此文没有太多分析和总结,只是尽量把公开的Wave的DPU的信息拿来介绍给大家,顺便用LeCun的NeuFlow对比了一下,不愿意花费时间的读者,可以只看Summary。
Sunmmary
Wave的DPU内集成1024个cluster。每个Cluster对应一个独立的全定制版图,每个Cluster内包含8个算术单元和16个PE。其中,PE用异步逻辑设计实现,没有时钟信号,由数据流驱动,这就是其称为Dataflow Processor的缘由。使用TSMC 16nm FinFET工艺,DPU die面积大概400mm^2,内部单口sram至少24MB,功耗约为200W,等效频率可达10GHz,性能可达181TOPS。
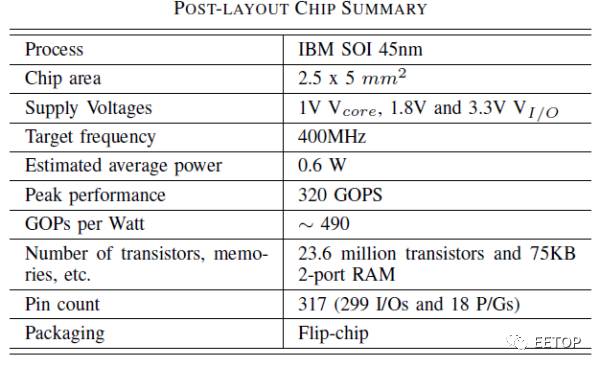
NeuFlow是2011年提出2012年实现的一种数据流处理器结构。使用IBM的45nmSOI工艺实现,面价12.5mm^2,内有75KB双口RAM,平均功耗0.6W左右,频率400MHz,峰值性能为320GOPS。
二者的相同点:都是dataflow处理器,都需要工具将神经网络结果映射编译到自己的架构上。二者区别:实现年代的区别导致二者在规模、计算能力和能效上区别很大。此外,产业化推进方面,Wave走的更好,毕竟是一个以盈利为目的的公司。
最近google也发表了关于TPU的论文,让脉动阵列又火了一把。可以说,脉动阵列的结构也是一种dataflow computing思想。关于TPU和脉动阵列,就不多谈了,有兴趣的自己找论文看吧。同时建议拿寒武纪的diannao系列的结构来对比一下。
想起上学时,一个师兄做学术报告讲用脉动阵列实现ECC,本学渣听得是一脸懵圈。本来脉动阵列就一知半解,ECC里各种逆天的数学公式、素数域、二元域、点加、点乘........。深度怀疑自己的智商啊。
DPU of Wave computing
wave computing 是一家成立于2010年的公司。原名wave semiconductor,于2016年改为wave computing。从改名可以看出Wave的战略变化,从最初的一家提供芯片的半导体公司,转变成一家提供计算技术解决方案的公司。Wave自己的声明也证明了这一点:
Wave的目的是提供一套可以加速Deep-Learning训练的系统,而不是出售芯片
。预计2017Q2发布评估系统(快到了,静候),年底出产品级系统。公司不仅希望他们的系统可以将现在基于GPU的神经网络的训练性能提高10倍,而且要在能效方面超过FPGA。
口号可以随便喊,有没有实力呢?从Wave的几个founder看,都是有多年业界经验的,分别在 bel labs、MIPS、CEVA等公司有过开发DSP和多核的经历。
Wave开发的芯片命名为DPU(Dataflow Processor)。Wave的机器内有四个DPU加硬件速板,每个DPU板上集成4个DPU芯片。Wave号称其硬件加速方案可以直接用于现有的数据中心的服务器架构中。
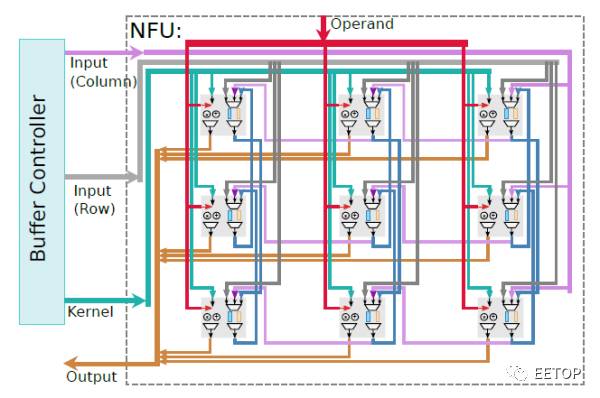
DPU的最大特色是:使用异步逻辑实现其基本计算单元PE。没有时钟信号,PE只要一收到操作数据,就触发计算,并得到结果。一个DPU PE结构如图,一个DPU内集成了16K个PE。每个PE都是独立的处理器,拥有自己的指令存储器、数据存储器、寄存器和处理单元。指令存储器可以保存256条16-bit指令,即512B大小的IRAM。pipeline的指令缓存可以每0.1ns发出一条新指令,相当于PE可以达到10GHz的峰值频率。每个PE拥有1KB的单口数据存储器,访问速度可以达到5GHz。前面说过,DPU内有16K个PE,也就是说,
一个DPU内有8MB的IRAM和16MB的DRAM
。有点恐怖。
本领域专业人员都知道,没有时钟树分布可以降低芯片面积和功耗。单个DPU die的面积是0.01mm^2,小于Cortex-M0。
PE内的8-bit逻辑单元可以执行比较、移位、旋转、逻辑与、逻辑或等操作
。逻辑单元的输出被锁存住,作为下一条指令的操作数,也可以送给其他PE,实现数据流模型。
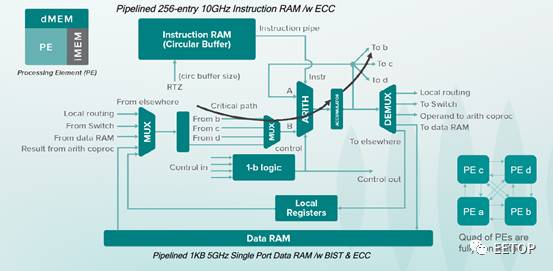
PE的结构图看了半天,也没找到MAC,这怎么玩?
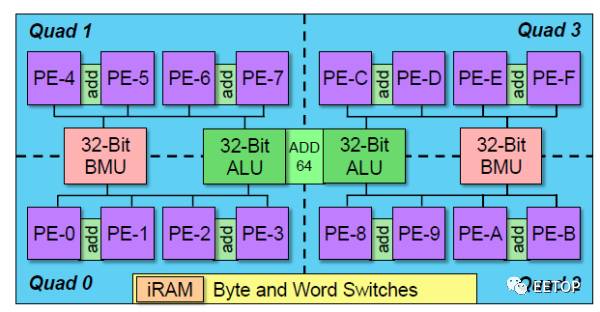
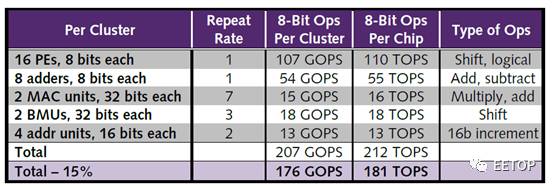
DPU内,每4个全连接的PE组成一个Quad,4个Quad组成一个cluster。每两个PE共享一个8-bit加法器。每个cluster内包含8个算术单元(包括2个32-bit MAC、2个32-bit BMU和4个16-bit加法单元),可以根据需要组成8/16/24/32/64bit操作。而且支持SIMD和MIMD指令。对比Wave披露的多份文档,可以知道更多细节。考虑到MAC和BMU(bit-manipulation unit)不是单周期的计算单元,估算chip可以达到181TOPS。如果进一步细分,只考虑MAC操作,可以达到8TOPS。从wave的描述看,每个Cluster都是一个独立的全定制的电路,对应独立的GDSII。
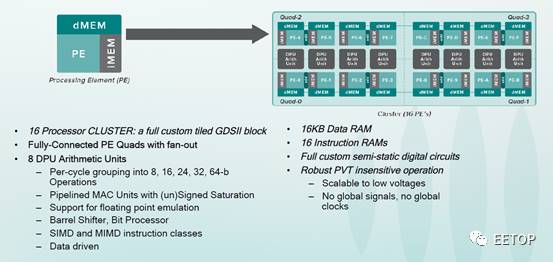
 下面,就是如何使用定制的Cluster来搭建整个计算阵列了。
下面,就是如何使用定制的Cluster来搭建整个计算阵列了。
Cluster之间的互联设计吸取了NOC的设计理念。每个Cluster都具有fanin和fanout的功能,每个cluster具有4个8bit的byte-switch和一个32bit的word-switch,可以通过指令来驱动cluster在多个方向的开关。每个Cluster可以接收保存临近的Cluster的数据,既可以自己使用,也可以直接透传给其他相连的Cluster。通过编译器,可以很好地调度cluster的计算以及数据通过cluster的传输,来实现各种算法。
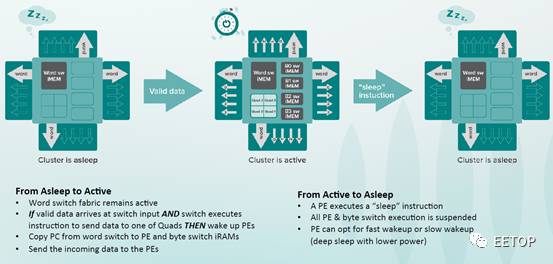
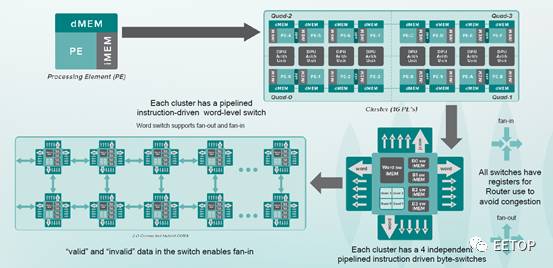 可以通过sleep指令控制cluster进入低功耗模式。在低功耗模式下,cluster内的PE和byte-switch都将停止工作,但是word-switch保持工作状态,以支持数据的传输。当存在有效数据传入同时有word-switch指令将数据发送给cluster内部的Quad时,cluster内部PE被唤醒进行计算。
可以通过sleep指令控制cluster进入低功耗模式。在低功耗模式下,cluster内的PE和byte-switch都将停止工作,但是word-switch保持工作状态,以支持数据的传输。当存在有效数据传入同时有word-switch指令将数据发送给cluster内部的Quad时,cluster内部PE被唤醒进行计算。
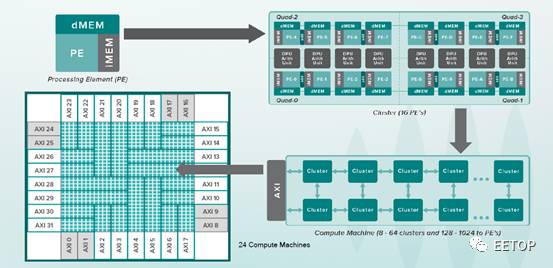
 在一个DPU芯片内,集成了1024个cluster,组成32x32阵列,并分割成24个区域。每个区域包含32或64个cluster,称为一个compute machine。每个compute machine拥有独立的128-bit的AXI 总线接口。DPU通过一个基于AXI4的网络,实现24个接口与memory、IO的互通。此网络支持32个AXI4总线,可以达到410GB/s的峰值带宽。由于缺乏细节,本人也不知道多出来的8个AXI4总线是如何使用的。
在一个DPU芯片内,集成了1024个cluster,组成32x32阵列,并分割成24个区域。每个区域包含32或64个cluster,称为一个compute machine。每个compute machine拥有独立的128-bit的AXI 总线接口。DPU通过一个基于AXI4的网络,实现24个接口与memory、IO的互通。此网络支持32个AXI4总线,可以达到410GB/s的峰值带宽。由于缺乏细节,本人也不知道多出来的8个AXI4总线是如何使用的。
 DPU内部网络上还连有一个32 bit 的Andes N9的微处理器,负责配置芯片。八卦一下,Andes刚在台湾IPO了,不容易啊。
DPU内部网络上还连有一个32 bit 的Andes N9的微处理器,负责配置芯片。八卦一下,Andes刚在台湾IPO了,不容易啊。
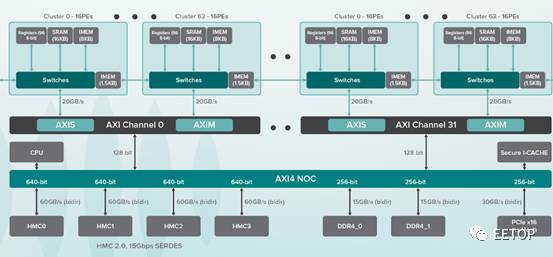
DPU使用四个HMC接口将数据装载到芯片内。每个HMC接口可以提供240GB/s的峰值带宽,每个HMC器件可以支持2GB的容量。此外,DPU还有两个64-bit DDR4-2400接口,可以进一步支持更大的存储容量,以及一个16-lane的PCI-E Gen3接口,可以与主机或其他外部网络相连。
 Wave表示,使用TSMC 16nm FinFET工艺,DPU
die面积大概400mm^2,功耗约为200W
,封装管脚接近2000个。此前,Wave的CTO Nicol曾表示,Wave在28nm上的测试芯片可以在实验室跑到11GHz。
Wave表示,使用TSMC 16nm FinFET工艺,DPU
die面积大概400mm^2,功耗约为200W
,封装管脚接近2000个。此前,Wave的CTO Nicol曾表示,Wave在28nm上的测试芯片可以在实验室跑到11GHz。
总结一下DPU的关键参数,如下。

从公开渠道获得的数据来开,WAVE的DPU可以将AlexNet的训练时间降到12分钟,而NVIDIA的GPU需要120分钟。针对Inception网络的训练数据显示,Wave可以实现25倍的加速。
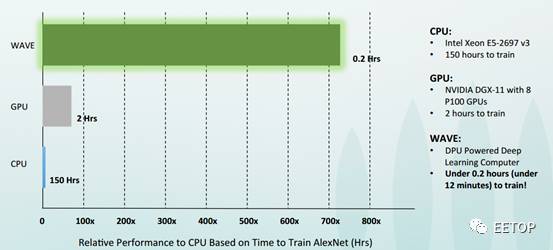
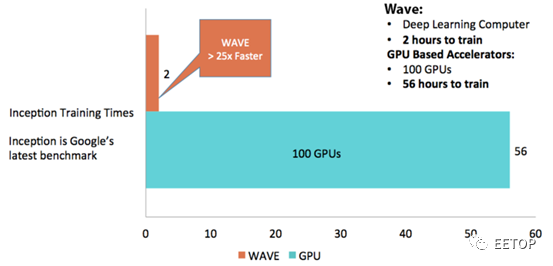
有迹象显示,Wave的野心不止是在训练环节与NVIDIA争一杯羹。但是,要想与NVIDIA竞争,WAVE除了将性能和能效做好,还需要提供强大的软件平台,包括lib、framework等。可以说,wave任重而道远,让我们拭目以待吧。
NeuFlow Arhcitecture
既然LeCun评论里提到了他自己的NeuFlow,只好也去翻出来学习一下(发散式学习,受不了了,何时是个头啊)。
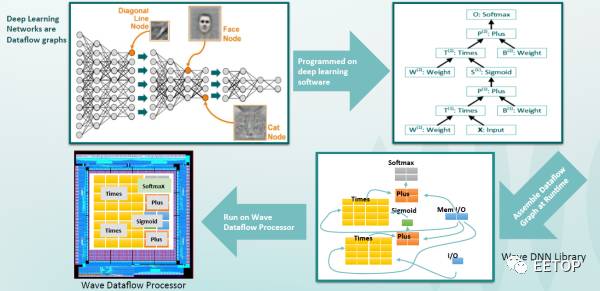
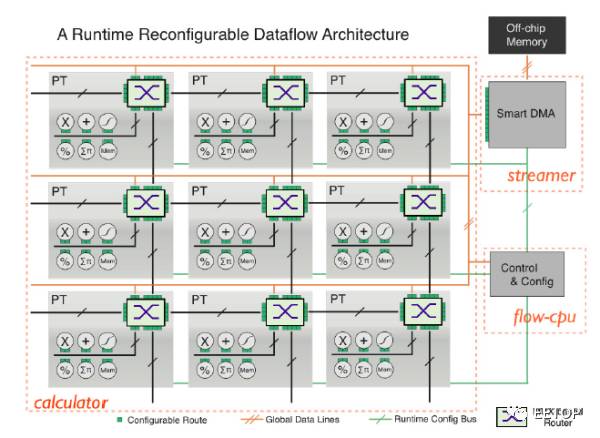
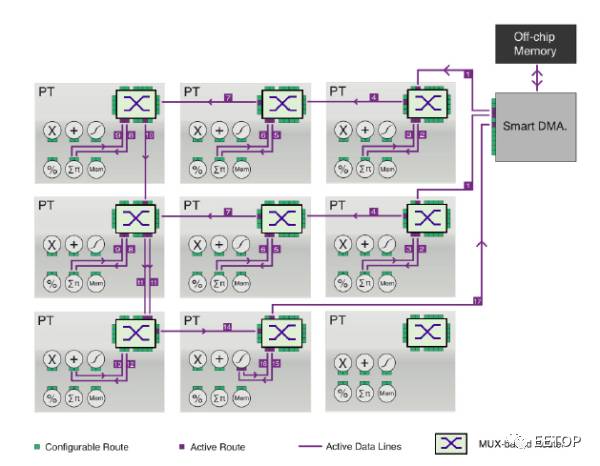
Neuflow结构是一种运行时可重配置的数据流结构。上述DPU也是运行时可重配置的,只是没强调而已。如图所示,NeuFlow由三部分组成。calculator、streamer和flow-cpu。
calculator是计算部分,包含由多个PT(processing Tile)组成的2D网格。通过一个基于MUX的路由,每个PT都和相邻的PT相连,或者和全局数据总线相连。PT中的操作和模块可以是一种或多种:流操作(加、减、乘、除、最大值),基于MAC的1D/2D并行卷积器(
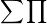 符号)或点乘操作,用于缓存流数据的可配置的FIFO,以及线性或非线性功能。这些操作彼此之间互联,并且可以通过基于MUX的路由与全局数据或相邻PT相连。运行时对PT的互联进行配置,就可以支持各种数据流图。
符号)或点乘操作,用于缓存流数据的可配置的FIFO,以及线性或非线性功能。这些操作彼此之间互联,并且可以通过基于MUX的路由与全局数据或相邻PT相连。运行时对PT的互联进行配置,就可以支持各种数据流图。
streamer管理数据流,是一种灵活的DMA模块,负责从片外memory中提取数据。可以配置DMA配合给定的stride,直接访问2D数据流中特定的数据块,并将状态反馈给Flow-cpu。
flow-cpu作为中心控制单元,负责在运行时对streamer的DMA模式和calculator中的PT Grid进行重配置。
下图为NeoFlow 2D 结构的一个配置实例。其中,PT中的卷积器为1D的3个MAC组成的卷机器。第一行3个PT实现3x3的卷积操作,中间行3个PT实现另外一个卷积,左下PT对卷积结果求和,中下PT实现激活函数。
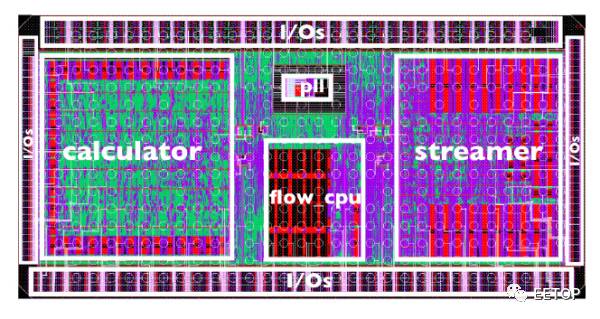
 NeuFlow在IBM SOI 45nm工艺下的芯片版图是这样的。其中,calculator中有4个卷积器,支持10x10的卷积核。共有75KB双口RAM。
NeuFlow在IBM SOI 45nm工艺下的芯片版图是这样的。其中,calculator中有4个卷积器,支持10x10的卷积核。共有75KB双口RAM。
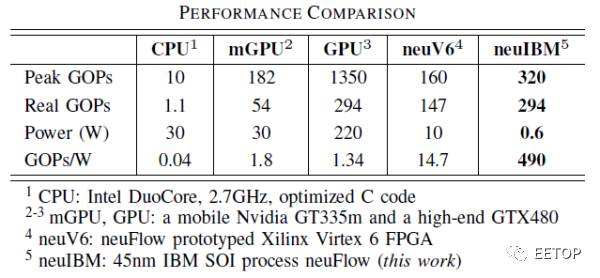
最后简单给出NeuFlow与其他芯片的性能比较,
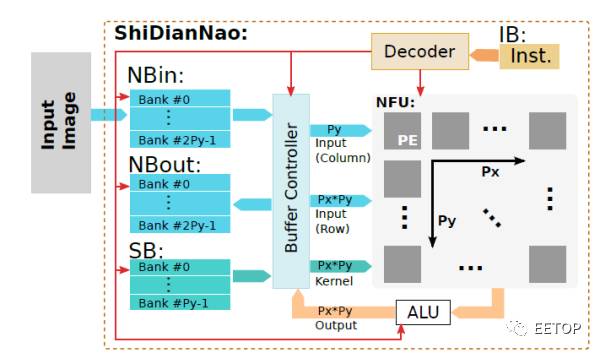
寒武纪shidiannao和google TPU
最后,留点开放性问题。感兴趣的可以去对比一下寒武纪的diannao系列的计算阵列的结构,以及google TPU的计算阵列结构,看看和上面的两个dataflow processor相比有什么不一样。看完之后,有没有对dataflow architecture和systolic array之间的关系有点晕?从paper给的结构图看,怎么有点像呢?
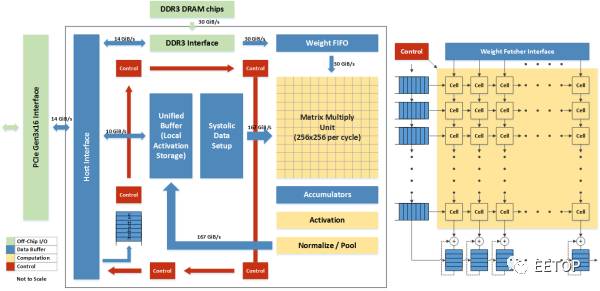
TPU结构如图。
寒武纪的shidiannao结构如图。