王小新 编译自 Hackernoon
量子位 出品 | 公众号 QbitAI
目前,生成对抗网络(GAN)作为一种处理图像生成问题的优秀方法,在超分辨率重建、风格迁移等领域已经做出了很多有意思的成就。
(比如量子位昨天推荐的去马赛克大法)
不过,GAN只会模仿怎么行?最近一项新研究改进了GAN,教机器去创造。

上面这些广受好评的画,出自美国罗格斯大学的计算机科学实验室、Facebook的人工智能研究部和查尔斯顿学院的艺术史系联合发表的新论文:CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms。
这篇论文,提出了创造性对抗网络(Creative Adversarial Networks),探究了利用机器生成来产生创意内容的可能性。
Hackernoon发文介绍了这篇论文的主要内容,量子位翻译如下:
在阅读本文前,希望你已经了解神经网络的概念及一些基本概念,如损失函数和卷积操作等。
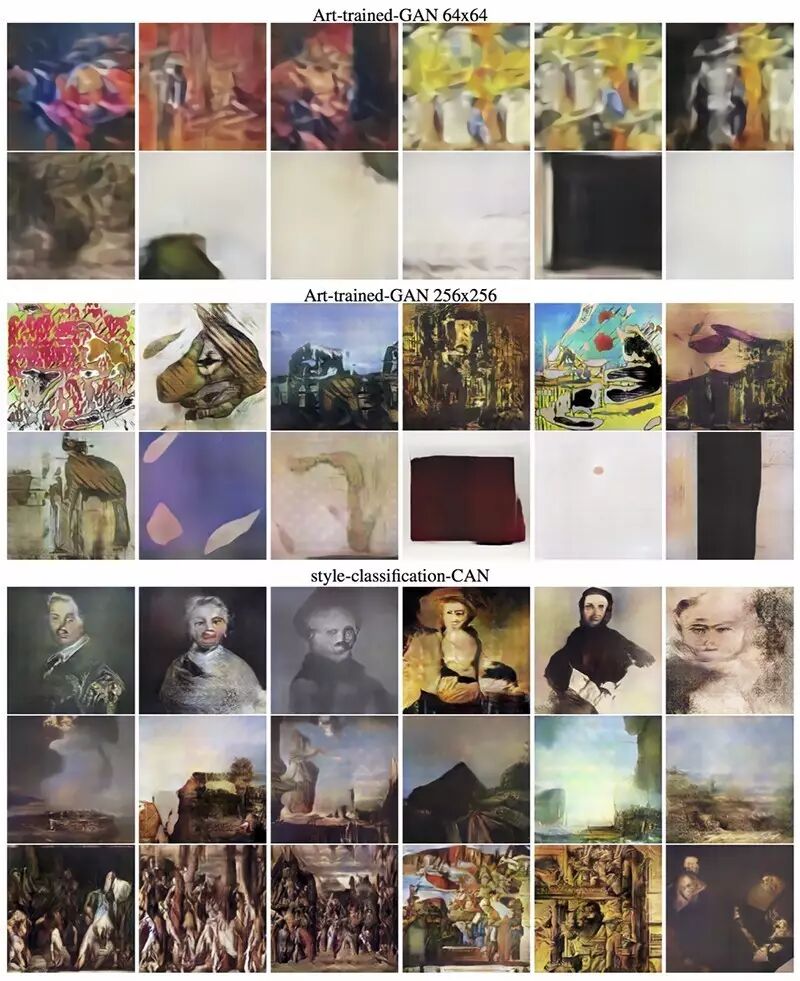
△ GAN网络和CAN网络的一些生成图像
回顾GAN网络
GAN网络是由两个相互斗争的神经网络组成,分别称为生成器和鉴别器。
与字面含义相似,生成器的作用是根据输入来生成数据,该输入可以是噪声甚至是其他类型的数据。鉴别器的作用是分析数据并区分该数据是属于原始输入数据,还是由生成器产生的生成数据。
通常来说,GAN网络可以看作是一种由生成器和鉴别器完成的对抗游戏:
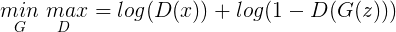
△ 方程1.0
简单版解释
如果你觉得上述方程太复杂,别担心,接下来会分步介绍这个方程,详细解释下每部分的含义。
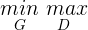
△ 方程1.1
上面是极大极小方程的符号,字母G和D分别代表了生成器Generator和鉴别器Discriminator。生成器的任务为最小化方程1.0的值,与此同时,鉴别器的任务为最大化方程1.0的值。这两者会无休止地相互竞争,直到程序作出停止的命令。
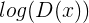
△ 方程1.2
当给定输入x为来自原始数据集的数据时,鉴别器的输出会表明这是真实的数据。
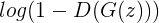
△ 方程1.3
方程1.3计算了鉴别器对生成器输入的输出值。D(G(z))表示鉴别器判断输入数据为真实数据的概率,则1- D(G(z))表示鉴别器判断输入数据为生成数据的概率。G(z)表示由生成器产生的数据。
将上述方程统一起来,得到鉴别器的任务为最大化以下方程:
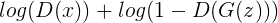
△ 方程1.4
而生成器的任务为最小化方程1.4的值,也就是最大化方程1.5的值。
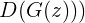
△ 方程1.5
关于GAN网络更详细的解释可以参考英属哥伦比亚大学的在线课程。
在线课程地址:http://wiki.ubc.ca/Course:CPSC522/Generative_Adversarial_Networks
从模仿到创造
生成器通过不断调整自身,使鉴别器将生成图像标记为真实图像,而鉴别器也在不断调整自身来指出生成图像和原始图像间的差异。
这不是简单的模仿吗?
在一定程度上,是这样的。生成器的目标是愚弄鉴别器,使其认为生成数据与真实数据尽可能地相似。那么是怎么实现呢?通过使相应输出与真实数据极其相似。
要让网络更具有创意性,该如何改进呢?
创造性对抗网络来了!
论文作者提出了改进后的GAN网络:CAN,来产生创意性的内容。该网络通过向生成器发送一个附加信号,以防止其产生与原始数据过于相似的内容,这该如何实现?作者在方程1.4中修改了最初的GAN网络损失函数。
CAN简单解释
在原始的GAN中,鉴别器通过判断输入数据与真实数据的相似程度得到一个输出值,生成器就是根据这个输出值来修改其权重。CAN网络可以通过以下两种方式来扩展此过程:
1. 鉴别器不仅会判断数据是真是假,而且还可以确定该艺术图像的所属年代;
2. 生成器将会接收鉴别器中附加的年代信息,并使用该指标与鉴别器的(可真可假)输入进行联合训练。
改进目的
原始GAN网络的存在问题是不会探索新的内容,训练的唯一目标只是使生成数据与真实数据集尽可能相似。
通过对输入数据所属年代进行分类的附加度量,可能会带有置信度列表,生成器可以获得其生成数据与某个年代相似程度的反馈信息。
现在,生成器不仅要使生成数据与真实数据集相似,而且还要确保其与某个类别不过于相似。这条规则将限制生成器产生带有具体特征的艺术图像。
新的损失函数定义如下:
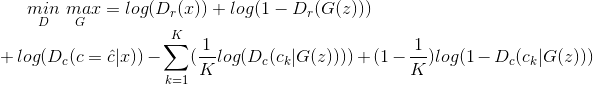
△ 方程2.0
真的很简单!
第一行与原始方程完全相同。但是要注意,下标r代表鉴别器的输出是真或是假,下标c为鉴别器分类的输出值。
第二行为提高创造性的改进点,接下来详细解释。
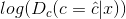
△ 方程2.1
上述公式使得鉴别器能正确获取输入图像的类别。鉴别器将会努力最大化该概率值,来正确得到输入图像的年代类别。
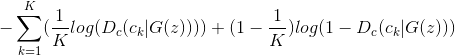
△ 方程2.2
这个方程可能看起来很复杂,但这只是定义了多标签交叉熵损失(Multi Label Cross Entropy Loss),这里的K表示图像类别的数目。在分类器中,也使用了该损失函数。生成器在训练过程中通过最小化该值来最大化方程2.0的值。
方程2.2的直观解释
方程2.2的作用是,如果某个类的得分值接近1或0,则整个方程的值接近于无穷大。
方程2.2可以取到最大值时,此时意味着鉴别器完全不确定输入图像属于哪一类,即上述方程中的计算和都相同,这也是生成器想完成的结果。
这是有一定依据的,因为如果鉴别器不可能将输入图像正确地分类到现有的某一类中,则意味着该数据与原始数据相同。
结论
本文讨论了一种能根据已有数据推进GAN网络探索新内容的损失函数,通过改进原有的损失函数来进行探索,期待更有趣的研究。
相关链接
CAN论文:
https://arxiv.org/abs/1706.07068
损失函数详细信息:
https://christopher5106.github.io/deep/learning/2016/09/16/about-loss-functions-multinomial-logistic-logarithm-cross-entropy-square-errors-euclidian-absolute-frobenius-hinge.html
【完】
一则通知
量子位正在组建自动驾驶技术群,面向研究自动驾驶相关领域的在校学生或一线工程师。李开复、王咏刚、王乃岩、王弢等大牛都在群里。欢迎大家加量子位微信(qbitbot),备注“自动驾驶”申请加入哈~
招聘
量子位正在招募编辑记者、运营、产品等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。
△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容








