
#长按上图识别二维码,参与OSC源创会年终盛典#
摘要: 本文整理自 OSC 第 54 期重庆源创会上徐飞老师的演讲,他详细地介绍了如何使用 RxJS 构造复杂单页应用的数据逻辑,干货满满,各位程序员不要错过了,尤其是前端的程序员们~欢迎大家积极参加源创会,一起交流、学习、进步。
徐飞
,Teambition 前端架构师,长期从事企业应用前端架构的工作,对单页应用实现方案有深入的研究。这个领域和互联网传统的前端有一些区别,对数据层方面比较看重,对组件化要求会比较多一些。Teambition 是一个团队协同工具,对于数据的实时性要求非常高。
RxJS 简介
RxJS 是 JavaScript 的 ReactiveX 库。总的来说,它用于描述数据变化与时间的关系,是可用于异步操作的 lodash。
这句话比较难懂,可以通过了解它的使用场景来理解。
我们经常看到这些场景:
这类场景的一个共同特点是:
这么一个界面,考虑到它的完全展示,可能会有这么两种方案:
微博使用的前一种,并且引入了 bigpipe 机制来生成界面,而 Teambition 则使用后一种,主要差别还是由于产品形态。
Teambition 业务场景
-
复杂的单页应用
-
主要功能都集中在一个页面中
-
同一份数据存在多份副本
-
全业务都有与服务端的实时数据同步
业务面临的问题
先来看一个例子,现在有项目、任务这样的组织方式。任务是挂在项目下面的,如果需要查询一条任务,要先把它所属的项目(A)查询出来,此时切换到另一个项目(B),并点开其中一条任务,这个时候如果再切换回去。可以知道,刚刚已经请求过项目 A 的数据,那现在切换回去是否还需要再次请求呢?其实是可以不用,但是如果不请求会出现什么问题呢?毕竟不知道刚刚的过程中项目 A 是否有被修改。
所以,这就要求我们的数据查询是离散化的,任务信息和额外的关联信息分开查询,然后前端来组装,这样,一是可以减少传输数据量,二是可以分析出数据之间的关系,更新的时候容易追踪。
除此之外,Teambition 的操作会在全业务维度使用 WebSocket 来做更新推送,比如说,当前任务看板中,有某个东西变化了(其他人创建了任务、修改了字段),都会由服务端推送消息,来促使前端更新界面。
离散的数据会让我们需要使用缓存。比如说,界面建立起来之后,如果有人在其他端创建了任务,那么,本地的看板只需收到这条任务信息并创建视图,并不需要再去查询人员、标签等关联信息,因为之前已经获取过。所以,大致会是这个样子:
某视图组件的展示,需要聚合 ABC 三个实体,其中,如果哪个实体在缓存中存在,就不去服务端拉取,只拉取无缓存的实体。
这个过程带来第一个挑战:
查询同一种数据,可能是同步的(缓存中获取),可能是异步的(AJAX 获取),业务代码编写需要考虑两种情况。
WebSocket 推送则用来保证前端缓存的正确性。但是,需要注意到,WebSocket 的编程方式跟 AJAX 是不一样的,WebSocket 是一种订阅,跟主流程很难整合起来,而 AJAX 相对来说,可以组织到包含在主流程中。
例如,对同一种更新的不同发起方(自己修改一个东西,别人修改这个东西),这两种的后续其实是一样,但代码并不相同,需要写两份业务代码。
这样就带来第二个挑战:
获取数据和数据的更新通知,写法是不同的,会加大业务代码编写的复杂度。
数据这么离散,从视图角度看,每块视图所需要的数据,都可能是经过比较长而复杂的组合,才能满足展示的需要。
所以,第三个挑战:
每个渲染数据,都是通过若干个查询过程(刚才提到的组合同步异步)组合而成,如何清晰地定义这种组合关系?
此外,可能面临这样的场景:
一组数据经过多种规则(过滤,排序)之后,又需要插入新的数据(主动新增了一条,WebSocket 推送了别人新建的一条),这些新增数据都不能直接加进来,而是也必须走一遍这些规则,再合并到结果中。
这就是第四个挑战:
对于已有数据和未来数据,如何简化它们应用同样规则的代码复杂度。
带着这些问题,来开始今天的思考过程。
第一点做的是数据缓存中心化,在前端把所有数据的缓存当做一个中心,但这里面就会出现两种情况:
-
上层视图第一次调用的时候,缓存不一定存在。这就需要向服务端请求数据之后,把数据拆解并缓存,这是一个异步加载的过程。
-
缓存存在的情况下,直接从缓存拼装数据给界面显示,这是同步的过程。
那么问题就来了,同样是请求一个项目的数据,有可能是同步,也有可能是异步的,代码该如何写,因为同步和异步的代码写法不一样。还有一个问题是 WebSocket 的消息是直接合并进缓存的。这个对前面的情况又会产生什么影响呢?
1. 同步与异步的统一
在前端,经常会碰到同步、异步代码的统一。假设要实现一个方法:当有某个值的时候,就返回这个值,否则去服务端获取这个值。
通常的做法是使用 Promise:
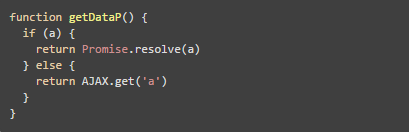
所以,处理这个事情的办法就是,如果不确定是同步还是异步,那就取异步,因为它可以兼容同步,刚才代码里面的 resolve 就是强制把同步的东西也转换为兼容异步的 Promise。
只用 Promise 当然也可以解决问题,但 RxJS 中的 Observable 在这一点上可以一样做到:
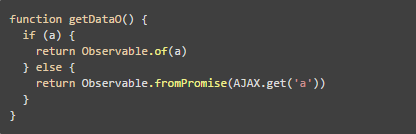
2. 跟 Promise 的差别
有人要说了,你这段代码还不如 Promise,因为还是要从它转啊,优势在哪里呢?
来看看刚才封装出来的方法,分别是怎么使用的呢?

在这一节里,不对比两者优势,只看解决问题可以通过怎样的办法:
结论就是,无论 Promise 还是 Observable,都可以实现同步和异步的封装。
主要是完成以下任务:
-
获取数据
-
订阅并持续响应
-
数据的变更推送到有关联的订阅
获取与订阅的统一
通常,我们在前端会使用观察者或者订阅发布模式来实现自定义事件这样的东西,这实际上就是一种订阅。
从视图的角度看,其实它所面临的是:
得到了一个新的任务数据,我要展示它
至于说,这个东西是怎么得到的,是主动查询来的,还是别人推送过来的,并不重要,这不是它的职责,它只管显示。所以,要给它封装的是两个东西:
然后,就变成类似这么一个东西:
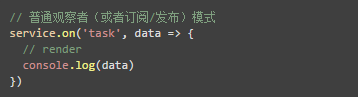
这么一来,视图这里就可以用相同的方式应对两种不同来源的数据了,service 内部可以去把两者统一,在各自的回调里面触发这个自定义事件 task。
但我们似乎忽略了什么事,视图除了响应这种事件之外,还需要去主动触发一下初始化的查询请求:
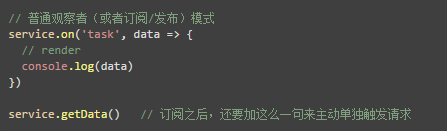
这样看起来还是挺别扭,回到上一节里面的那个 Observable 示例:
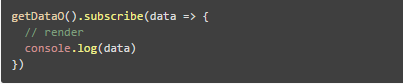
这里使用了 RxJS,可以先直接调用这个方法,然后立刻订阅这个方法的返回结果,这段代码起到两个作用,先是请求数据,然后订阅数据。也就是说,如果以后这条数据有变化,会随着程序执行的过程持续地拿到变化后的数据。这么一句好像就搞定了我们要求的所有事情。可以这么去理解这件事:
-
getDataO 是一个业务过程
-
业务过程的结果数据可以被订阅
这样,就可以把获取和订阅这两件事合并到一起,视图层的关注点就简单很多了。
1. 数据的流式封装
因为这两年 React 开始流行了,所以大家就开始关注视图和它的状态之间的关系 —— 某一个时间的状态可能是通过第一个数据跟第二个数据之间进行某种关系的组合,然后再跟另外一个数据进行组合,最后得到一个数据,把这个数据拿到视图上去展示,基本上来讲是这样的关系。
依据上一节的思路,可以把查询过程和 WebSocket 响应过程抽象,融为一体。说起来很容易,但关注其实现的话,就会发现这个过程是需要好多步骤的,比如说:
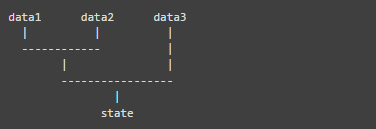
一个视图所需要的数据可能是这样的:
怎么去抽象这个过程呢?
注意,这里面 data1,data2,data3,可能都是之前提到过的,包含了同步和异步封装的一个过程,具体来说,就是一个 RxJS Observable。
可以把每个 Observable 视为一节数据流的管道,我们所要做的,是根据它们之间的关系,把这些管道组装起来,这样,从管道的某个入口传入数据,在末端就可以得到最终的结果,数据在管道中就流动起来了。

2. 可组合的数据通道
RxJS 给我们提供了一堆操作符用于处理这些 Observable 之间的关系,比如说,可以通过一些方式(操作符)把管道连接起来
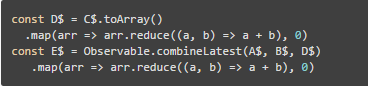
上述的 D 就是通过 C 进行一次转换所得到的数据管道,而 E 是把 A,B,D 进行拼装之后得到的数据管道

从以上的示意图就可以看出它们之间的组合关系,通过这种方式,可以描述出业务逻辑的组合关系,把每个小粒度的业务封装到数据管道中,然后对它们进行组装,拼装出整体逻辑来。因此最后得到的数据就始终是经过这种关系所组合得到的数据。
3. 现在和未来的统一
在业务开发中,我们时常遇到这么一种场景:
已过滤排序的列表中加入一条新数据,要重新按照这条规则走一遍。
我用一个简单的类比来描述这件事:
每个进教室的同学都可以得到一颗糖
这句话表达了两个含义:
这里面,第一句表达的是现在,第二句表达的是未来。我们编写业务程序的时候,往往会把现在和未来分开考虑,而忽略了他们之间存在的深层次的一致性。
想通了这个事情之后,再反过来考虑刚才这个问题,能得到的结论是:
进入本列表的数据都应当经过某种过滤规则和某种排序规则
这才是一个合适的业务抽象,然后再编写代码就是:

其中,source 代表来源,而 final 代表结果。来源经过 filterA 变换、sorterA 变换之后,得到结果。
然后,再去考虑来源的定义:

来源等于初始数据与新增数据的合并。
然后,实现出 filterA 和 sorterA,就完成了整个这段业务逻辑的抽象定义。给 start 和 patch 分别进行定义,比如说,start 是一个查询,而 patch 是一个推送,它就是可运行的了。最后,在 final 上添加一个订阅,整个过程就完美地映射到了界面上。
很多时候,我们编写代码都会考虑进行合适的抽象,但这两个字代表的含义在很多场景下并不相同。
很多人会懂得把代码划分为若干方法,若干类型,若干组件,以为这样就能够把整套业务的运转过程抽象出来,其实不然。
业务逻辑的抽象是与业务单元不同的方式,前者是血脉和神经,后者是肢体和器官,两者需要结合在一起,才能够成为鲜活的整体。
一般场景下,业务单元的抽象难度相对较低,很容易理解,也容易获得关注,所以通常都能做得还不错,比如最近两年,对于组件化之类的话题,都能够谈得起来了,但对于业务逻辑的抽象,大部分项目是做得很不够的,值得深思。
以上,谈及的都是在业务逻辑的角度,如何使用 RxJS 来组织数据的获取和变更封装,最终,这些东西是需要反映到视图上去的,这里面有些什么有意思的东西呢?
最近几年有很多关于视图层的新东西出现,这和之前 jQuery 直接操作数组不一样。比如说 Angular、React 和 Vue.js。从这几个主流的框架中,可以得到一个理念 —— MDV(模型驱动视图)。即任何东西都是在改动了数据之后,由视图层的框架自己按照定义好的规则来把视图改变。而不需要每次修改数据后,再手动改动视图。所以在这个理念下,一切对于视图的变更,首先都应当是模型的变更,然后通过模型和视图的映射关系,自动同步过去。
但是要考虑一点,到底是用什么东西驱动视图改变?其实不同的框架所采用的方式是不一样的,例如 Angular、Vue.js 与 React 就采用了不一样的方式。
-
Angular 是在每一个异步事件完成之后,对比一下现在的数据是否和之前的数据一样,如果不一样,把现在的数据拿去重绘之前的视图;
-
Vue.js 会让数据的 get 和 set 做一件事情,比如说 a.b = 1,会在内部监控到即时的 a.b 的赋值,并在给 a.b 赋值的时候,它会更新界面
-
React 是通过一个东西去收敛回来,因为它是单向数据,也就是输出一条数据,通过某个地方转向,然后再收敛回来,通过这种方式去改变视图。
假如说现在有一个场景,就是某一个属性是依赖于另外一些东西通过计算得到的,比如说界面上现在有三个输入框,第三个输入框里面的值要始终等于第一个跟第二个的和,如果在 Vue.js 上就需要定义一个 Computed Property,就是指某个属性是依赖于其他一些数据,通过计算得到的。这个计算是同步的,假如这个数据是隔几秒再传过来,这个关系不好定义。因为要计算属性,只能用当前的数据而不能是异步的,所以这里就可以用刚才的例子,就是先定义一个流,然后把这个流的数据往上面赋值。
再来看看这些前端 MV* 框架的目的:定义数据和视图的关系,当数据变更之后,自动更新视图。如果把下面数据的变更都用 RxJS 去实现,就是变成数据的管道,数据在管道里面流动,上层的就只需要订阅数据,然后更新界面上的状态。
1. 数据流与视图的结合
现在来看这样一个伪代码,比如说现在有一个请求的数据,既有请求又有订阅,拿到数据之后如何操作,如果是 React 或者 Vue.js 的话,就手动把拿到的数据往 state 或 data 里面设置;如果是 Angular 的话就更简单,可以直接把 Observable 用 async pipe 绑定到视图。在这些体系中,如果要使用 RxJS 的 Observable,都非常简单:

在这个过程中,可能会需要通过一些方式定义这种关系,比如 Angular 和 Vue 中的模板,React 中的 JSX 等等。
这里面有几个点要说一下:
Angular2 对 RxJS 的使用是非常方便的,形如:let todo of todos$ | async 这种代码,可以直接绑定一个 Observable 到视图上,会自动订阅和销毁,比较简便优雅地解决了“等待数据”,“数据结果不为空”,“数据结果为空”这三种状态的差异。Vue 也可以用插件达到类似的效果。
CycleJS 比较特别,它整个运行过程就是基于类似 RxJS 的机制,甚至包括视图,看官方的这个Demo:
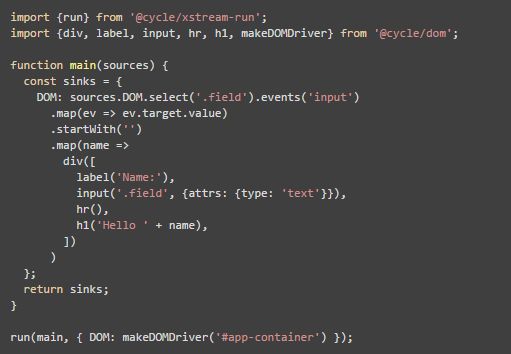
这里面,注意 DOM.select 这段。这里,明显是在界面还不存在的情况下就开始 select,开始添加事件监听了,这就是我刚才提到的预先定义规则,统一现在与未来;如果界面有 .field,就立刻添加监听,如果没有,等有了就添加。
2. 整体状态
整个应用的结构如下所示,最下面是服务端,然后前端有一个数据缓存,数据缓存之上提供了一个 Reactive API,应注意到,这个 API 不是调用一次就没了,它可以持续不断地返回数据,然后再把这个切到视图上。
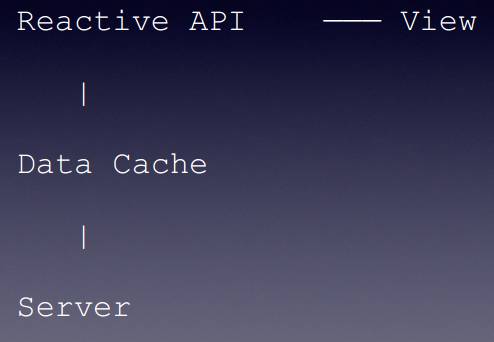
那么,从视图的角度,还可以对 RxJS 得出什么思考呢?
在上次这篇
数据的关联计算
里简单提了一下,其实整篇是在给这篇做伏笔。
一个分析过程可以是这样:
怎么理解这么一套机制呢,可以想象一下这张图:

把 Teambition SDK 看作一个 CPU,API 就是他对外提供的引脚,视图组件接在这些引脚上,每次调用 API,就如同从一个引脚输入数据,但可能触发多个引脚对外发送数据。细节可以参见 SDK 的设计文档。
另外,对于 RxJS 数据流的组合,也可以参见
这篇文章
,你点开链接之后可能心想:这两者有什么关系?
翻到最后那个图,从侧面看到多个波叠加,想象一下,如果把视图的状态理解为一个时间轴上的流,它可以被视为若干个其他流的叠加,这么多流叠加起来,在当前时刻的值,就是能够表达所见视图的全部状态数据。
这么想一遍是不是就容易理解多了?
Teambition SDK
Teambition 新版数据层使用 RxJS 构建,不依赖任何展现框架,可以被任何展现框架使用,甚至可以在NodeJS 中使用,对外提供了一整套 Reactive 的 API,可以查阅
文档和代码
来了解详细的实现机制。
基于这套机制,可以很轻松实现一套基于 Teambition 平台的独立视图,欢迎第三方开发者发挥自己的想象,用它构建出各种各样有趣的东西。我们也会逐步添加一些示例。
使用 RxJS,可以达到以下目的:
-
同步与异步的统一
-
获取和订阅的统一
-
现在与未来的统一
-
可组合的数据变更过程
-
数据与视图的精确绑定
-
条件变更之后的自动重新计算





