treelake
,
Python中文社区专栏作者
项目Github地址:
https://github.com/zr777/school-wiki
项目总体简介请看
用Python搭建一个校园维基网站(一)
本文可独立使用,创建了一个可编辑内容的首页,展示了wagtail的一些基础用法。文末为本文所创项目文件github地址。 比较详细,新手可尝试,不过最好有一定Django基础。
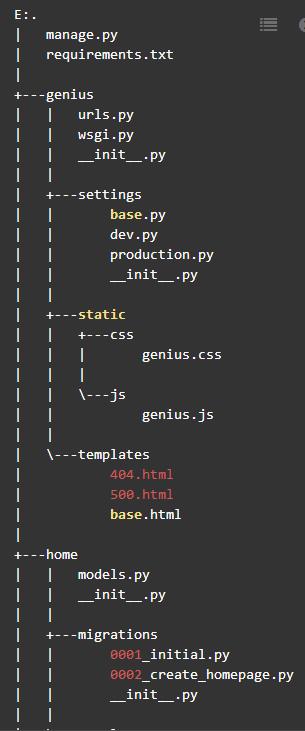
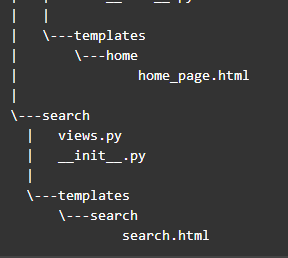
项目结构概观
1、
manage.py
是
Django
项目通用的管理脚本(通过
python manage.py 某命令参数
使用)。
2、
requirements.txt
用于存储当前项目的依赖列表(自动生成的为
Django
和
wagtail
,虚拟环境(virtualenv)下可用
pip freeze >> requirements.txt
追加)。
3、
genius
包含项目主要信息,有主路由(
urls.py
)、wsgi接口(
wsgi.py
)、配置文件夹(分基础配置
base.py
、开发环境配置
dev.py
与生产环境配置
production.py
,后二者依赖基础配置)、全局静态资源文件夹(
static
)与模板资源文件夹(
templates
)。
4、
home
是自动生成的
app
文件夹,包含了
models.py
页面数据模型和
templates
模板文件夹。默认生成的
models.py
中定义了一个简单的
HomePage
类(继承自
wagtail
的
Page
类)来代表一个页面(即默认的欢迎页)的模型(该简单模型的可编辑内容部分只有
title
字段)。在
wagtail
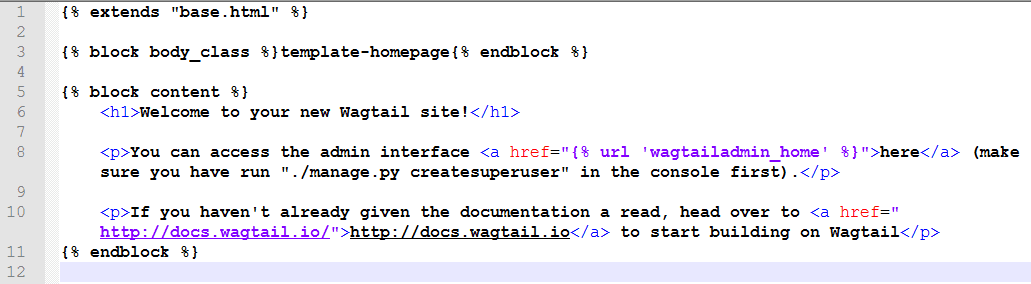
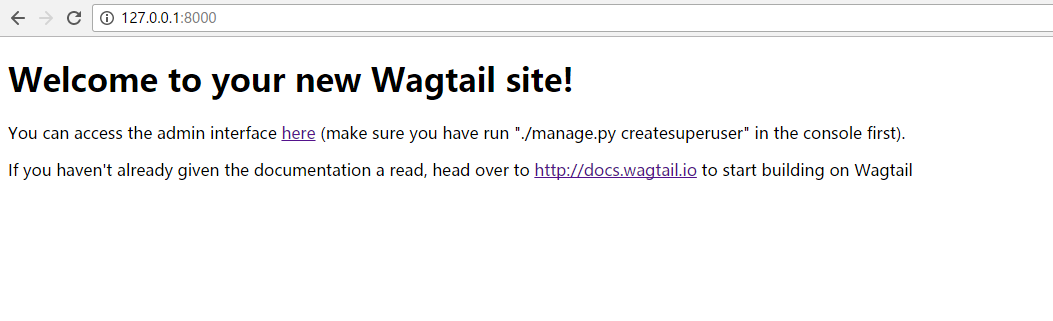
的概念中,页面模型和模板文件是默认关联的,如
HomePage
默认对应的模板为
templates/home/home_page.html
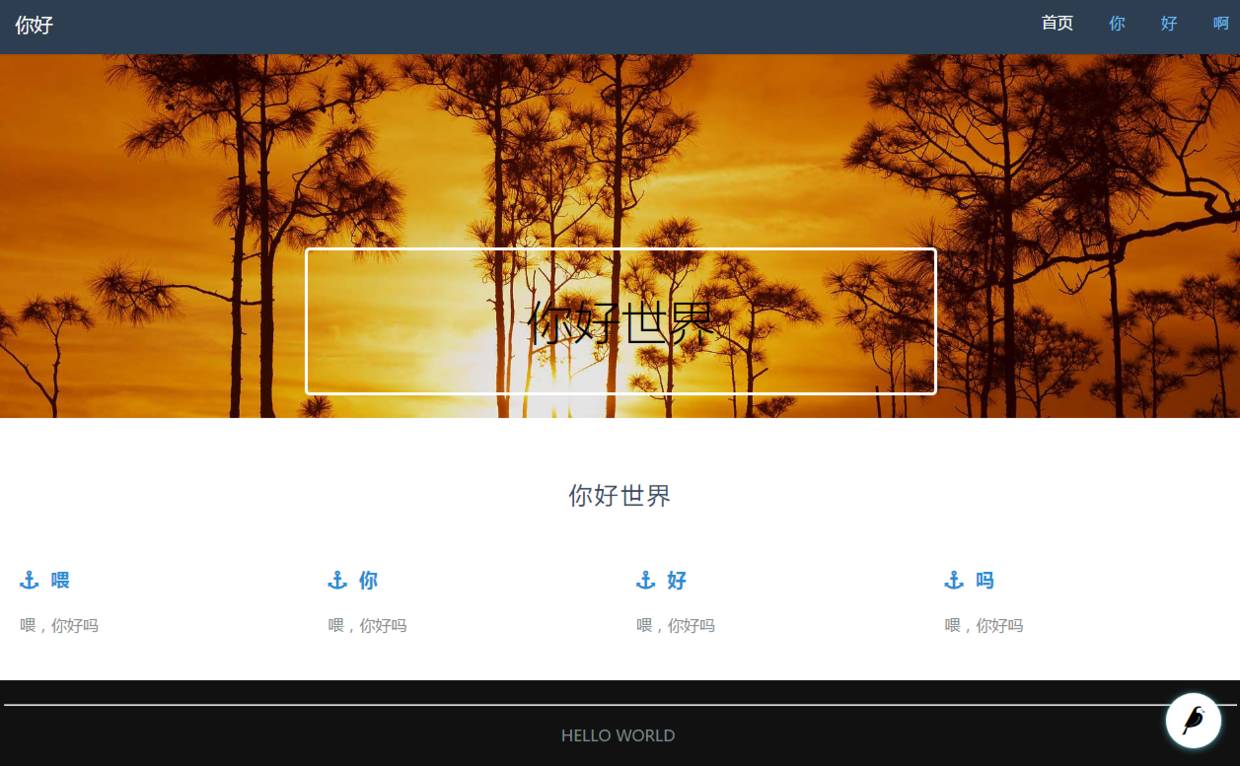
(注意命名的转换关系),而欢迎页
http://127.0.0.1:8000
中的大部分内容就在该模板中(该模板使用
extends
语句继承
genius\templates\base.html
,并使用
block
语句填充相应内容)。如下:
5、
search
则是自动生成的提供搜索功能的
app
文件夹,由于基于
wagtail.wagtailsearch
所以只包含了
views.py
视图文件和
templates
模板文件夹。暂时不管。
创建wiki主页
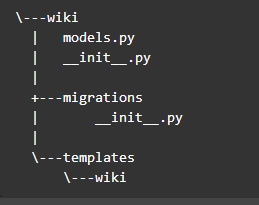
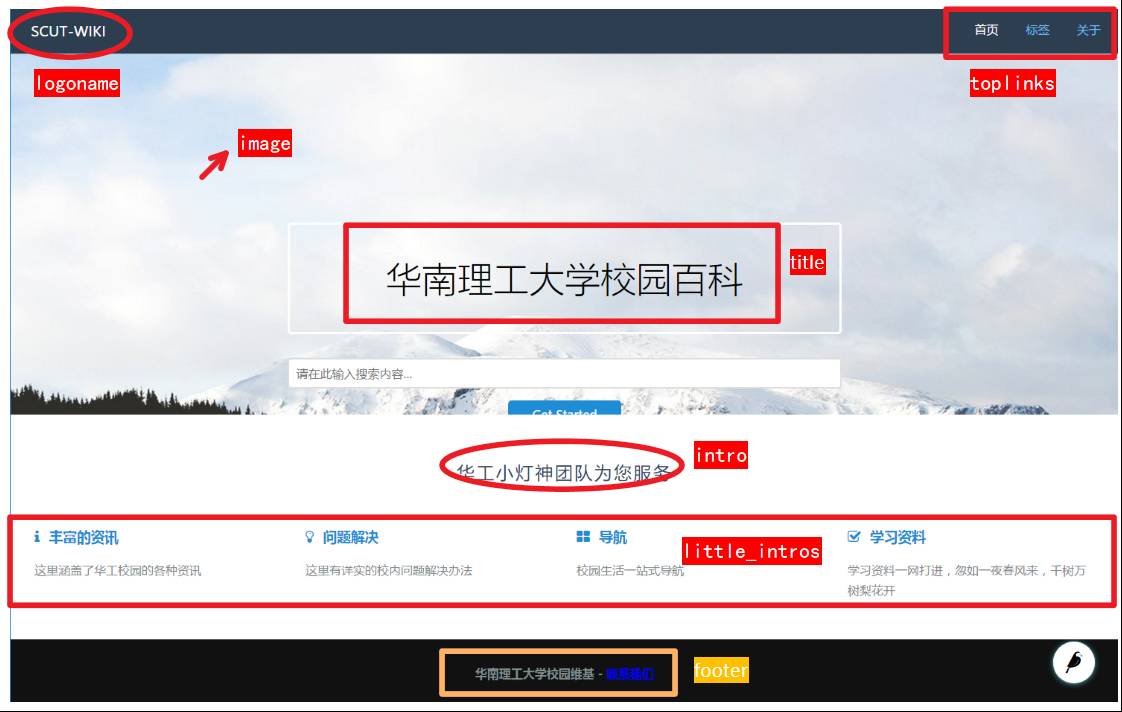
我们的
WikiHome
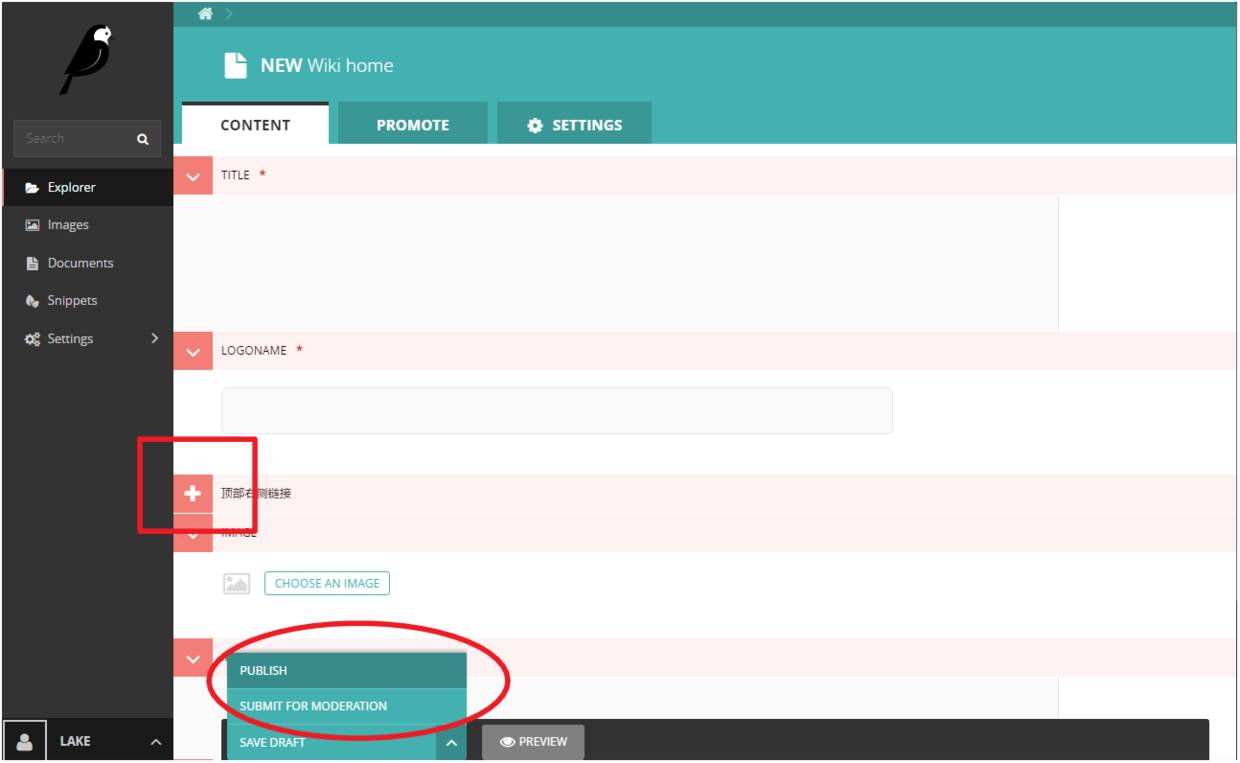
页面模型中需要图中红色高亮的一系列字段,其中
title
字段继承自
Page
类,不用额外添加,
image
字段为连接到
wagtailimages.Image
模型的外键。
content_panels
列表提供了该页面模型在后台管理编辑页面的呈现内容。
此外,对于
TopLink
和
LittleIntros
我们需要另外新建两个继承
wagtail
提供的
Orderable
(使有序)的非页面模型。
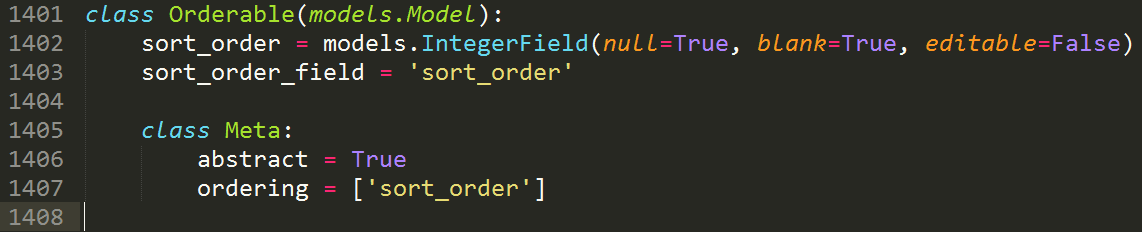
WikiHomeLittleIntros
的字段有
fontawesome
图标类名,小标题和简述,如下图。还包含了一个
wagtail
提供的对
ForeignKey
进行了一层封装的
ParentalKey
外键连接到它所属的
WikiHome
页面。类似的,
panels
表明出现在可编辑区。

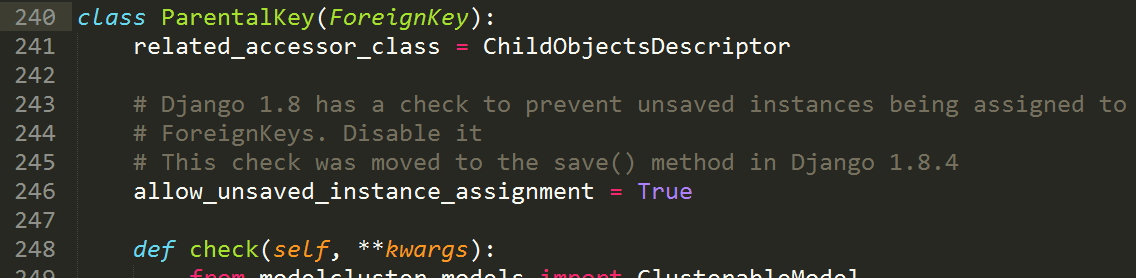
WikiHomeTopLink
类似,为了层次上更清晰,采用了多重继承,在
models.py
中只定义
ParentalKey
外键,而在另一个文件中定义了
RelatedLink
模型,包含的字段有链接文本和具体链接,只是具体链接可能为外链、某个页面或某个文档,占用了三个字段,此外还利用
@property
装饰器为该模型添加了
link
属性,来返回它的具体链接,这样在模板中就可以使用
.link
调用。
综上,
models.py
的内容因篇幅有限,代码已上传至社区小密圈,可点击阅读原文下载。在
models.py
旁新建
umodels.py
文件供
models.py
引用:

它有一系列现成的
layouts
供我们使用,选择最适合本次主页的样式,查看源码可以得到详细的信息,在这里,为了简便,我们直接使用了该
layout
的额外样式表的链接(最好处理为本地的
css
样式文件,使用
Django
的
static
标签引用)。
对于模板来说,它对应的页面模型处于它的上下文环境,在模板中可以调用到该页面模型中的所有元素(使用
Django
的模板语言)。我们要按照页面排版将元素填充进去。
修改
wiki_home.html
中内容(因篇幅有限,代码已上传至小密圈,点击阅读原文下载即可)。
-
这样,大致就成功了,但是模板中倒数几行里的
{% load wiki_tags %} {% wikihome_footer %}
还没有实现,它就是之前图中黄色框圈住的页脚了。考虑到页脚的内容一般比较固定,我们使用snippets和模板标签tag的形式来实现。它使得我们既可以在管理控制页面修改该页脚的内容,也使得页脚具有自己的一小段html模板,可以简便地被其它模板所调用。
-
在
wiki
文件夹下的
models.py
文件旁新建一个
snippets.py
文件
实际上,它还是创建了一个
Django
模型,只包含了一个富文本字段,但是利用
Wagtail
提供的
register_snippet
装饰器我们可以简便地将其注册到管理界面,以便在管理界面修改。但是,还不能在模板中调用它,我们需要将它注册到
Django
的
tag
标签系统中,在
wiki
目录下新建
templatetags
文件夹,在该文件夹下新建
wiki_tags.py
文件,添加如下内容。同样,借助简单的装饰器注册了该模板标签,且与
wiki/tags/footer.html
片段模板绑定,并提供
footer_text
作为上下文。
然后就该创建对应的片段模板文件了。与上面代码中绑定的
html
文件路径对应,在
wikiapp
目录下新建
templates\wiki\tags\footer.html
文件,添加如下内容:
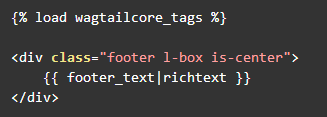
好了,主页的所有代码部分都结束了。让我们尝试运行。在项目根目录下执行:
登录管理界面:
http://127.0.0.1:8000/admin/
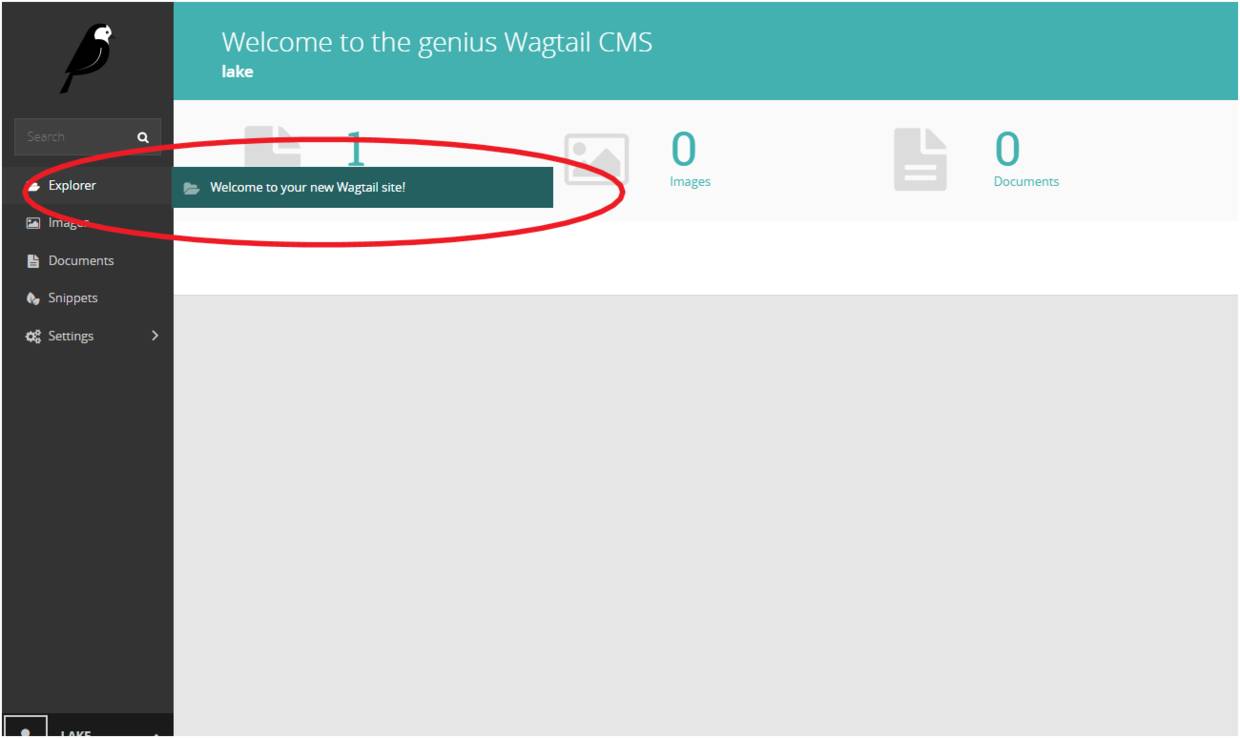
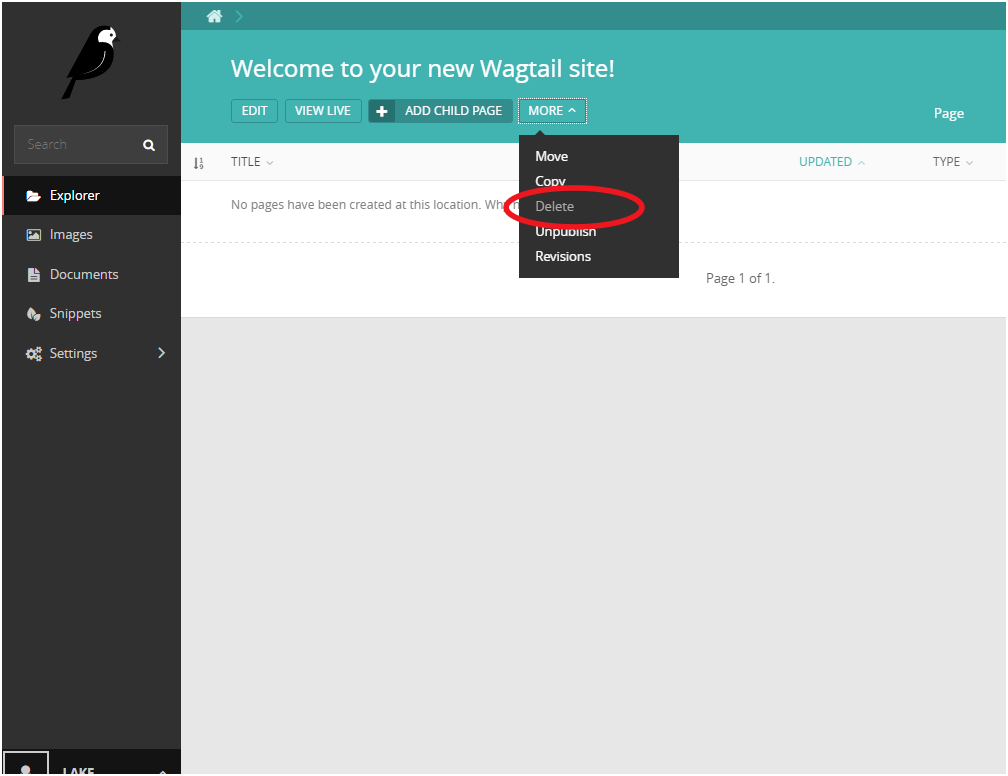
点击红圈部分来到如下图页面,删除默认页面。
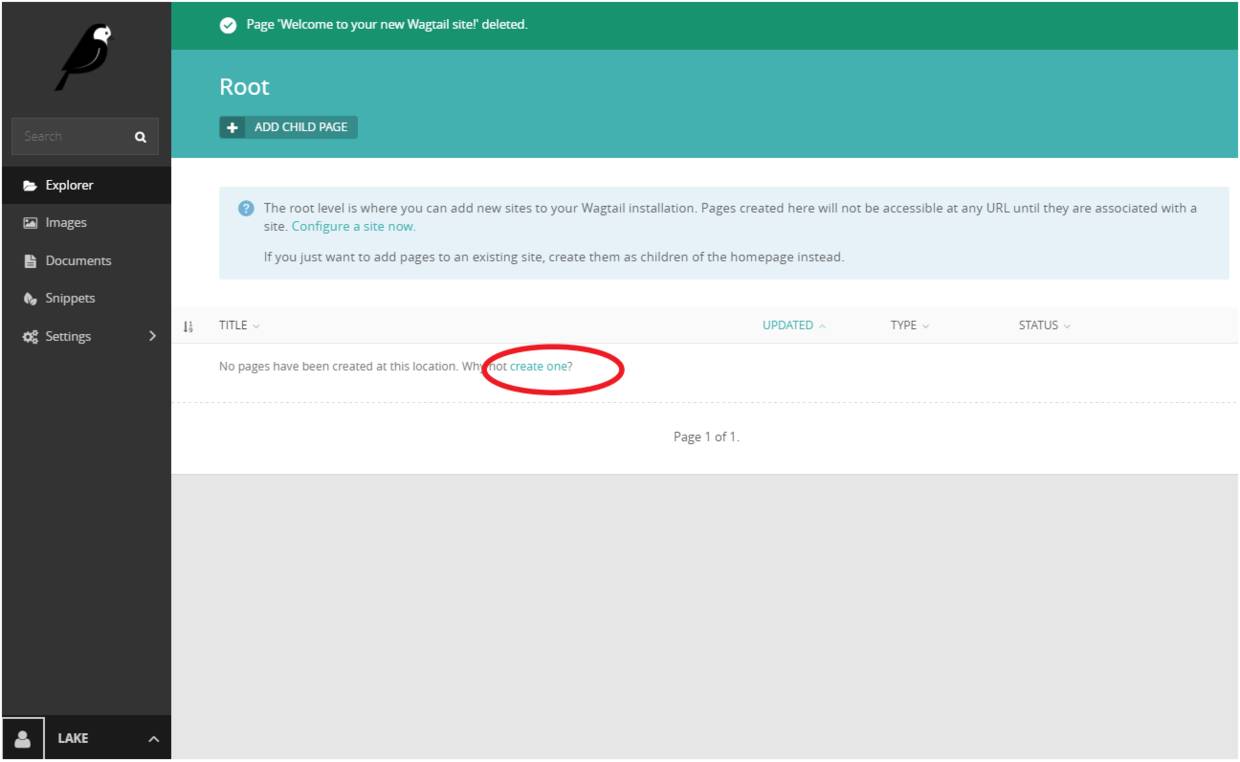
确认删除后,选择在根目录下新建页面
这时便来到我们的创建的WikiHome模型的页面元素填写界面,依次填写后按红圈处Publish提交。