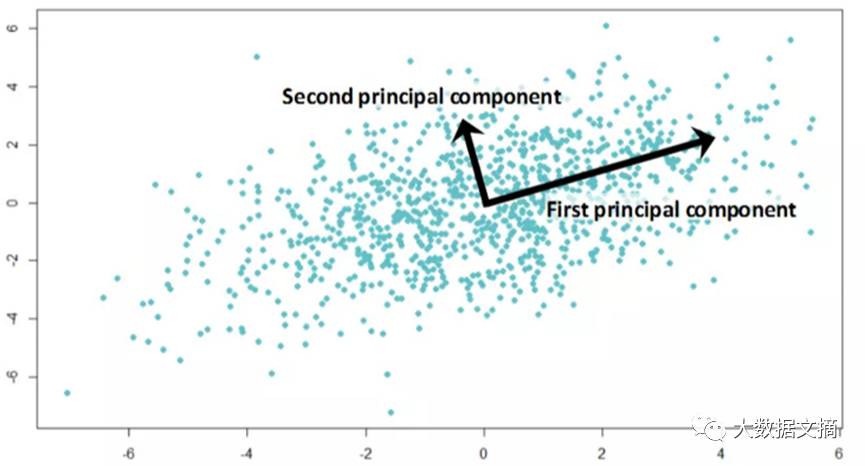
所有接下来的主成分都跟从着相似的概念,即它们捕捉前一个主成分剩余的变化,并与之不相关。一般而言,对于n x p维度的数据,能够构建最小的主成分向量为(n-1, p)。
这些主成分的方向是以无监督的方式确定的,也即响应变量(Y)不是用来决定主成分方向的。因此,这是以无监督的方式。
注意:偏最小二乘法(Partial least square,简称PLS)是替代主成分分析的一种监督方法。偏最小二乘法分配较高的权重给与响应变量y具有强相关关系的变量,以此决定主成分。
为什么变量规范化是必须的?
▼
主成分是由原始预测数据规范化后提供的。这是因为原始预测数据可能具有不同的范围尺度。
例如,想象一下这么一个数据集,在该数据集中存在很多变量的度量单位:加仑、公里、光年等等。可以肯定的是在这些变量中的方差范围会很大。
在没有规范化的变量上执行主成分分析会导致带有高方差变量近乎疯狂的大量的负荷。反过来,这将导致一个主成分依赖于具有高方差的变量。这不是我们所希望的。
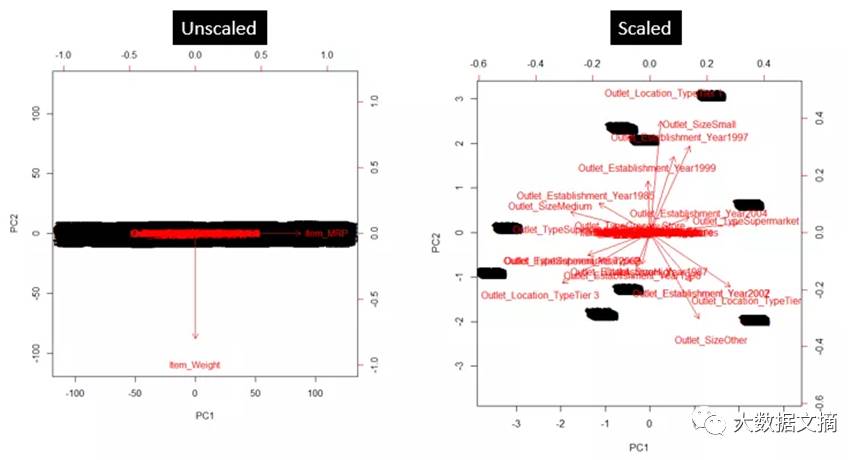
如下图所示,主成分分析在一个数据集上执行了两次(带有未缩放和缩放的预测值)。该数据集有大约40个变量,正如你所见,第一主成分由变量Item_MRP所主导。同时,第二主成分由变量Item_Weight主导。这种主导普遍存在是因为变量有相关的高方差。当变量被缩放后,我们便能够在二维空间中更好地表示变量。
在Python & R中应用
主成分分析方法
(带有代码注解)
▼
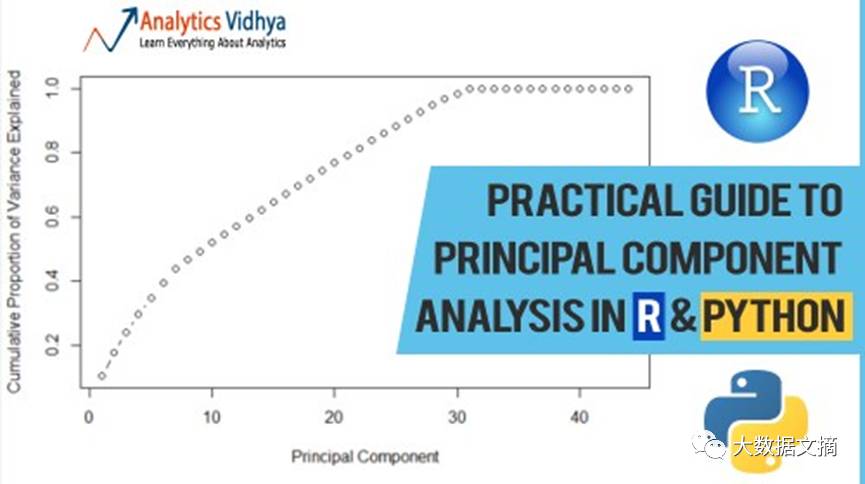
要选多少主成分?我可以深入研究理论,但更好是用编程实战来回答这一问题。
作为演示示例,我将使用来自BIg Mart Prediction Challenge上的数据。
请记住,主成分分析仅能应用于数值型数据,因此,如果数据集中存在分类变量,必须将其转换成数值型的。而且在应用这个技术前前,必须进行了基本的数据清理。让我们快点完成原始数据的加载和清理步骤:
#目录路径
> path
#设定工作目录
> setwd(path)
#加载训练和测试文件
> train
> test
#增加一列
> test$Item_Outlet_Sales
#合并数据集
> combi
#用中位值替换缺失值
> combi$Item_Weight[is.na(combi$Item_Weight)]
#用中位值替换0
> combi$Item_Visibility
#找出模式并替换
> table(combi$Outlet_Size, combi$Outlet_Type)
> levels(combi$Outlet_Size)[1]
至此,我们已对缺失值做了替换处理。现在剩下的都是除去了依赖性(响应)变量和其它标识符变量(如果存在的话)。正如上面所讲,我们正在练习无监督学习技术,因此,响应变量必须除去。
#除去依赖性和标识符变量
> my_data
Let’s check the available variables ( a.k.a predictors) in the data set.
现在,检查一下数据集中的可用变量(也即预测值):
#检查可用变量
> colnames(my_data)
由于主成分分析作用于数值型变量上,让我们看看是否有不是数值型的变量。
#检查变量的类
> str(my_data)
'data.frame': 14204 obs. of 9 variables:
$ Item_Weight : num 9.3 5.92 17.5 19.2 8.93 ...
$ Item_Fat_Content : Factor w/ 5 levels "LF","low fat",..: 3 5 3 5 3 5 5 3 5 5 ...
$ Item_Visibility : num 0.016 0.0193 0.0168 0.054 0.054 ...
$ Item_Type : Factor w/ 16 levels "Baking Goods",..: 5 15 11 7 10 1 14 14 6 6 ...
$ Item_MRP : num 249.8 48.3 141.6 182.1 53.9 ...
$ Outlet_Establishment_Year: int 1999 2009 1999 1998 1987 2009 1987 1985 2002 2007 ...
$ Outlet_Size : Factor w/ 4 levels "Other","High",..: 3 3 3 1 2 3 2 3 1 1 ...
$ Outlet_Location_Type : Factor w/ 3 levels "Tier 1","Tier 2",..: 1 3 1 3 3 3 3 3 2 2 ...
$ Outlet_Type : Factor w/ 4 levels "Grocery Store",..: 2 3 2 1 2 3 2 4 2 2 ... -
可惜,9个变量中有6个本质上是分类变量。现在,我们得做些额外工作。我们将使用一位有效编码将分类变量转换成数值型。
#载入库
> library(dummies)
#创建一个虚拟的数据帧
> new_my_data
"Outlet_Establishment_Year","Outlet_Size",
"Outlet_Location_Type","Outlet_Type"))
检查一下,现在我们是否有了一个整数值数据集,只要简单地写:
#检查数据集
> str(new_my_data)
是的,现在数据类型全部为数值型的。现在我们能够继续工作,应用主成分分析了。
基本R函数prcomp()用来实施主成分分析。默认情况下,它让变量集中拥有等于0的均值。用上参数scale. = T,我们规范化变量使得标准偏差为1。
#主成分分析
> prin_comp
> names(prin_comp)
[1] "sdev" "rotation" "center" "scale" "x"
prcomp()函数形成5种实用操作:
1. 中心和规模是指在实施主成分分析前用于标准化变量的各均值和标准偏差
#输出变量的均值
prin_comp$center
#输出变量的标准偏差
prin_comp$scale
2.旋转措施提供主成分的负载。旋转矩阵的每一列包含主成分负载向量。这是我们应该感兴趣的最重要措施。
它返回44个主成分负载。正确吗?当然。在一个数据集中,主成分负载的最大值至少为(n-1, p)。下面我们看看前4个主成分和前5行。
> prin_comp$rotation[1:5,1:4]
PC1 PC2 PC3 PC4
Item_Weight 0.0054429225 -0.001285666 0.011246194 0.011887106
Item_Fat_ContentLF -0.0021983314 0.003768557 -0.009790094 -0.016789483
Item_Fat_Contentlow fat -0.0019042710 0.001866905 -0.003066415 -0.018396143
Item_Fat_ContentLow Fat 0.0027936467 -0.002234328 0.028309811 0.056822747
Item_Fat_Contentreg 0.0002936319 0.001120931 0.009033254 -0.001026615
3.为了计算主成分评价向量,我们不必将数据和负载相乘。相反,矩阵X具有14204 x 44 维度的主成分评价向量。
> dim(prin_comp$x)
[1] 14204 44
让我们来绘制产生的主成分——
> biplot(prin_comp, scale = 0)
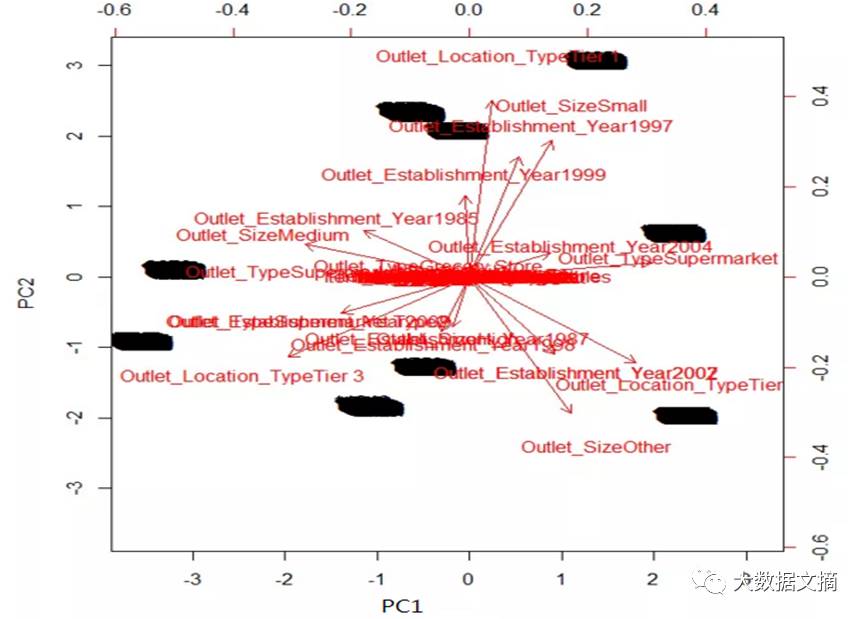
参数scale = 0确保上图中箭头的缩放代表负载。为了从上图中作出推断,关注图中的最末端(上、下、左、右)。
我们推断第一主成分与Outlet_TypeSupermarket、Outlet_Establishment_Year2007的量度对应。类似的,第二成分和Outlet_Location_TypeTier1、Outlet_Sizeother的量度对应。对应一个成分里的某个变量的精确量度,应该再看看旋转后的矩阵(如上)。
4.prcomp函数也提供了计算每一个主成分标准偏差的便利。sdev是指主成分标准偏差。
#计算每个主成分的标准偏差
> std_dev
#计算方差
> pr_var
#查看前10个成分的方差
> pr_var[1:10]





