段晓晨,写过一点爬虫,写过几篇文章。能力虽有限,会尽量把想说的东西讲清楚。
知乎ID:段小草
知乎专栏:小段同学的杂记,
https://zhuanlan.zhihu.com/666666
提要:
这篇文章里我们会写:
1、如何对一个聊天机器人进行抓包分析接口;
2、如何将现成的聊天机器 API 部署到自己的公众号上;
3、如何实现接收语音消息并调用聊天机器人 API 自动回复文字;
4、如何让机器人根据上下文回复消息。
上篇文章的结尾,我们实现了如下的功能:
1、回复 快递xxxxxx 自动识别快递公司
2、发送图片 识别性别和年龄
3、其他文字信息 原样返回
其实结束在上次的文章就挺好的,因为已经实现了最重要的 token 验证,也尝试了如何处理文字和图片类型的消息,更多的功能和接口可以自己尝试开发,这次我们再扩展一下公众号的功能吧。
鹦鹉学舌的自动回复显然是不能满足实际需要的,最多也就用来测试消息能不能正常返回。但是自己设置关键字回复需要的规则又太多,所以我们选择对已有的聊天机器人进行抓包。
之前有主流的小黄鸡机器人,但是没找到官方的网页版。(小黄鸡提供付费 API )尝试使用
http://www.niurenqushi.com/app/simsimi/(虽然事实证明这个网站用的是图灵机器人的 API 而非小黄鸡 API ,后面我们会再谈 API 怎么用)
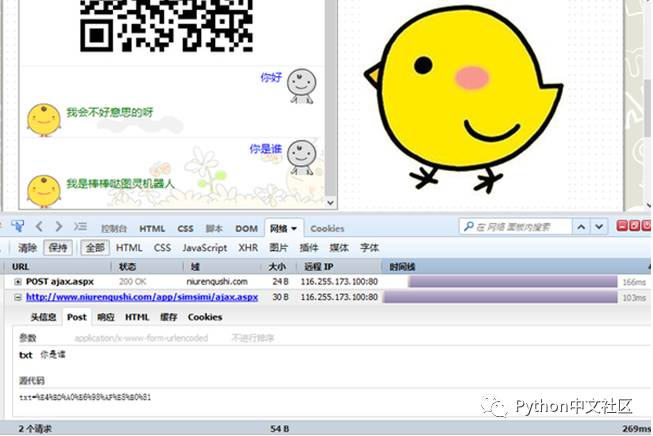
很简单的一个请求。
http://www.niurenqushi.com/app/simsimi/ajax.aspx?txt=
网址后面加上内容就可以了。
# -*- coding: utf-8 -*-
import requests
def talk(content):
s = requests.session()
r = s.post('http://www.niurenqushi.com/app/simsimi/ajax.aspx?txt='+content)
recontent = r.text
returnrecontent
#如果请求失败自己试试加上headers
抓到了自动回复的内容以后,我们将用户输入的文本内容当作 content 传入,获取回复再返回即可。
从小黄鸡的回复我们可以看出来,丫并不是小黄鸡,而是图灵机器人伪装的。与其给人刷请求量还不如自己去申请一个图灵机器人的 API ,可以自己定制很多东西。
http://www.tuling123.com/ 注册以后会分配自己的 key ,免费版每天 5000 次请求。
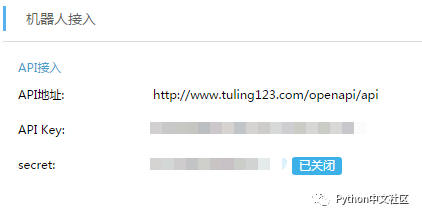
官方提供了几种接入方式,其中一种是微信公众平台接入,这种方法直接接入图灵机器人提供的链接而不是自己的服务器,所以对于公众号来讲定制功能的限定就很多,但是如果有小伙伴没有自己的服务器的话,可以用这个尝尝鲜。

我们已经搭好了 Python 环境的服务器,所以选择 API 接入。
http://www.tuling123.com/html/doc/api.html(推荐自己详细阅读文档)
下面是对 API 调用的 Python 代码:
存储为talk_api.py
(这里的重点是根据返回值中不同的 code 对相应返回的格式进行处理,否则会运行不成功或者返回信息不全)
# -*- coding: utf-8 -*-
import requests
importjson
global s
s = requests.session()
def talk(content):
url = 'http://www.tuling123.com/openapi/api'
da = {"key": "your API key", "info": content}
data = json.dumps(da)
r = s.post(url, data=data)
j = eval(r.text)
code = j['code']
if code == 100000:
recontent = j['text']
elif code == 200000:
recontent = j['text']+j['url']
elif code == 302000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
elif code == 308000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
else:
recontent = '这货还没学会怎么回复这句话'
returnrecontent
修改其中的 API key,然后修改之前的 weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
ifmsgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
kuaidi = cxkd.detect_com(post)
returnself.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
try:
msg = talk_api.talk(content, userid)
returnself.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), '这货还不够聪明,换句话聊天吧')
这样我们就实现了调用图灵机器人 API 微信公众号后台自动回复的功能。你可以在http://www.tuling123.com/web/robot_settings!index.action?cur=l_02 修改机器人设定,机器人后台会根据设定自动修改相应回复。
示例:
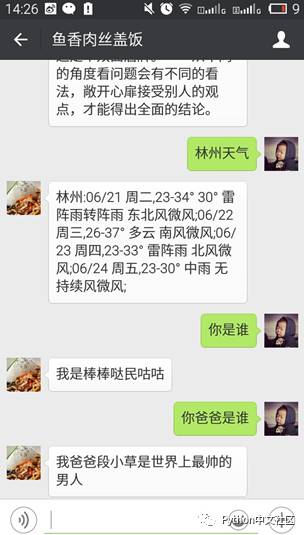
实现了文本信息的聊天以后我就在想,我们已经可以处理文本、图片了,能不能处理语音呢?
刚好看到微信官方提供了接口:
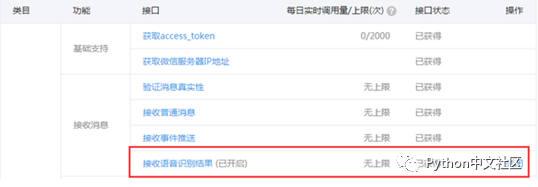

这就意味着我们不需要做太多的修改就可以将接收到的语音消息作为文本信息处理了。
修改weixinInterface.py
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
#picurl = xml.find('PicUrl').text
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
ifmsgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
elifmsgType == 'voice':
content = xml.find('Recognition').text
try:
msg = takl_api.talk(content, userid)
returnself.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), content + '这货还不够聪明,换句话聊天吧')
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
#result = cxkd.cxkd('PQ00708467161')
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+post)
h = r.read()
k = eval(h)
kuaidi = k["auto"][0]['comCode']
'''
j = requests.get('http://www.kuaidi100.com/query?type=huitongkuaidi&postid=280472503105')
l = j.text
#l = j.read()
#m = eval(l)
#outcome = ''
#for c in m['data']:
'''
#outcome = outcome + c['time']+' '+c['context']+'\n'
returnself.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
try:
msg = talk_api.talk(content)
returnself.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), '这货还不够聪明,换句话聊天吧')
这里重点就是加上了 elifmsgType == 'voice' 这部分。
示例:
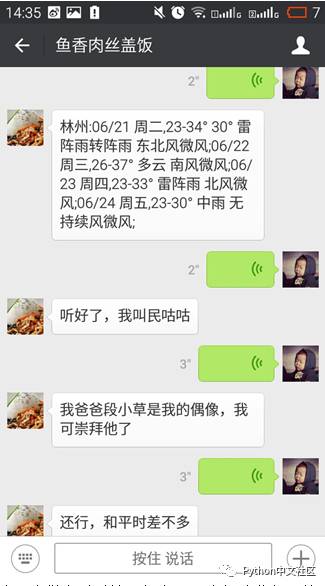
这一步做完以后就已经实现了大部分我想要的功能了,但还是有一点问题,因为机器人并不理解上下文的语义,所以会出现这样的情况:
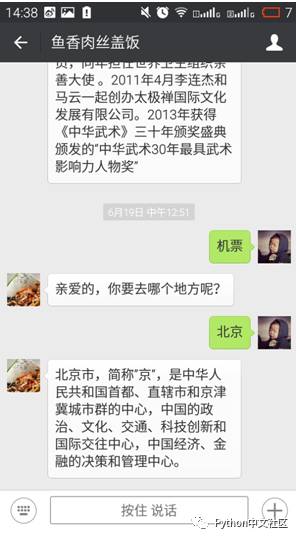
由于机器人并没有理解上下文语义,前一句话问你要去哪儿,你告诉他北京以后他却不知道你是因为什么回复的北京。所以要告诉机器人是谁在跟他聊天。
查看微信和图灵机器人的开发文档可以看到:
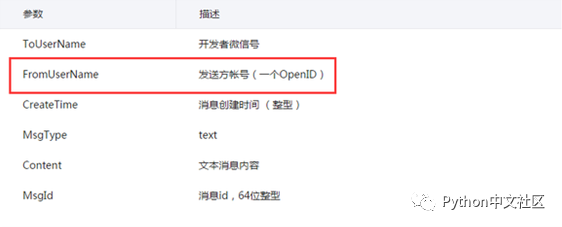
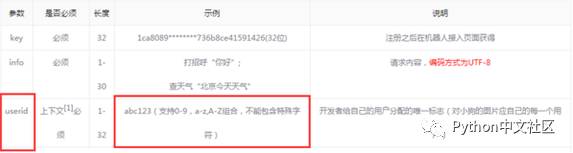
从微信接收到消息是,我们就能够获取到用户的 OpenID了,只需要将这个 ID 作为 userid 传给图灵机器人 API ,就可以保持上下文对话的语境了。(但是userid只支持0-9和数字,而微信 ID 中带有下划线,所以需要做一些简单处理)
修改talk_api.py (最终):
# -*- coding: utf-8 -*-
import requests
importjson
global s
s = requests.session()
def talk(content, userid):
url = 'http://www.tuling123.com/openapi/api'
da = {"key": "your key here", "info": content, "userid": userid}
data = json.dumps(da)
r = s.post(url, data=data)
j = eval(r.text)
code = j['code']
if code == 100000:
recontent = j['text']
elif code == 200000:
recontent = j['text']+j['url']
elif code == 302000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
elif code == 308000:
recontent = j['text']+j['list'][0]['info']+j['list'][0]['detailurl']
else:
recontent = '这货还没学会怎么回复这句话'
returnrecontent
可以看到,我们需要两个参数,content 和 userid 。
修改 weixinInterface.py(最终):
def POST(self):
str_xml = web.data() #获得post来的数据
xml = etree.fromstring(str_xml)#进行XML解析
#content=xml.find("Content").text#获得用户所输入的内容
msgType=xml.find("MsgType").text
fromUser=xml.find("FromUserName").text
toUser=xml.find("ToUserName").text
userid = fromUser[0:15]
#picurl = xml.find('PicUrl').text
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
ifmsgType == 'image':
try:
picurl = xml.find('PicUrl').text
datas = imgtest(picurl)
return self.render.reply_text(fromUser, toUser, int(time.time()), '图中人物性别为'+datas[0]+'\n'+'年龄为'+datas[1])
except:
return self.render.reply_text(fromUser, toUser, int(time.time()), '识别失败,换张图片试试吧')
elifmsgType == 'voice':
content = xml.find('Recognition').text
try:
msg = talk_api.talk(content, userid)
returnself.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), content + '这货还不够聪明,换句话聊天吧')
#return self.render.reply_text(fromUser,toUser,int(time.time()), content)
else:
content = xml.find("Content").text # 获得用户所输入的内容
if content[0:2] == u"快递":
post = str(content[2:])
#result = cxkd.cxkd('')
r = urllib2.urlopen('http://www.kuaidi100.com/autonumber/autoComNum?text='+post)
h = r.read()
k = eval(h)
kuaidi = k["auto"][0]['comCode']
'''
j = requests.get('http://www.kuaidi100.com/query?type=huitongkuaidi&postid=280472503105')
l = j.text
#l = j.read()
#m = eval(l)
#outcome = ''
#for c in m['data']:
'''
#outcome = outcome + c['time']+' '+c['context']+'\n'
returnself.render.reply_text(fromUser,toUser,int(time.time()), kuaidi)
else:
try:
msg = talk_api.talk(content, userid)
returnself.render.reply_text(fromUser,toUser,int(time.time()), msg)
except:
return self.render.reply_text(fromUser,toUser,int(time.time()), '这货还不够聪明,换句话聊天吧')
提交代码即可。
测试:
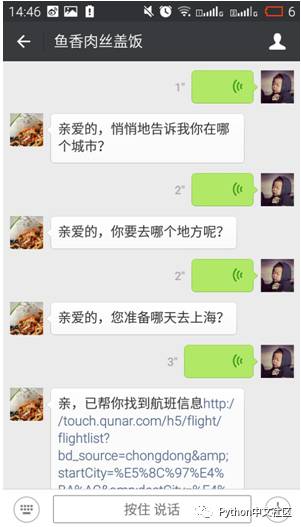
在下期Python开发微信公众号后台(系列四)中,将会谈到微信公众帐号开发者测试帐号初步体验高级接口以及没有认证的个人订阅号如何实现回复图片、语音等消息类型
⊙生成器:
关于生成器的那些事儿
⊙爬虫代理:
如何构建爬虫代理服务
⊙地理编码:
怎样用Python实现地理编码
⊙nginx日志:
使用Python分析nginx日志
⊙ 淘宝女郎:
一个批量抓取淘女郎写真图片的爬虫
⊙ IP代理池:
突破反爬虫的利器——开源IP代理池
⊙ 布隆去重:
基于Redis的Bloomfilter去重(附代码)
⊙ 内建函数:
Python中内建函数的用法
⊙ QQ空间爬虫:
QQ空间爬虫最新分享,一天 400 万条数据
⊙ 对象:
Python教你找到最心仪对象
⊙ 线性回归:
Python机器学习算法入门之梯度下降法实现线性回归
⊙ 匿名代理池:
进击的爬虫:用Python搭建匿名代理池
⊙ 发射导弹:
Python发射导弹的正确姿势
在公众号底部回复上述关键词可直接打开相应文章

Python 中 文 开 发 者 的 精 神 家 园
— Life is short,we use Python —
文章片头音乐为Cornfield Chase(原野追逐),星际穿越电影插曲,作曲家是Hans Zimmer,著名的音乐家,电影配乐作曲家,歌曲于2014年发行。
社区近期计划推出图文直播模块PyLive,如果您在Python开发、应用、研究等方面有一定的经验,请点击阅读全文,或将以下链接复制在浏览器:http://t.cn/RMXAIwd
填写表单申请PyLive主讲人。经过审核认可,将会发送PyLive策划书及相关说明至您的邮箱,我们尊重知识,并且始终相信知识是最有价值
的,PyLive主讲人也将获得丰厚的补贴,欢迎大家踊跃申请。如果您认为自己暂时还欠缺相关的经验,也欢迎将本消息转发给您认识的Python大牛,感
谢一路有你!
欢迎点击阅读原文,或者长按扫描以下二维码申请PyLive主讲人!











