1.苹果增加Intel基带份额,传新款iPhone达5成,明年恐逾7成;
2.AMD CEO苏姿丰:有信心今年绝对盈利;
3.Gartner:全球收入前十大半导体厂商排行;
4.芯片战争2.0:“失效”的摩尔定律;
5.大数据重塑新芯片架构,AI处理器寻求突破;
6.ARM布局车联网 拉NXP、NV、瑞萨、TI同卡位
集微网推出集成电路微信公共号:“天天IC”,重大新闻即时发布,天天IC、天天集微网,积微成著!点击文章末端“
阅读原文
”或长按 laoyaoic 复制微信公共号搜索添加关注。
1.苹果增加Intel基带份额,传新款iPhone达5成,明年恐逾7成;
集微网消息,据台湾电子时报报道,面对高通在基带芯片市场独大局面,苹果自iPhone 7系列世代开始将英特尔纳入基带芯片第二供应商,占订单比重约3成,尽管英特尔基带芯片效能不及高通,市场原预期苹果新一代iPhone 8基带芯片订单可能回归高通,但近期高通、苹果官司风暴扩大,业界传出英特尔意外受惠,2017年底新款iPhone基带芯片订单比重将拉升至5成,并预期在2018年扩增至7成以上。
2017年初苹果向美国加州地方法院提告,指控高通芯片订价过高,并拒绝交出属于苹果的10亿美元退款,而高通亦对苹果提告,直控苹果故意让高通基带芯片在iPhone 7上的表现输给英特尔。
近日高通再提起诉讼,对象锁定苹果供应链,指控为苹果制造iPhone与iPad的富士康、和硕、纬创与仁宝违反双方授权合约与承诺,并拒绝就使用高通授权的技术付费,高通向法院请求确认性救济措施和损害赔偿。
供应链表示,高通基带芯片报价约23美元,英特尔约15美元,虽然英特尔芯片效能速度落后高通,然近期苹果已拉高英特尔基带芯片供应比重,iPhone 8新款至年底比重约可达5成,若苹果、高通持续对立,2018年英特尔基带芯片供应比重将扩升至7成以上。
苹果近期拉高Intel基带芯片的出货比重也不排除是为了给高通施压以提高在授权谈判的筹码。
供应链认为,近年不断扩大自制的苹果,先前已宣布停止使用英国GPU业者Imagination GPU,且研发iPhone用电源管理芯片等,苹果极可能已开始投入基带芯片研发,据 Apple Insider 报道,苹果聘请了原高通技术副总裁 Esin Terzioglu 来领导公司的无线 SoC 团队,这一动作也表明苹果正计划将其内部芯片研发扩展到调制解调器领域。因此,英特尔基带芯片美好时光恐仅能维持两个世代,后续必须加速拉升技术实力,并争取非苹阵营订单。
高通苹果的专利授权之争未来真正受惠的肯定是大陆手机厂商,如果苹果自研基带芯片为真,或者使用英特尔的基带芯片比例提升,大陆手机厂商在高通的地位显然会进一步提升。
全球手机竞争格局排行前三的三星、苹果、华为都在开发自家处理器,OPPO、VIVO自觉不自觉已经成为高通最最重要的合作伙伴,华为与OV未来谁将成为中国手机的霸主目前来看难有定论,未来两三年智能手机难见革命性创新,自研处理器与使用第三方产品孰胜孰负现在还真看不清楚,因为芯片投入越来越大。
2.AMD CEO苏姿丰:有信心今年绝对盈利;
集微网台北消息,AMD首季财报不如预期,产品叫好,财报却令市场失望。 但AMD总裁兼CEO苏姿丰31日表示,今年三大产品线都推出新产品,预料第2季起出货逐季成长,有信心今年会盈利。
今年是苏姿丰接任CEO第三年,她昨天在主持台北计算机展新产品发布会后强调,今年是AMD成立30年,主力产品Ryzen处理器和Radeon图形处理器受到市场反映良好,预期本季起将逐季成长,营收和毛利率会持续扬升,有信心今年绝对获利。
苏姿丰表示,AMD是市场上唯一能提供高效能CPU与高效能GPU的品牌,此次发表最新Zen架构的服务器处理器EPYC,以及基于Vega架构的加速器Radeon Instinct,抢进高端市场,将给AMD带来很大帮助。
她表示,以EPYC而言,因具备可提供最多32核心及更高带宽的内存和更多输出脚数,将使AMD在高端服务器市场大有斩获。 她并宣布将于6月20日推出EPYC处理器。 至于服务器合作伙伴,苏姿丰表示,将于6月20发表时对外宣布。
此外,AMD主力处理器和图形处理器也推出新产品,除原本主攻的台式电脑和电竞计算机,也瞄准DIY电竞玩家,推出新的CPU和GPU产品。
AMD昨天邀请戴尔、惠普、宏碁、联想等大厂站台,展示采用搭载Ryzen与Radeon方案的台式电脑和笔记本电脑。 AMD并推出Ryzen Mobile新处理器,且多路并进,抢进二合一、超薄、游戏与商用电脑等四大市场,其中Ryzen Mobile预计下半年推出消费版本,商用版本预计2018上半年推出。
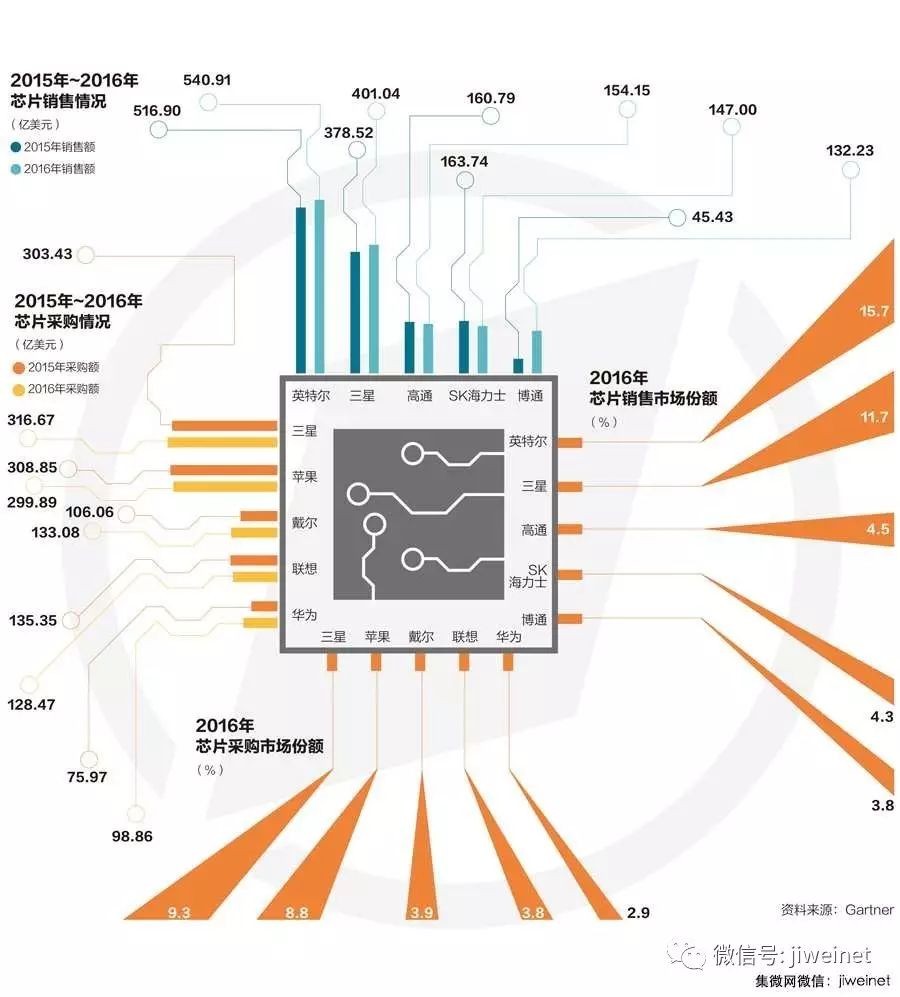
3.Gartner:全球收入前十大半导体厂商排行;
全球领先的信息技术研究和顾问公司Gartner的研究显示,2016年全球半导体收入总计3,435亿美元,较2015年的3,349亿美元提升2.6%。在企业并购潮的影响下,前二十五大半导体厂商总收入增加10.5%,表现远优于整体产业增长率。
Gartner研究总监James Hines表示:“2016年半导体产业出现回弹。虽然其年初因受到库存调整的影响而表现疲软,但下半年需求增强,定价环境得到改善。助力全球半导体收入增长的因素包括多项电子设备部门产量的增加、NAND闪存售价的上扬及相对温和的汇率变动。”
英特尔(Intel)稳坐半导体制造商冠军宝座,2016年半导体收入增长4.6%(见表一)。三星电子(Samsung Electronics)则维持亚军地位,市场占有率为11.7%。
表一、2016年全球收入前十大半导体厂商(单位:100万美元)

多家大型厂商均通过并购发展自己的业务,因此企业合并持续影响着厂商的市场占有率排名。2016年重要的并购包括安华高科技(Avago Technologies)收购博通公司(Broadcom Corp.)组成博通有限公司(Broadcom Ltd.)、安森美半导体(On Semiconductor)收购快捷半导体(Fairchild Semiconductor)、威腾电子(Western Digital)收购新帝(SanDisk)。前二十五大厂商名次变动最大的是博通,其市场占有率排名一口气攀升十二位,排名全球第五。
James Hines指出:“2016年,前二十五大半导体厂商总收入增加了10.5%,占整体市场74.9%,而其余厂商总收入却下滑15.6%。不过,这个结果由于受到2015与2016年大量并购活动的影响而有失偏颇。如果我们在必要时将2015与2016年每家被并购公司与并购公司的收入相加,那么前二十五大厂商的收入会增加1.9%,其余厂商的总收入则增加4.6%。”集微网
4.芯片战争2.0:“失效”的摩尔定律;
5月的上海阳光明媚,欧洲印制电路板(PCB)制造商奥特斯(AT&S)全球CEO葛思迈(AndreasGerstenmayer)的心情却有些沉重。
葛思迈在每年5月的财报季都会飞到中国,中国是奥特斯最重要的市场之一。但是由于重庆新工厂启动后产能未能达到目标,加之半导体封装载板面临巨大的价格压力,奥特斯去年总共亏损了2290万欧元,相比起上一个财年5600万欧元的盈利,利润大幅下滑。据悉,奥特斯在重庆工厂的投资总额高达4.8亿欧元,是该公司迄今为止最大规模的单笔投资。
奥斯特在中国工厂面临的困境也是摩尔定律增势减缓的真实写照。葛思迈表示:“随着市场发展放缓和需求降低,半导体封装载板的价格压力将持续增长,未来一个财年的业绩将继续受到影响。”不过他依旧乐观,随着技术优势的逐步显现,公司将最终一步步走向盈利。
奥特斯在下游芯片封装市场的举步维艰折射出整个产业链的困境。事实上,对于整个半导体行业而言,过去的一年都是极具挑战的一年。
放缓的脚步
英特尔联合创始人戈登·摩尔在1965年提出“摩尔定律”,预言半导体芯片上集成的晶体管和电阻数量将每年增加一倍。其核心是,芯片的性能将逐渐提升,成本将会逐渐降低。不过,在摩尔定律发展的50年来,在物理上生产出更小芯片的挑战正在逐渐增加。
葛思迈告诉第一财经记者,半导体产业技术的更新换代正在趋缓,尤其是在芯片处理器行业,10纳米的处理器进入市场的时间比奥特斯预计的要晚得多,因此相应的载板进入市场销售的计划也被推迟了。“目前市场上14纳米的处理器停留的时间比我们想象的要长得多。根据很多微处理器生产商之前的公告,照理说早就应该更新换代了。”葛思迈对第一财经记者表示,“一般来说每两年就会有新一代的CPU推出市场。但是到现在为止,我们看到这一次升级换代的步伐似乎放缓了很多,比原计划要晚一年半。”
确实,作为芯片行业的“老大”,英特尔的10纳米芯片的量产却经历了几次“跳票”。
英特尔正在不断调整制程工艺方面的衡量标准,从而在经济效益和芯片体积方面适应放缓的摩尔定律的发展节奏。最初,英特尔的产品更替周期是一年半,后来这一周期延长到2年,而最近的14纳米芯片在市场上停留的时间已经接近3年。
相关统计显示,该公司的制程工艺从45纳米变为32纳米花了大约27个月,从32纳米到22纳米用了28个月,从22纳米到目前的14纳米则用了30个月。从2014年9月开始,英特尔在制程工艺方面就再无进展。
英特尔方面对第一财经记者透露,新的10纳米芯片预计最终会在2017年下半年问世。业内预计,10纳米芯片在市场上的停留时间也将达到3年左右。尽管比10纳米更加先进的,被称为技术飞跃的7纳米芯片预计将会在2019年面世,但英特尔推出7纳米芯片可能要等到2020年左右。

摩尔定律失效了吗?
在英伟达等芯片企业看来,摩尔定律在十年前就开始失效,人工智能革命已经到来。CPU晶体管和能量大幅上升导致应用性能只有小幅增长。最近,其性能每年只增长10%,而过去每年的增幅为50%。英伟达认为,Dennard(登纳德)缩放效应遇到了元件物理的瓶颈。
尽管如此,一直将摩尔定律作为指路明灯的英特尔仍然坚信,其依然能够生产出更小、更快、更廉价的芯片,在今年上半年英特尔的技术与制造日上,英特尔副总裁StacySmith表示:“摩尔定律未死,至少对于我们来说是这样的。”
而事实上,对于英特尔而言,他们的战略方向也正在逐渐地转变。英特尔工艺架构与整合资深研究员MarkBohr表示:“英特尔不想再和三星、台积电玩‘数字’游戏了,以后英特尔要用密度度量法来定义工艺节点。”
如果采用这种标准来计算,英特尔最近几年都是以两倍的速度在提升晶体管密度。Bohr举例称,22纳米进化为14纳米的时候,晶体管密度提升了2.5倍,14纳米进化为10纳米时,密度又提升了2.7倍。“最重要的是,10纳米芯片在运算速度和功耗上有了较大进步。”Bohr表示。
由于近年来未能坚持此前几十年的惯例,也就是每两年就把晶体管的尺寸压缩一次,英特尔已经遭到了投资者和分析师的惩罚。过去五年中,英特尔的股价仅上升了28%,还不到标普500指数涨幅的一半。
Gartner分析师盛陵海对第一财经记者表示:“英特尔用摩尔定律推动技术发展的同时,实现了在通用处理器上的垄断。但现在,其最核心的追随摩尔定律的生产技术并不适合碎片化的市场,此外对投资领域的体量和利润要求也很高。”
公开信息显示,英特尔此前投资的一些项目并没有取得很大的效益,先后放弃了应用处理器、平板芯片、手机芯片和数字电视等领域。

整合加速
盛陵海对第一财经记者表示:“由于生产方面的技术进步放缓了,设计和软件方面的能力就更加重要了,这也加速了行业的整合。”
盛陵海解释道,原来由于利润分配情况还是不错的,各个产业链上的分支可以活得很好,但是现在不断地整合,原因就是要通过减少竞争对手或者整合产品的协同竞争力来提高利润。
过去两年中,芯片行业巨头的整合动作频频。2015年底,英特尔斥资167亿美元收购了可编程芯片厂商Altera,这也是英特尔历史上最大规模的收购。去年10月,高通更是以470亿美元的高价收购了欧洲的半导体巨头恩智浦(NXP)。恩智浦在2015年时则以118亿美元价格收购了另一家车载半导体巨头飞思卡尔(Freescales)。去年7月,ADI(亚德诺半导体)以148亿美元收购LinearTechnology(凌力尔特)。
今年以来,芯片巨头的收购烽烟再起。今年3月,英特尔以153亿美元收购了以色列信息技术公司Mobileye。5月26日,高通联合大唐电信旗下联芯科技,以及建广资本和智路资本,成立合资公司瓴盛科技(JLQTechnology),进军手机芯片低端市场,从而抗衡有英特尔入股的紫光旗下的展讯和锐迪科。早在今年2月,建广资本就已经完成了27.5亿美元收购恩智浦标准件业务。
眼下,日本半导体制造商东芝也急于出售半导体业务,作为全球第二大闪存芯片制造商,多家巨头虎视眈眈瞄准东芝半导体。其中不仅有东芝合作方西部数据以及美国芯片制造商、苹果供应商博通(Broadcom);也有韩国芯片制造商SKHynix(海力士)以及中国台湾的富士康母公司鸿海。
据彭博社报道,苹果也有意联合鸿海收购东芝,此前鸿海称愿意为收购支付3万亿日元,不过西部数据以“违约”为由阻止东芝向第三方出售芯片业务,并提起仲裁。结果将于今年下半年见分晓。

芯片版图之争
经过大规模整合,半导体行业中有能力制造最先进芯片的公司已从10年前的十几家变为如今屈指可数的几家。除了英特尔,目前这份名单上只剩下三星、台积电和2009年从AMD拆分出来的格罗方德。
三星正在与英特尔决斗,它们都想成为世界上最先进的芯片制造商。三星率先拥抱10纳米技术,英特尔却因为制造问题延迟。现在英特尔还在用14纳米制程制造芯片。
一份由麦克莱恩提供的最新报告显示,英特尔20多年来所保持的芯片行业老大的地位将被打破。受到市场不断增加的对内存和闪存需求的提振,三星在2017年一季度的芯片销量首次超过英特尔。而且未来由深度学习和机器学习所驱动的行业发展趋势将进一步催生对智能芯片的需求,英特尔能够成功转型变得非常关键。
三星的第一代10纳米芯片已经应用于今年稍早前发布的GalaxyS8当中,高通的骁龙835芯片也是三星现有的10纳米工厂制造的。
三星还在不断提升10纳米芯片的性能。公司已经在开发第二代10纳米芯片,并宣布今年四季度起将会用10纳米LPP(low-powerplus)技术生产芯片。据介绍,最新的10纳米LPP芯片采用增强型3D架构,比现有芯片速度快10%,而且能够节能15%。
虽然三星没有透露哪些客户会下单制造新芯片,但高通很可能将继续成为三星第二代10纳米芯片的大客户。苹果和高通的芯片需求占到三星整体出货量的一半左右。
螳螂捕蝉,黄雀在后。台湾半导体制造公司台积电也在积极参与到最高端的芯片制造领域。台积电CEO魏哲家透露,公司正在研发7纳米芯片,并且已经开始代工12种产品,2018年启动量产。业内预计,台积电生产的10纳米芯片或将成为苹果年内即将发布的最新款iPhone的独家供应商。
Gartner高级研究分析师DavidChristensen对第一财经记者表示:“快速的4G迁移与更强大的处理器使得晶圆尺寸大于上一代应用处理器,需要代工厂提供更多28纳米、16/14纳米与10纳米的晶圆。原有的制程工艺将继续在高集成度显示驱动芯片与指纹ID芯片以及有源矩阵有机发光二极管(AMOLED)显示驱动器集成电路(ICs)领域保持强劲增长。” 第一财经日报




