点击上方“
蓝色字体
”,选择 “
设为星标
”
关键讯息,D1时间送达!
前言
互联网的飞速发展促进了很多新媒体的发展,不论是知名的大 V,明星还是围观群众都可以通过手机在微博,朋友圈或者点评网站上发表状态,分享自己的所见所想,使得“人人都有了麦克风”。不论是热点新闻还是娱乐八卦,传播速度远超我们的想象。可以在短短数分钟内,有数万计转发,数百万的阅读。如此海量的信息可以得到爆炸式的传播,如何能够实时的把握民情并作出对应的处理对很多企业来说都是至关重要的。大数据时代,除了媒体信息以外,商品在各类电商平台的订单量,用户的购买评论也都对后续的消费者产生很大的影响。商家的产品设计者需要汇总统计和分析各类平台的数据做为依据,决定后续的产品发展,公司的公关和市场部门也需要根据舆情作出相应的及时处理,而这一切也意味着传统的舆情系统升级成为大数据舆情采集和分析系统。
分析完舆情场景后,我们再来具体细化看下大数据舆情系统,对我们的数据存储和计算系统提出哪些需求:
我们计划分两篇介绍完整的舆情新架构,第一篇主要是提供架构设计,会先介绍时下主流的大数据计算架构,并分析一些优缺点,然后引入舆情大数据架构。第二篇会有完整的数据库表设计和部分示例代码。大家敬请期待。
系统设计
需求分析
结合文章开头对舆情系统的描述,海量大数据舆情分析系统流程图大体如下:
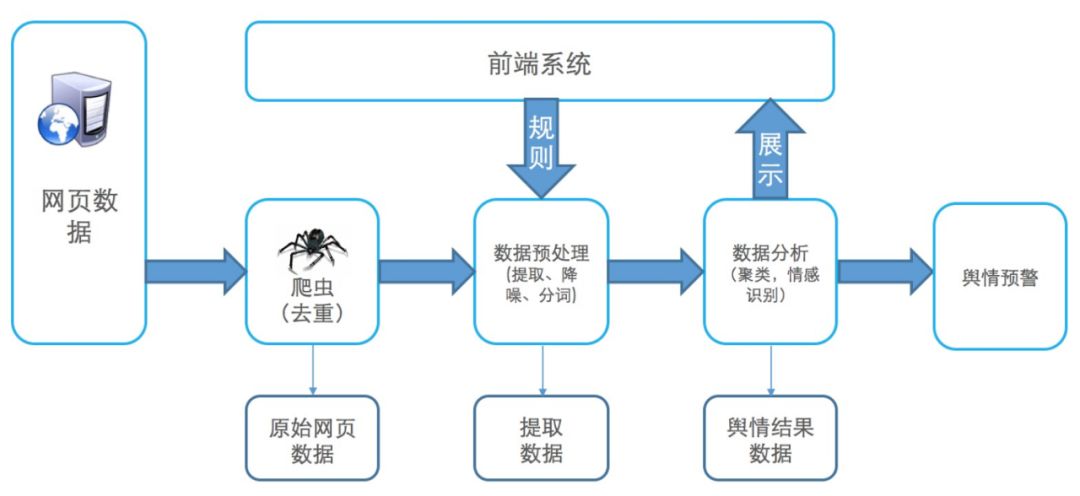
图 1 舆情系统业务流程
根据前面的介绍,舆情大数据分析系统需要两类计算,一类是实时计算包括海量网页内容实时抽取,情感词分析并进行网页舆情结果存储。另一类是离线计算,系统需要对历史数据进行回溯,结合人工标注等方式优化情感词库,对一些实时计算的结果进行矫正等。所以在系统设计上,需要选择一套既可以做实时计算又能做批量离线计算的系统。在开源大数据解决方案中,Lambda 架构恰好可以满足这些需求,下面我们来介绍下 Lambda 的架构。
Lambda 架构 (wiki)
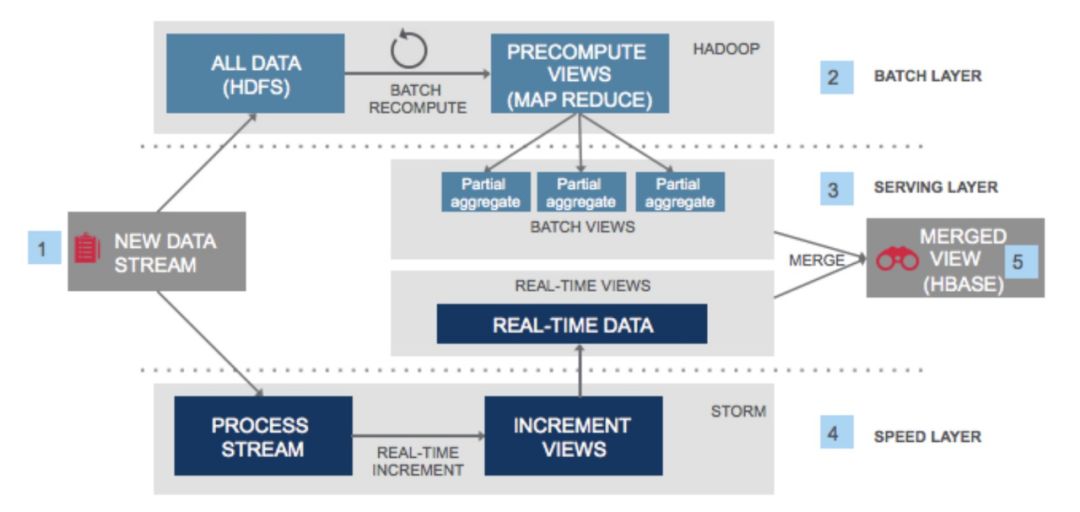
图 2 Lambda 架构图
Lambda 架构可以说是 Hadoop,Spark 体系下最火的大数据架构。这套架构的最大优势就是在支持海量数据批量计算处理(也就是离线处理)同时也支持流式的实时处理(即热数据处理)。
具体是如何实现的呢,首先上游一般是一个队列服务例如 kafka,实时存储数据的写入。kafka 队列会有两个订阅者,一个是全量数据即图片中上半部分,全量数据会被存储在类似 HDFS 这样的存储介质上。当有离线计算任务到来,计算资源(例如 Hadoop)会访问存储系统上的全量数据,进行全量批计算的处理逻辑。经过 map/reduce 环节后全量的结果会被写入一个结构化的存储引擎例如 Hbase 中,提供给业务方查询。队列的另一个消费订阅方是流计算引擎,流计算引擎往往会实时的消费队列中的数据进行计算处理,例如 Spark Streaming 实时订阅 Kafka 的数据,流计算结果也会写入一个结构化数据引擎。批量计算和流计算的结果写入的结构化存储引擎即上图标注 3 的 "Serving Layer",这一层主要提供结果数据的展示和查询。
在这套架构中,批量计算的特点是需要支持处理海量的数据,并根据业务的需求,关联一些其他业务指标进行计算。批量计算的好处是计算逻辑可以根据业务需求灵活调整,同时计算结果可以反复重算,同样的计算逻辑多次计算结果不会改变。批量计算的缺点是计算周期相对较长,很难满足实时出结果的需求,所以随着大数据计算的演进,提出了实时计算的需求。实时计算在 Lambda 架构中是通过实时数据流来实现,相比批处理,数据增量流的处理方式决定了数据往往是最近新产生的数据,也就是热数据。正因为热数据这一特点,流计算可以满足业务对计算的低延时需求,例如在舆情分析系统中,我们往往希望舆情信息可以在网页抓取下来后,分钟级别拿到计算结果,给业务方充足的时间进行舆情反馈。下面我们就来具体看一下,基于 Lambda 架构的思想如何实现一套完整的舆情大数据架构。
开源舆情大数据方案
通过这个流程图,让我们了解了整个舆情系统的建设过程中,需要经过不同的存储和计算系统。对数据的组织和查询有不同的需求。在业界基于开源的大数据系统并结合 Lambda 架构,整套系统可以设计如下:
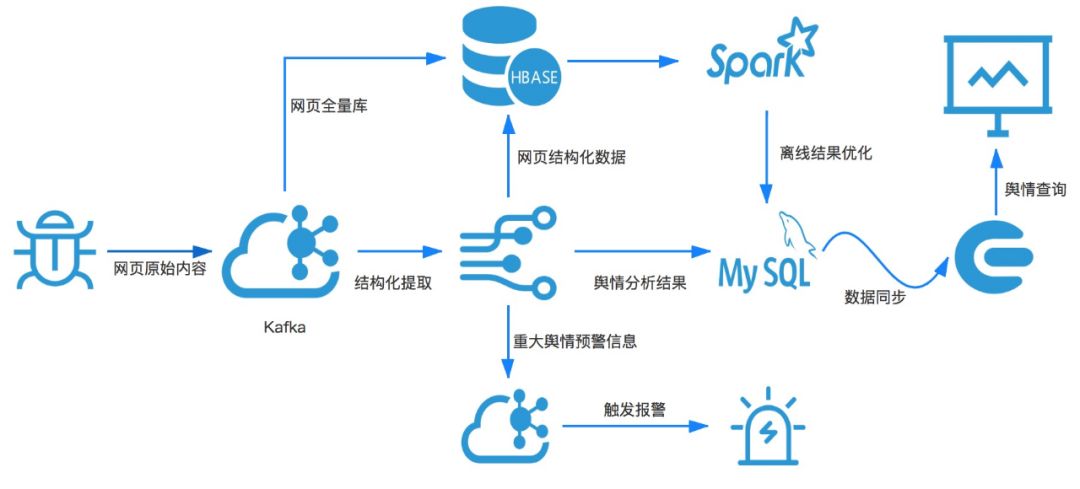
图 3 开源舆情架构图
开源架构分析
上面的舆情大数据架构,通过 Kafka 对接流计算,Hbase 对接批计算来实现 Lambda 架构中的“batch view”和“real-time view”,整套架构还是比较清晰的,可以很好的满足在线和离线两类计算需求。但是把这一套系统应用在生产并不是一件容易的事情,主要有下面一些原因。
新的大数据架构 Lambda plus
通过前面的分析,相信大家都会有一个疑问,有没有简化的的大数据架构,在可以满足 Lambda 对计算需求的假设,又能减少存储计算以及模块的个数呢。Linkedin 的 Jay Kreps 提出了 Kappa 架构,关于 Lambda 和 Kappa 的对比可以参考 " 云上大数据方案 " 这篇,这里不展开详细对比,简单说下,Kappa 为了简化两份存储,取消了全量的数据存储库,通过在 Kafka 保留更长日志,当有回溯重新计算需求到来时,重新从队列的头部开始订阅数据,再一次用流的方式处理 Kafka 队列中保存的所有数据。这样设计的好处是解决了需要维护两份存储和两套计算逻辑的痛点,美中不足的地方是队列可以保留的历史数据毕竟有限,难以做到无时间限制的回溯。分析到这里,我们沿着 Kappa 针对 Lambda 的改进思路,向前多思考一些:假如有一个存储引擎,既满足数据库可以高效的写入和随机查询,又能像队列服务,满足先进先出,是不是就可以把 Lambda 和 Kappa 架构揉合在一起,打造一个 Lambda plus 架构呢?
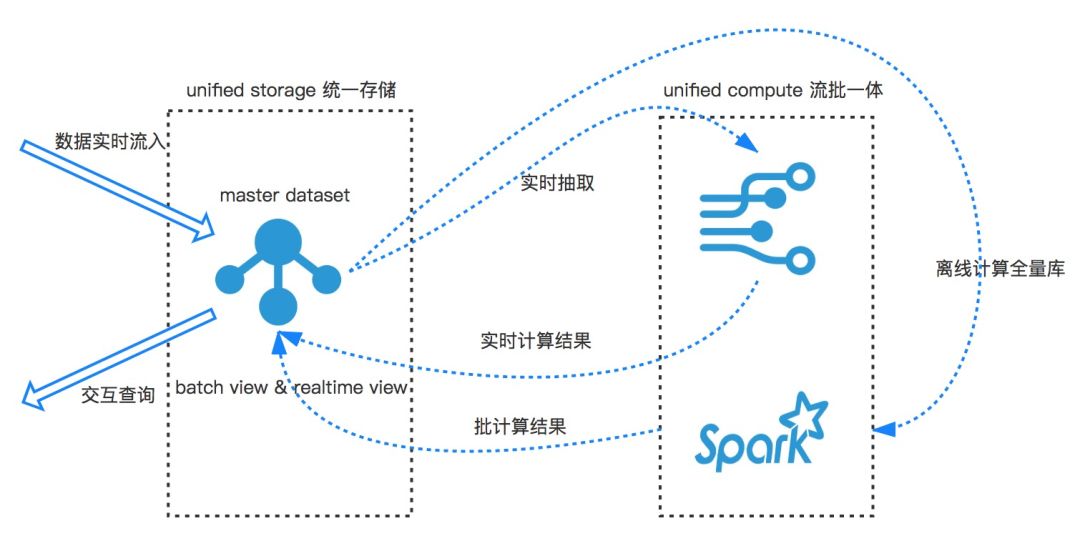
新架构在 Lambda 的基础上可以提升以下几点:
总结起来就是整套新架构的核心是解决存储的问题,以及如何灵活的对接计算。我们希望整套方案是类似下面的架构: