在诞生的第21天里,0号阿尔法狗就打败了60连胜的Master,Master后来战胜了国际围棋第一人柯洁。

#布告栏#10月26日20点,智东西主办的自动驾驶系列课第8课将开课,导师调整为图森未来CEO&联合创始人陈默。图森未来8月获NVIDIA投资,是NVIDIA在中国的第一个投资项目,也是其在自动驾驶领域首次出手。添加漠影(微信ID:hawkren002)免费报名,一起听陈默讲解低成本的商用车自动驾驶方案如何快速落地。
智东西 文 | Lina
智东西10月19日消息,今天,好久不见的AlphaGo团队又来搞事情了!谷歌DeepMind团队在《Nature》杂志网站上发布了迄今为止有关AlphaGo的第二篇重磅论文,它介绍了AlphaGo的新成员——AlphaGo Zero(0号阿尔法狗)。
0号阿尔法狗是继AlphaGo Fan、AlphaGo Lee、AlphaGo Master之后,AlphaGo家族的又一新成员,也是迄今为止最强大、同时也是最可怕的一个对手(最小的弟弟一般最强,没毛病)。
0号阿尔法狗在诞生36小时后,就成功打败了战胜柯洁的那只AlphaGo。它第一次让AI完全脱离人类历史棋谱,只通过围棋规则+“自我对弈”,在2900万次自我对弈后成长为世界上最强大的围棋大师。
最可怕的一点是,通过智东西对新一代AlphaGo Zero的深入挖掘,我们发现随着不断进化与变强,它变得越来越……简单了。不再需要那么复杂的各种策略网络、价值网路、快速走子策略等等,不再需要人类对它做出种种复杂的架构设计与数据输入,0号阿尔法狗只是像人类一样学习规则,然后不断练习,仅此而已。

这篇论文的题目也非常耿直,《Mastering the game of Go without human knowledge》,直译是“不需要人类知识就可以成为围棋大师”,意译过来大概就是……“人类,我不需要你了”。
在智东西公众号回复“zero”,获取论文原版下载!
一、AlphaGo的四世同堂

AlphaGo相比大家都已经非常熟悉了,是由谷歌旗下DeepMind团队的戴密斯·哈萨比斯、大卫·席尔瓦、黄士杰等开发的一款人工智能围棋程序。
2015年10月,职业二段樊麾与AlphaGO较量0:5败于对方,DeepMind团队将这只狗称为AlphaGo Fan,
2016年3月,AlphaGo曾以5:3战胜韩国棋手李世石,为了以示区分,DeepMind团队将这只狗称为AlphaGo Lee。

2016年12月底,AlphaGo身披“Master”马甲,5天内横扫中日韩棋坛,最终以60场连胜纪录告退。2017年5月,世界围棋第一人柯洁乌镇对战AlphaGo,三战全败,基本奠定了AI对围棋领域的统治地位,此时战胜柯洁的也是同一版的AlphaGo Master。
今天,DeepMind团队又给我们带来了AlphaGo Zero。
二、更简单、却更强大
虽然都叫AlphaGo,但是每一代AlphaGo都各有不同。跟它前面的三位“狗哥”比起来,0号阿尔法狗更加接近真正的“人工智能”概念。
拿第二代AlphaGo Lee为例,此前DeepMind团队在《Nature》杂志上发表的第一篇有关AlphaGo的论文中就详细介绍了AlphaGo Lee是怎么下棋的。这篇名为《用深度神经网络和树搜索掌握围棋博弈(Mastering the Game of Go with Deep Neural Networks and Tree Search)》中介绍的内容简单来说就是:
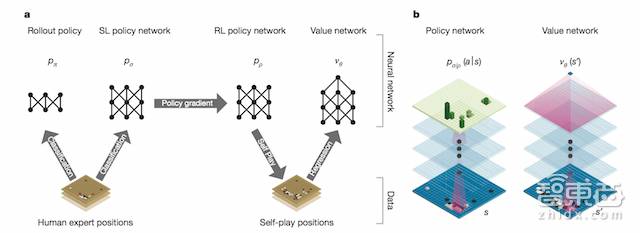
1)分析专业棋手棋谱,得到两个结果,快速走子策略(Rollout Policy)与策略网络(SL Policy Network)。其中快速走棋策略类似于人观察盘面获得的“直觉”,使用线性模型训练;策略网络则经过深度学习模型训练进行分析,类似于人类的“深思熟虑”。
2)用新的策略网络与先前训练好的策略网络互相对弈,利用增强学习来修正参数,最终得到增强的策略网络(RL Policy Network),类似于人类左右互搏后得到一个“更加深思熟虑”的结果,对某一步棋的好坏进行判断。
3)将所有结果组成一个价值网络(Value Network),对整个盘面进行“全局分析”判断,图中蓝色越深的位置赢面越大,这样可以让程序有大局观,不会因蝇头小利而输掉整场比赛。
4)综合“直觉”、“深思熟虑”、“全局分析”的结果进行评价,循环往复,找出最优落子点。
微软亚洲研究院主管研究员郑宇与微软亚洲研究院副研究员张钧波在多次论文阅读原文并收集了大量其他资料后,一起完成了一张更为详细的AlphaGo原理流程图,此处转载作以解释,版权归两位作者所有。
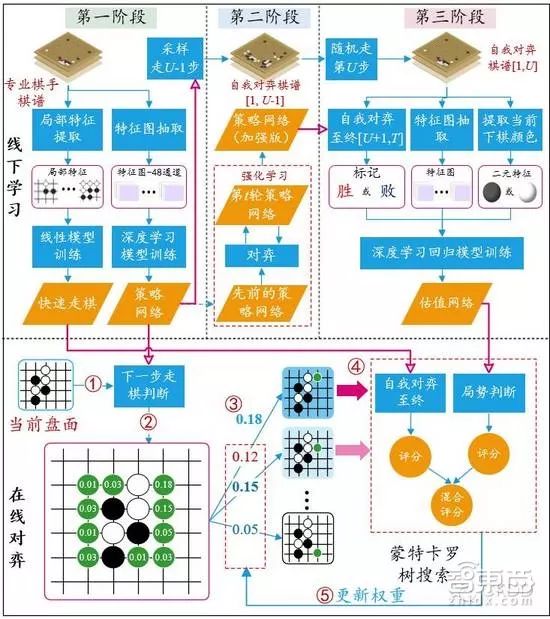
而第三代AlphaGo Master已经更多地依靠增强学习来训练AlphaGo,减少对人类棋谱的依赖了,篇幅问题这里不展开了。
最新,也是最强的这只“狗小弟”跟它的老大哥们比起来则有以下特点:
1)不需要分析专业棋手棋谱,只学习围棋规则,然后通过增强学习(Reinforencement Learning)进行自我对弈(2900万次)。
2)只使用一个神经网络,不需要以前的“策略网络”和“价值网络”。
3)不需要“快速走棋策略”,直接靠神经网络得出结论。
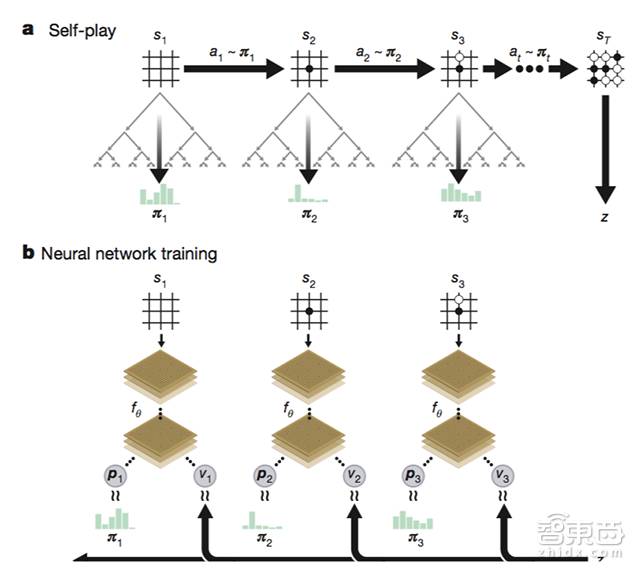
发现没有,随着AlphaGo的进化,它变得越来越……简单了。0号阿尔法狗不再需要那么复杂的各种策略网络、价值网路、快速走子策略等等,不再需要人类对它做出种种复杂的架构设计与数据输入,它只是像人类一样学习规则,然后不断练习,仅此而已。
而且,0号阿尔法狗和AlphaGo Master都只需要4个TPU,它们的“二哥”AlphaGo Lee则需要176个GPU和48个TPU,“大哥”AlphaGo Fan则需要176块GPU。
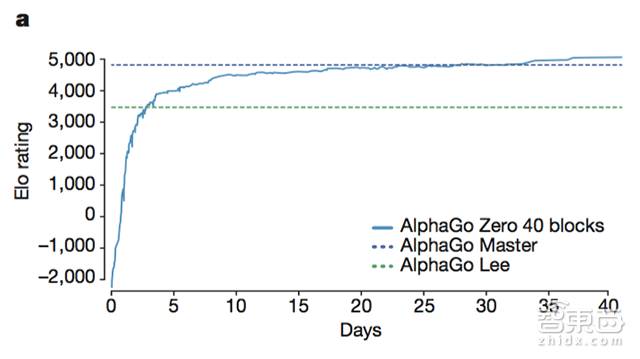
在诞生的3小时后,0号阿尔法狗知道怎么下围棋了。
在诞生36小时后,0号阿尔法狗打败了它的“二哥”AlphaGo Lee——以100:0的碾压战绩。
在诞生的第21天里,0号阿尔法狗就打败了60连胜的Master,Master后来战胜了国际围棋第一人柯洁。
在诞生的第40天里,0号阿尔法狗对战Master的胜率达到90%,成为最强的人工智能。
三、0号阿尔法狗的武功秘籍——“增强学习”
0号阿尔法狗之所以能够如此强大,最重要的就是“增强学习(Reinforencement Learning)”增强学习与我们常听说的“深度学习”不同,在深度学习里,你需要用大量的数据去训练神经网络。
比如你将一张车的图片给机器看,并且告诉它这是车,下次它就会说出“车”。如果你给他展现出别的,它还说车,你就告诉它“你错了。”久而久之的,它就能认出车来,原理其实很简单,但是对数据量的要求非常大。
而在增强学习中,相当于你不告诉机器下一步怎么走,等它随机执行了一轮操作后,如果结果是好的,那么给它奖励,如果结果是不好的,那么给它惩罚,但是不告诉它哪一步做错了,久而久之机器会自己摸索出一套最佳方案来。
增强学习极大减少了数据的依赖,尤其是在围棋这种规则明确的游戏当中,则更加适合增强学习发挥其强大的威力。因为它的环境条件非常简单(只有黑白棋),规则也非常简单,同时结果也非常简单(输赢平)。
四、英伟达和马斯克都在研究的黑科技
看完上面内容,是不是觉得AI已经太过“黑科技”,人类要完蛋了?
别担心。现在的的增强学习还暂时只能在步骤可能性较少、任务行为较窄的领域(比如围棋、简单物理运动等)发挥强大的作用。
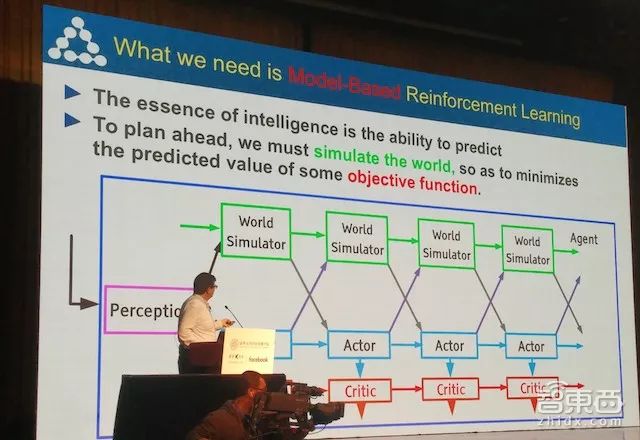
现在学术界的一个较为主流的观点是,训练机器进行增强学习需要建立一个世界模拟器(World Simulator),模拟真实世界的逻辑、原理、物理定律等。在这个虚拟世界里,天是蓝的、地是实的、掉下时重力会将你抓牢、玻璃会被打破……
想象一下,当你在这个世界里造出一个机器人来,虽然它不会走不会爬,但是将它放进这个世界里不断刺激、不断训练,会发生什么?这个机器人将会逐渐学会爬行、站立、奔跑,整个过程中人类只提供了一个初始参数,其他所有的训练都是靠这个机器人在环境中一次次的试错中不断完善的。
不过,由于真实世界太过复杂,存在大量的表征学习参数,想要打造出一个完全一模一样的虚拟世界几乎不可能,人类甚至连实际世界的1/10复杂都无法模拟出来。
但困难就是为了克服的,这事听起来很黑科技,但其实已经有不少人在做了。
拿英伟达为例,今年5月时,英伟达推出了一个用于训练机器人的增强学习世界模拟器——ISAAC机器人训练模拟世界(ISAAC Robot Simulator),创造出一个完全虚拟的、专为训练机器人而打造的世界。

这是一个遵循物理法则但不遵循时间法则的世界,在现实生活中,你想要训练一台机器学会打冰球,你要将这个冰球放在机器前面,一遍一遍地教会它;而在虚拟世界里,机器可以在一秒内重复众多次这样的动作,而且你还可以同时训练一堆机器学习打球,然后找到里面最聪明的一个,将它的“大脑”程序复制出来,创建一堆同样的机器再继续训练筛选。
此外还有OpenAI——OpenAI是Elon Musk于2015年12月宣布成立的非盈利AI项目,主要关注增强学习和无监督学习,科研人员会将大部分研究成果开源共享。5月15日,OpenAI发布了一款名为“Roboschool”的开源软件,用于训练机器。在这个虚拟环境中,科学家们还原了重力、摩擦力、加速度等不同元素。
视频中的机器人就是其中一个训练项目,它会一直不停地以并不熟练的姿势朝着球奔跑,而每当快要接近时,球的位置就会随机变化。偶尔它也会跌倒,接着自己学会爬起来。此外它还会一直不断被白色的立方体攻击,以推动运动轨迹变化。
结语:探索AI新疆域
打败柯洁的AlphaGo Master已经非常厉害了,没想到现在横空出世的AlphaGo Zero竟能在短短21天内就能打败Master,实在令人叹为观注。而且,它不但越来越强大,而且越来越简单,只是像人类一样学习规则,然后不断练习,仅此而已。
我们可以看到,随着深度学习的瓶颈日益凸显(需要大量带标注数据、泛化迁移能力不高等),包括英伟达、OpenAI等在内的学术界和产业界都在不断探索人工智能的新技术、新边界、新方法。
附:《Mastering the game of Go without human knowledge》论文摘要
长期以来,人工智能算法的目标就是让机器能够学习,在具有挑战性的专业领域,从婴儿般的状态(没有经验、知识基础)发展到超人类的级别。近期,AlphaGo成为了首个打败人类围棋世界冠军的程序。AlphaGo中的树形检索(tree search)可以利用深度神经网络评估棋局并进行落子,甚至能通过自我对弈实现强化学习(reinforcement learning)。本文(nature24270)介绍一种纯粹基于强化学习的算法,无需人类数据、指导或者超出游戏规则的专业知识。AlphaGo成为了自己的老师:建立了一个神经网络来预测AlphaGo的落子选择和比赛胜负方。这个神经网络强化了树形检索的能力,求解了更优的落子选择,并为下一次迭代提供了更强的自我对弈。从“婴儿”开始,我们的新程序AlphaGo Zero表现出了超越人类的“才能”,面对旧版AlphaGo——冠军终结者,战绩是100(胜)-0(败)。
在智东西公众号回复“zero”,获取论文原版下载!
自9月14日起,智东西重磅出品自动驾驶系列课,9堂课,9位顶级导师,9家自动驾驶领袖企业参与,810分钟讲解和互动,33个知识点,帮你建立未来汽车知识壁垒。扫码申请听课,同步加入自动驾驶社群。

点击下方图片直接阅读

要进群,请加小助手微信zhidx008
请备注相应群的关键词👇审核后邀请进入
人工智能 · 自动驾驶 · 机器人 · 物联网 · 智能家居 · 智能医疗 · VR/AR








