选自DeepMind
作者:Shane Legg等
机器之心编译
参与:吴攀、黄小天、李亚洲
DeepMind 和 OpenAI 是现在人工智能研究界最重要的两大研究机构,当其联手时,我们能看到什么样的成果诞生呢?近日,一篇题为《Deep reinforcement learning from human preferences》的论文让我们看到这样的努力及其成果——提出了一种基于人类反馈的强化学习方法。该论文在 arXiv 发布后,DeepMind 和 OpenAI 各自通过博客对这项重要成果进行了解读,机器之心在本文中对 DeepMind 的博客及原论文的摘要进行了编译介绍。
更多详情请参考以下链接:
原论文:https://arxiv.org/abs/1706.03741
DeepMind 博客:https://deepmind.com/blog/learning-through-human-feedback/
OpenAI 博客:https://blog.openai.com/deep-reinforcement-learning-from-human-preferences/
DeepMind 推荐的扩展阅读:https://arxiv.org/abs/1606.06565
我们相信人工智能有一天将成为最重要、最裨益人类的科技进步之一,帮助应对人类面临的最艰难的那些挑战,比如全球变暖、普惠医疗。但是在实现这一切之前,我们必须负责任地发明人工智能技术,并考虑到所有潜在的挑战和危险。
所以,DeepMind 联合发起了「构建全球人工智能伙伴关系,造福人类与社会」(Partnership on Artificial Intelligence to Benefit People and Society)等倡议,专门组建了一个团队研究技术上的人工智能安全。这一领域的研究需要开放、协作,从而保证最佳的实践得到最广泛地采用。这就是为什么我们与 OpenAI 展开合作,推进人工智能安全的技术性研究。
人工智能领域的核心问题之一是人类如何做到告诉一个人工智能系统我们想要它做什么——以及更重要的——我们不想要它做什么。当我们运用机器学习处理的问题变得越发复杂并进入实际应用领域时,这一核心问题的重要性也与日俱增。
通过允许没有技术经验的人教授强化学习系统(一个通过试错进行学习的人工智能)一个复杂的目标,我们合作的最初结果给出了一个解决方案。这就不再需要人类特意为了算法的进步去指定一个目标了。这一步很重要,因为在获取目标方面的微小差错也可能导致不想要的、甚至是危险的行为。有时,一个非专家仅仅 30 分钟的反馈就足以训练我们的系统,包括教授系统全新的复杂行为,比如如何使一个模拟机器人做后空翻。

通过从被称为「奖励预测器(reward predictor)」神经网络训练智能体,而不是让智能体在探索环境中搜集奖励,这个系统(我们的论文 Deep reinforcement learning from human preferences 描述了它)摈弃了传统的强化学习系统。
该系统由三个并行运行的流程组成:
一个强化学习智能体探索环境并与之交互,比如 Atari 游戏。
一对 1 - 2 秒的行为片段定期地回馈给人类操作员,以供其选择出完成既定目标的最佳智能体。
人类的选择被用于训练奖励预测器,预测器进一步训练智能体。智能体不断学习最大化来自预测器的奖励,并根据人类表现提升其行为。
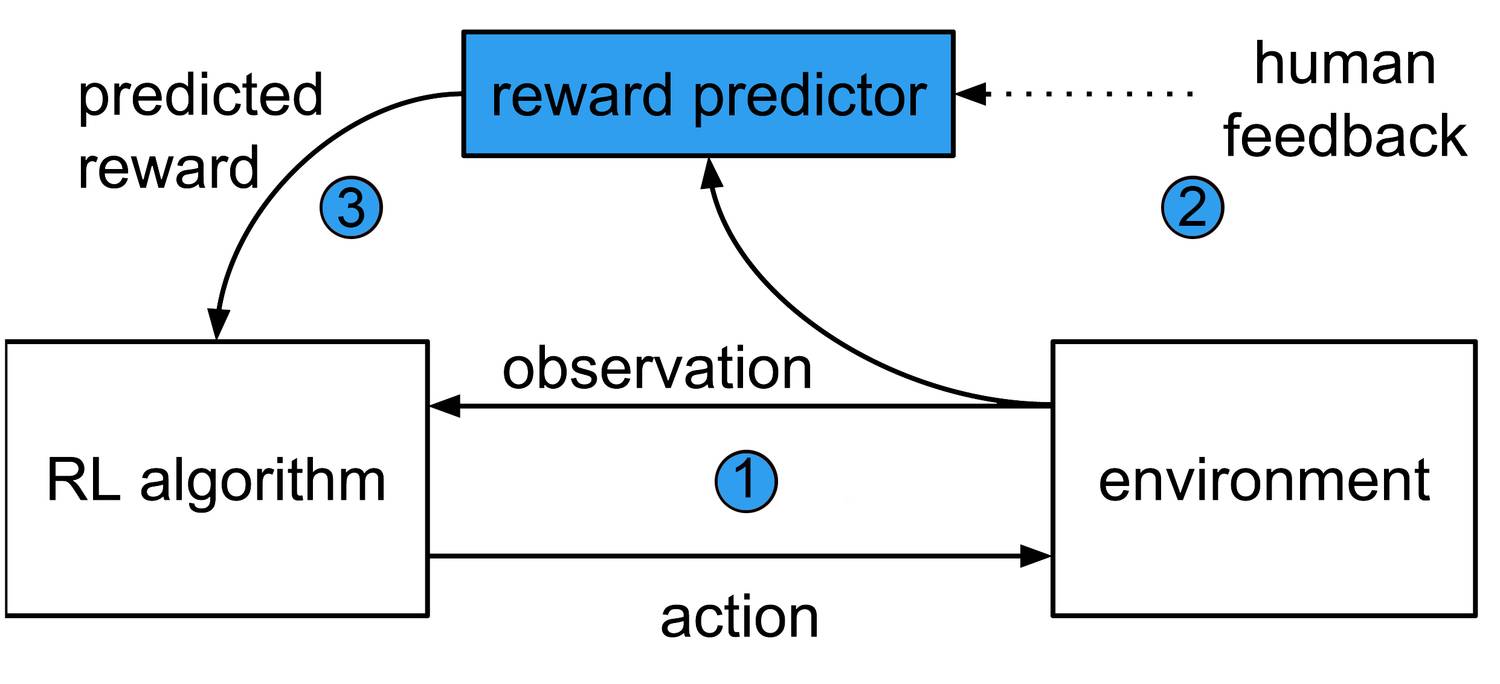
这个系统将目标学习从行为学习中分离了出来,以使其能实现该目标。
这种迭代式的学习方法意味着人类可以指出并纠正任何非预期的行为,这是所有安全系统的一个关键部分。这个设计也不会给人类操作员增加繁重的负担,他仅需要回顾该智能体 0.1% 的行为,就能让该智能体执行他想让它做的事。但是,这仍然可能意味着需要回顾数百到数千对行为片段(clip);而如果要将其应用到真实世界中,还需要将这一数字继续减小。
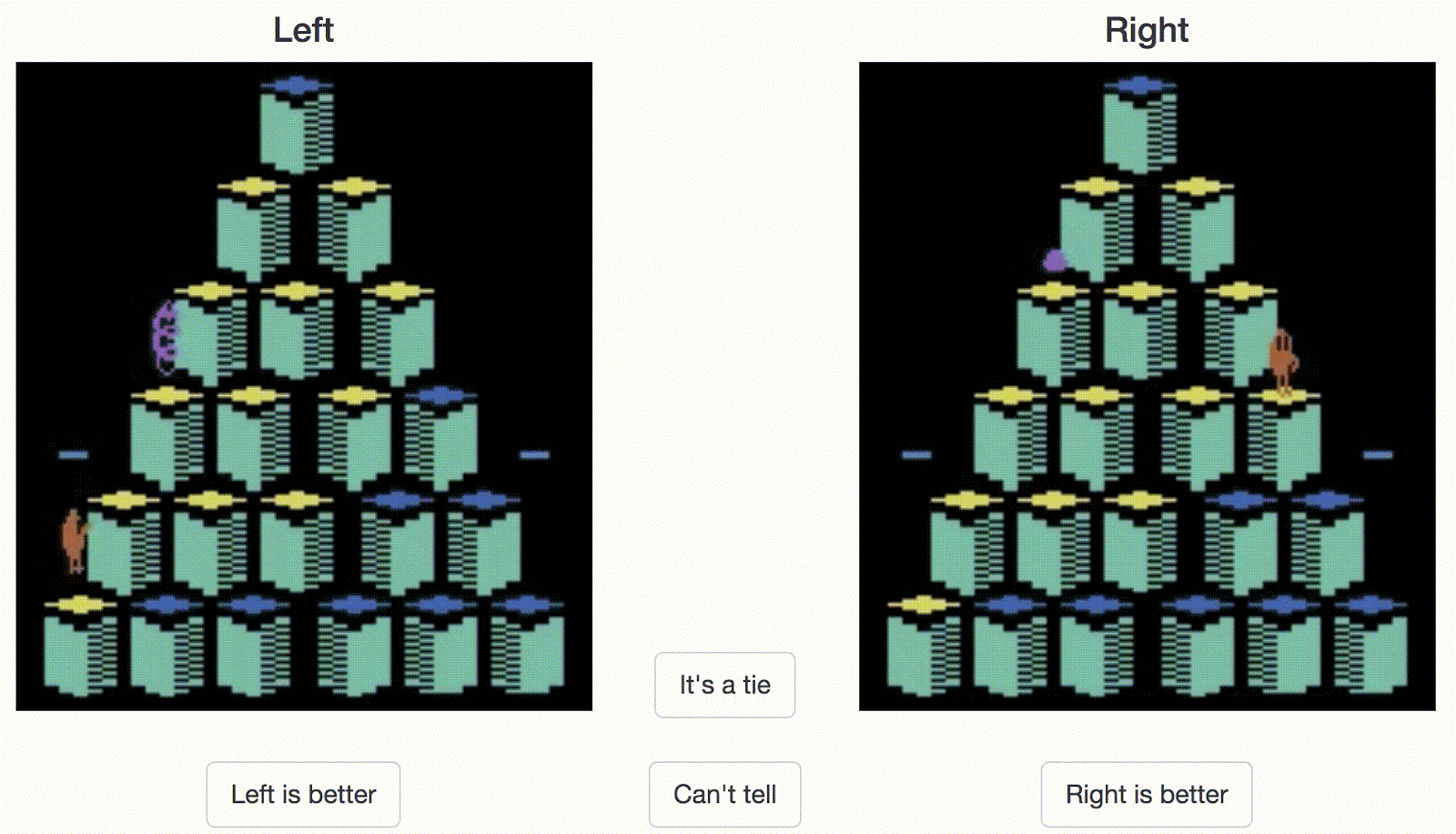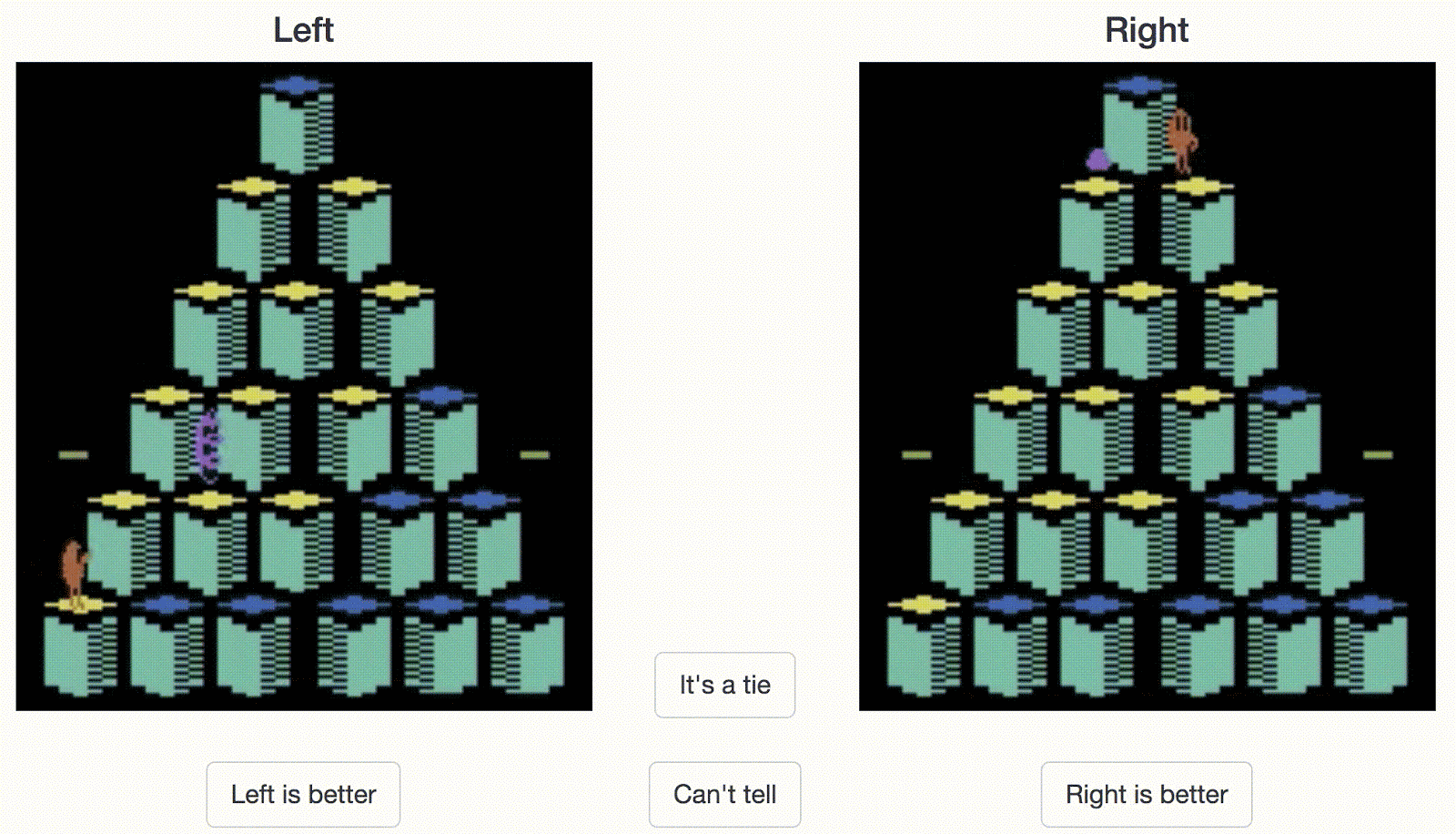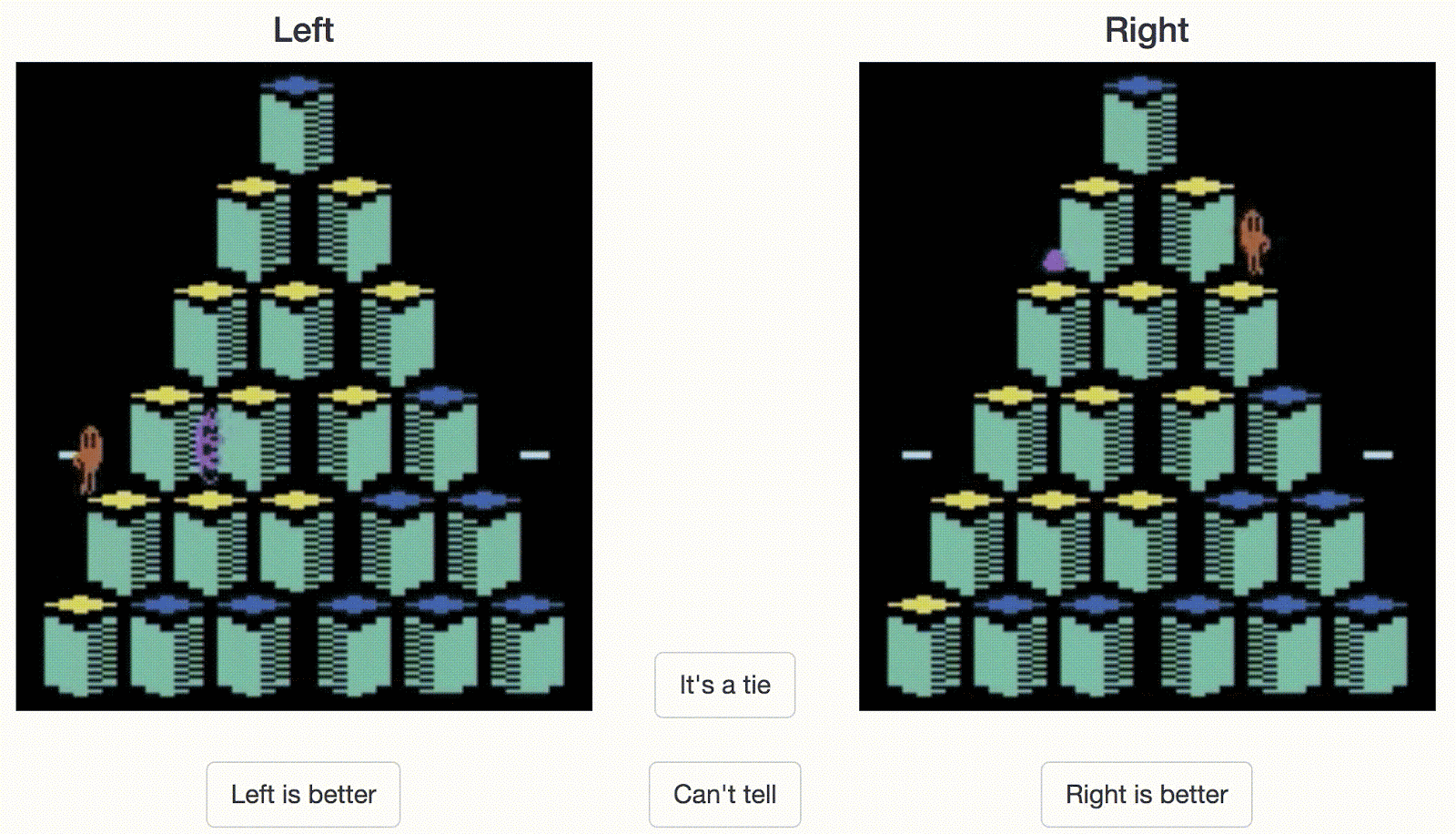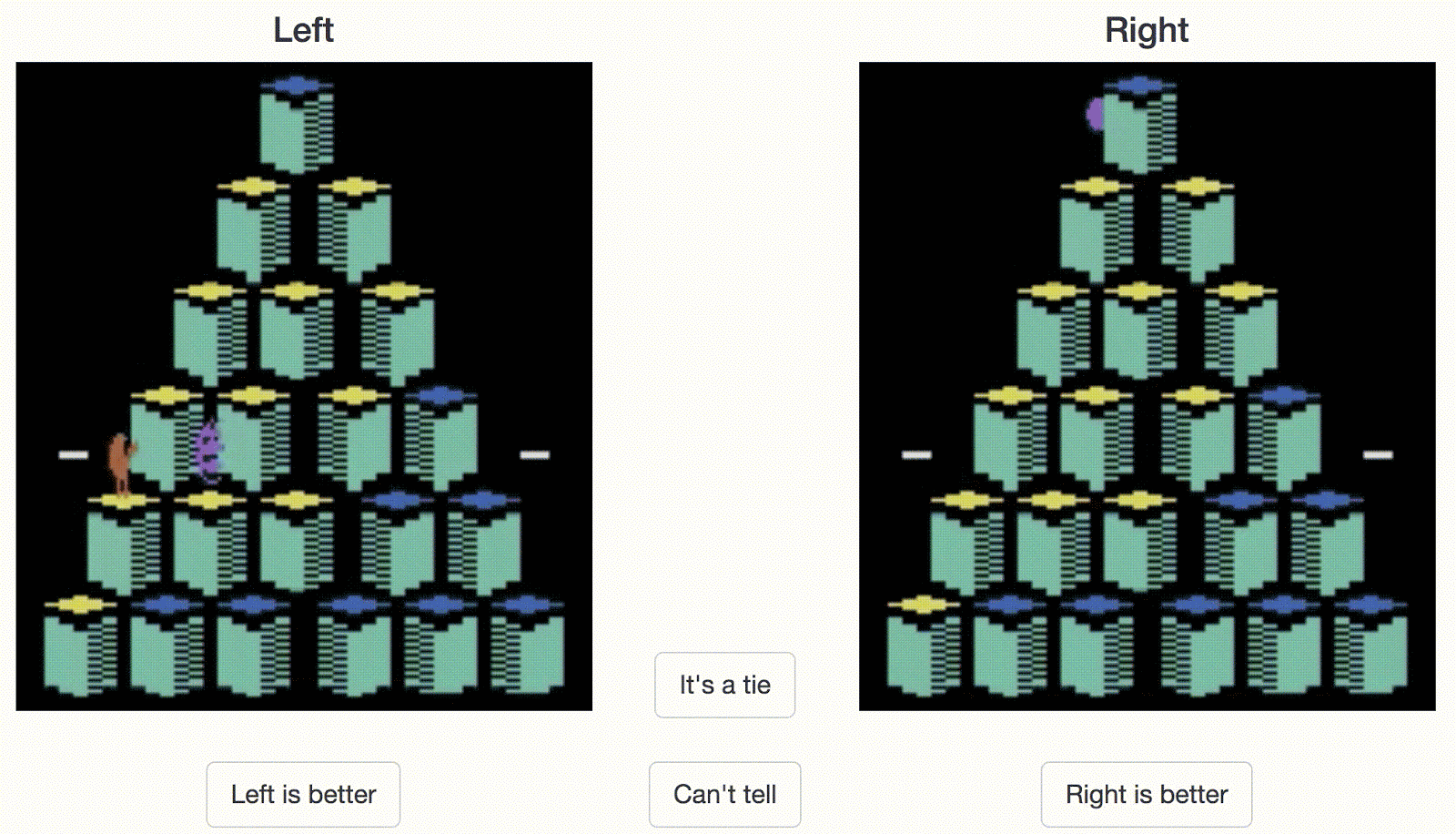
人类操作员需要在两个行为片段之间做出选择。在这个 Atari Qbert 游戏的例子中,右边的片段表现出了更好的行为(分数更高)。
在 Atari 游戏 Enduro 中,玩家需要驾驶汽车赶超其它车。通过传统的强化学习网络的试错技术,智能体很难学会这种行为;而人类反馈最终让我们的系统实现了超越人类的结果。在其它游戏和模拟机器人任务中,它的表现可以和标准的强化学习配置媲美,而在 Qbert 和 Breakout 等几个游戏中,它却完全没有效果。
但这种类型的系统的最终目标是让人类可以为智能体指定目标,即使当该智能体不在其需要工作的环境中时。为了对此进行测试,我们教会了智能体多种全新的行为,比如执行一次后空翻、单腿行走或在 Enduro 游戏中与其它车并驾齐驱(而不是赶超对方以最大化得分)。

Enduro 游戏的普通目标是尽可能赶超更多的车。但使用我们的系统,我们可以训练智能体追求不同的目标,比如和其它车并驾齐驱
尽快这些测试显示出了积极的结果,但也显示了其缺陷。特别是,如果在训练中很早就停止了人类反馈,我们的设置容易受到 reward hacking 的影响,即在奖励函数上胡乱猜测。在此场景中,智能体继续对环境进行探索,意味着奖励预测器被迫预测没有反馈场景的奖励。这会导致对奖励的过度预测,诱导智能体学习错误的(且往往是陌生的)行为。从以下动图中的例子也可以看到,智能体发现来回反复击球是比得分或失分更好的策略。

该智能体修改调整了它们的奖励函数,并决定出来回反复的击球要比得分或丢分更好
理解这样的缺陷,对我们避免失败、建立想要的人工智能系统而言很重要。
在测试并增强这个系统上,还有许多的工作要做。但在创造由非专业用户教授的系统上,这是非常重要的第一步,节省了用户需要向系统给予反馈的数量,且可扩展到各种各样的问题上。
其他领域的探索包括减少所需要的人类反馈,或赋予人类通过自然语言接口给予反馈的能力。这可能标志着创造能从复杂的人类行为进行学习的系统的跃阶性变化,也是迈向创造与人类协作的人工智能重要一步。
本研究论文是 DeepMind 的 Jan Leike、Miljan Martic、Shane Legg 以及 OpenAI 的 Paul Christiano、Dario Amodei、 Tom Brown 正在合作开展的一项研究的部分成果,以下是对原论文的摘要介绍:
论文:基于人类偏好的深度强化学习(Deep reinforcement learning from human preferences)
论文地址:https://arxiv.org/abs/1706.03741

要让复杂的强化学习(RL)系统与真实世界环境进行有用的交互,我们需要与这些系统交流复杂的目标(goal)。在这项工作中,我们探索了根据(非专家)人类在轨迹段对(pairs of trajectory segments)之间的偏好而定义的目标。我们表明这种方法可以在无需访问奖励函数的情况下有效地解决复杂的强化学习任务,包括 Atari 游戏和模拟的机器人运动,同时还能在少于百分之一的我们的智能体与环境的交互上提供反馈。这可以有效地降低人类监管的成本,足以使得其可被实际应用于当前最佳的强化学习系统。为了展示方法的灵活性,我们仅需大约一个小时的人类时间,就可以成功地训练好复杂的全新行为。这些行为和环境被认为比之前任何从人类反馈习得的都更为复杂。 
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]
点击阅读原文,查看机器之心官网↓↓↓









